







文章目录
1.超参数优化的直观理解
选定了模型之后,就有了优化超参数以得到最佳得分模型的问题。
假设有a,b,c三个参数,这三个参数都可以取1到10之间的整数。
如何找到使模型表现最好的参数组合呢?其中一种方法是对所有组合进行评估,即循环穷举的方法。
下面的代码是对超参数优化的直观理解。
best_accuracy = 0
best_parameters = {"a": 0, "b":0, "c":0}
for a in range(1, 11):
for b in range(1, 11):
for c in range(1, 11):
model = MODEL(a, b, c)
model.fit(train_data)
preds = model.predict(validation_data)
accuracy = metrics.accuracy_score(targets, preds)
if accuracy > best_accuracy:
best_accuracy = accuracy
best_parameters["a"] = a
best_parameters["b"] = b
best_parameters["c"] = c
这个例子我们需要对模型进行(10x10x10)次拟合,计算量可能会很大。现实世界中,并不只有三个参数,每个参数也不是只有10个值。大多数模型的参数都是实数,不同的参数组合可以是无限的。
2.网格搜索(GridSearch)
让我们看看sklearn的随机森林模型。
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(
n_estimators=100,
criterion='gini',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
bootstrap=True,
oob_score=False,
n_jobs=None,
random_state=None,
verbose=0,
warm_start=False,
class_weight=None,
ccp_alpha=0.0,
max_samples=None
)
这个模型总共有19个参数,所有这些参数的所有组合,以及它们可以承担的所有值,都将是无穷无尽的。通常情况下,我们没有足够的资源和时间来做这件事。所以,我们指定了一个参数网格,在这个网格上寻找最佳参数组合的搜索成为网格搜索。我们可以说n_estimators可以是100、200、250、300、400、500;max_depth可以是1、2、5、7、11、15;criterion可以是gini或entropy。这些参数看起来并不多,但如果数据集很大,计算起来会耗费大量时间。
我们可以像之前一样创建三个for循环,并在验证集上计算得分,这样就能实现网格搜索。还必须注意的是,如果要进行k折交叉验证,则需要更多的循环,意味着需要更多的时间来找到完美的参数。因此,网格搜索并不流行。
下面以根据手机配置预测手机价格范围(分类)数据集为例,看看它是如何实现的。
训练集中只有2000个样本。我们可以轻松地使用分层kfold和准确率作为评估指标。我们将使用上述参数范围的随机森林,在下面的示例中了解如何进行网格搜索。
import pandas as pd
from sklearn import ensemble
from sklearn import metrics
from sklearn import model_selection
if __name__ == "__main__":
# 获取训练数据
df = pd.read_csv("../input/mobile_train.csv")
X = df.drop("price_range", axis=1).values
y = df.price_range.values
# 定义学习器
classifier = ensemble.RandomForestClassifier(n_jobs=-1)
# 定义需要进行网格搜索的参数
param_grid = {
"n_estimators": [100, 200, 250, 300, 400, 500],
"max_depth": [1, 2, 5, 7, 11, 15],
"criterion": ["gini", "entropy"]
}
# 定义网格搜索模型
model = model_selection.GridSearchCV(
estimator=classifier,
param_grid=param_grid,
scoring="accuracy",
verbose=10,
n_jobs=1,
cv=5
)
# 拟合模型
model.fit(X, y)
# 打印模型最佳分数和最优参数
print(f"Best score: {model.best_score_}")
print("Best parameters set:")
best_parameters = model.best_estimator_.get_params()
for param_name in sorted(param_grid.keys()):
print(f"\t{param_name}: {best_parameters[param_name]}")
我们可以看到,5折交叉验证最佳得分是0.889,网格搜索得到了最佳参数。
3.随机搜索(Randomized Search)
我们可以使用的下一个最佳方法是随机搜索。在随机搜索中,我们随机选择一个参数组合,然后计算交叉验证得分。这种方法消耗的时间比网格搜索少,因为不对所有不同的参数组合进行评估。我们选择要对模型进行多少次评估,决定了搜索所需的时间。如果迭代次数少,随机搜索比网格搜索速度快。
代码与上面差别不大,除GridSearchCV外,使用RandomizedSearchCV。
if __name__ == "__main__":
# 获取训练数据
df = pd.read_csv("../input/mobile_train.csv")
X = df.drop("price_range", axis=1).values
y = df.price_range.values
# 定义学习器
classifier = ensemble.RandomForestClassifier(n_jobs=-1)
# 定义需要进行网格搜索的参数
param_grid = {
"n_estimators": np.arange(100, 1500, 100),
"max_depth": np.arange(1, 31),
"criterion": ["gini", "entropy"]
}
# 定义网格搜索模型
model = model_selection.RandomizedSearchCV(
estimator=classifier,
param_distributions=param_grid,
n_iter=20,
scoring="accuracy",
verbose=10,
n_jobs=1,
cv=5
)
# 拟合模型
model.fit(X, y)
# 打印模型最佳分数和最优参数
print(f"Best score: {model.best_score_}")
print("Best parameters set:")
best_parameters = model.best_estimator_.get_params()
for param_name in sorted(param_grid.keys()):
print(f"\t{param_name}: {best_parameters[param_name]}")
4.使用管道的方法
(这个例子涉及到文本处理和SVD,没有学过这个内容,等到以后有学习再整理)
5.高斯过程用于超参数优化
接下来让我们看看高斯过程如何用于超参数优化。这类算法需要一个可以优化的函数。
大多数情况下,都是最小化这个函数,就像我们最小化损失一样。
比方说,我们想要找到最佳参数以获得最佳准确度。我们的目的是获得最高的准确度,可以通过最小化准确度的相反数来实现。因为最小化准确度的相反数实际上就等同于最大化准确度。
这个过程可以通过scikit-optimize(skopt)库中的gp_minimize函数来实现。下面看看
如何使用该函数调整随机森林模型的参数。
import numpy as np
import pandas as pd
from functools import partial
from sklearn import ensemble
from sklearn import metrics
from sklearn import model_selection
from skopt import gp_minimize
from skopt import space
def optimize(params, param_names, x, y):
params = dict(zip(param_names, params))
model = ensemble.RandomForestClassifier(**params)
kf = model_selection.StratifiedKFold(n_splits=5)
accuracies = []
for idx in kf.split(X=x, y=y):
train_idx, test_idx = idx[0], idx[1]
xtrain = x[train_idx]
ytrain = y[train_idx]
xtest = x[test_idx]
ytest = y[test_idx]
model.fit(xtrain, ytrain)
preds = model.predict(xtest)
fold_accuracy = metrics.accuracy_score(ytest, preds)
accuracies.append(fold_accuracy)
return -1 * np.mean(accuracies)
if __name__ == '__main__':
df = pd.read_csv("../input/mobile_train.csv")
X = df.drop("price_range", axis=1).values
y = df.price_range.values
param_space = [
space.Integer(3, 15, name="max_depth"),
space.Integer(100, 1500, name="n_estimators"),
space.Categorical(["gini", "entropy"], name="criterion"),
space.Real(0.01, 1, prior="uniform", name="max_features")
]
param_names = [
"max_depth",
"n_estimators",
"criterion",
"max_features"
]
optimization_function = partial(
optimize,
param_names=param_names,
x=X,
y=y
)
result = gp_minimize(
optimization_function,
n_calls=15,
n_random_starts=10,
verbose=10
)
best_params = dict(
zip(
param_names,
result.clearx
)
)
print(best_params)
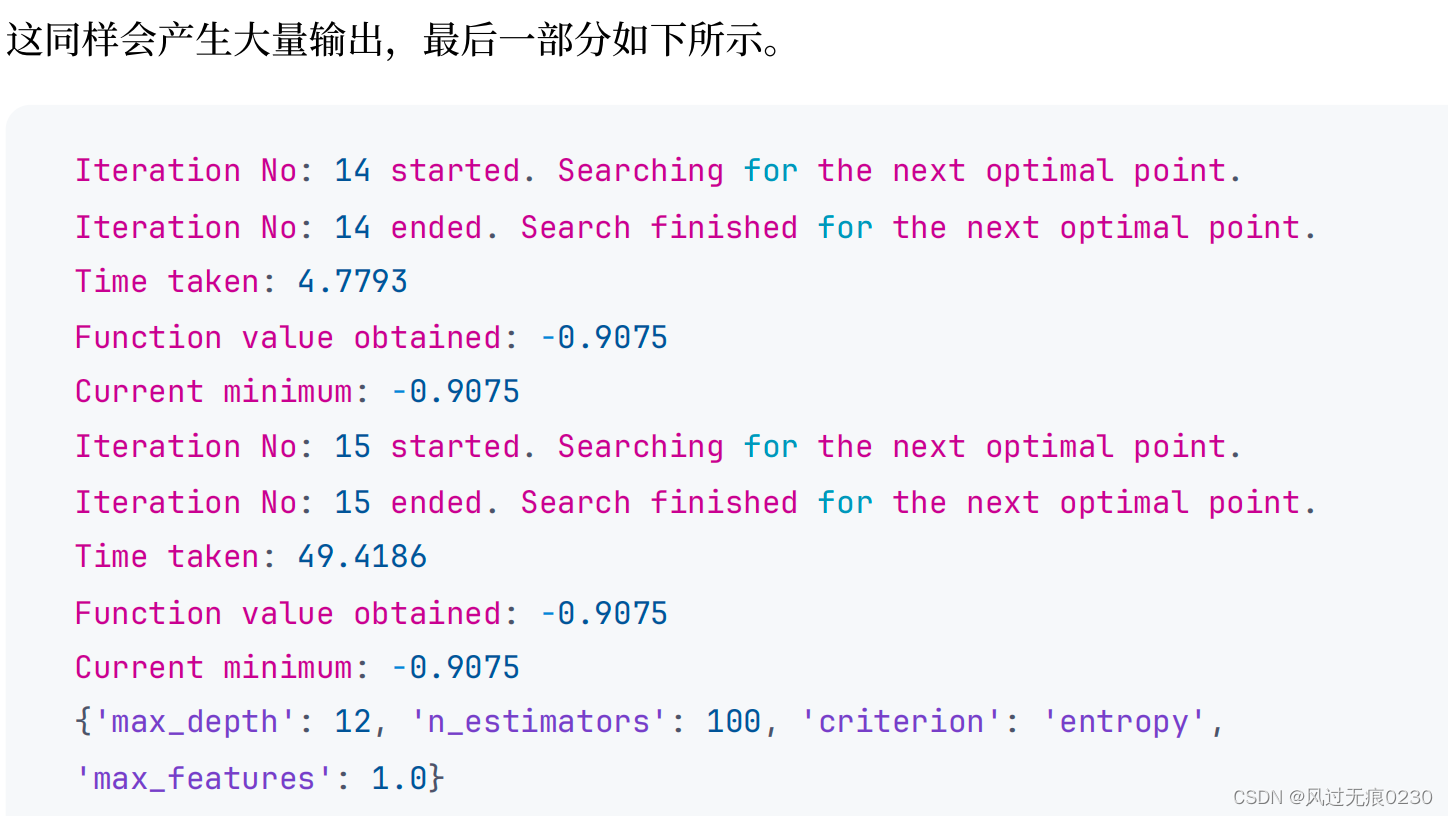
可以通过下面的代码来绘制我们是如何实现收敛的。
from skopt.plots import plot_convergence
plot_convergence(result)
6.hyperopt用于超参数优化
有很多库可以用来做超参数优化,skopt是其中一个。
另一个可以用来做超参数优化的库是hyperopt。它使用树结构帕岑估计器(TPE)来找到最优参数。
下面的代码在上一段代码基础上做最小的变化来使用hyperopt。
import numpy as np
import pandas as pd
from functools import partial
from sklearn import ensemble
from sklearn import metrics
from sklearn import model_selection
from hyperopt import hp, fmin, tpe, Trials
from hyperopt.pyll.base import scope
def optimize(params, x, y):
model = ensemble.RandomForestClassifier(**params)
kf = model_selection.StratifiedKFold(n_splits=5)
...
return -1 * np.mean(accuracies)
if __name__ == '__main__':
df = pd.read_csv("../input/mobile_train.csv")
X = df.drop("price_range", axis=1).values
y = df.price_range.values
param_space = {
"max_depth": scope.int(hp.quniform("max_depth", 1, 15, 1)),
"n_estimators": scope.int(
hp.quniform("n_estimators", 100, 1500, 1)
),
"criterion": hp.choice("criterion", ["gini", "entropy"]),
"max_features": hp.uniform("max_features", 0, 1)
}
optimization_function = partial(
optimize,
x=X,
y=y
)
trials = Trials()
hopt = fmin(
fn=optimization_function,
space=param_space,
algo=tpe.suggest,
max_evals=15,
trials=trials
)
print(hopt)
正如你所看到的,这与之前的代码并无太大区别。你必须以不同的格式定义参数空间,还需要改动实际优化的部分,用hyperopt代替gp_minimize,结果相当不错。我们得到了比以前更好的准确度和一组可以使用的参数。
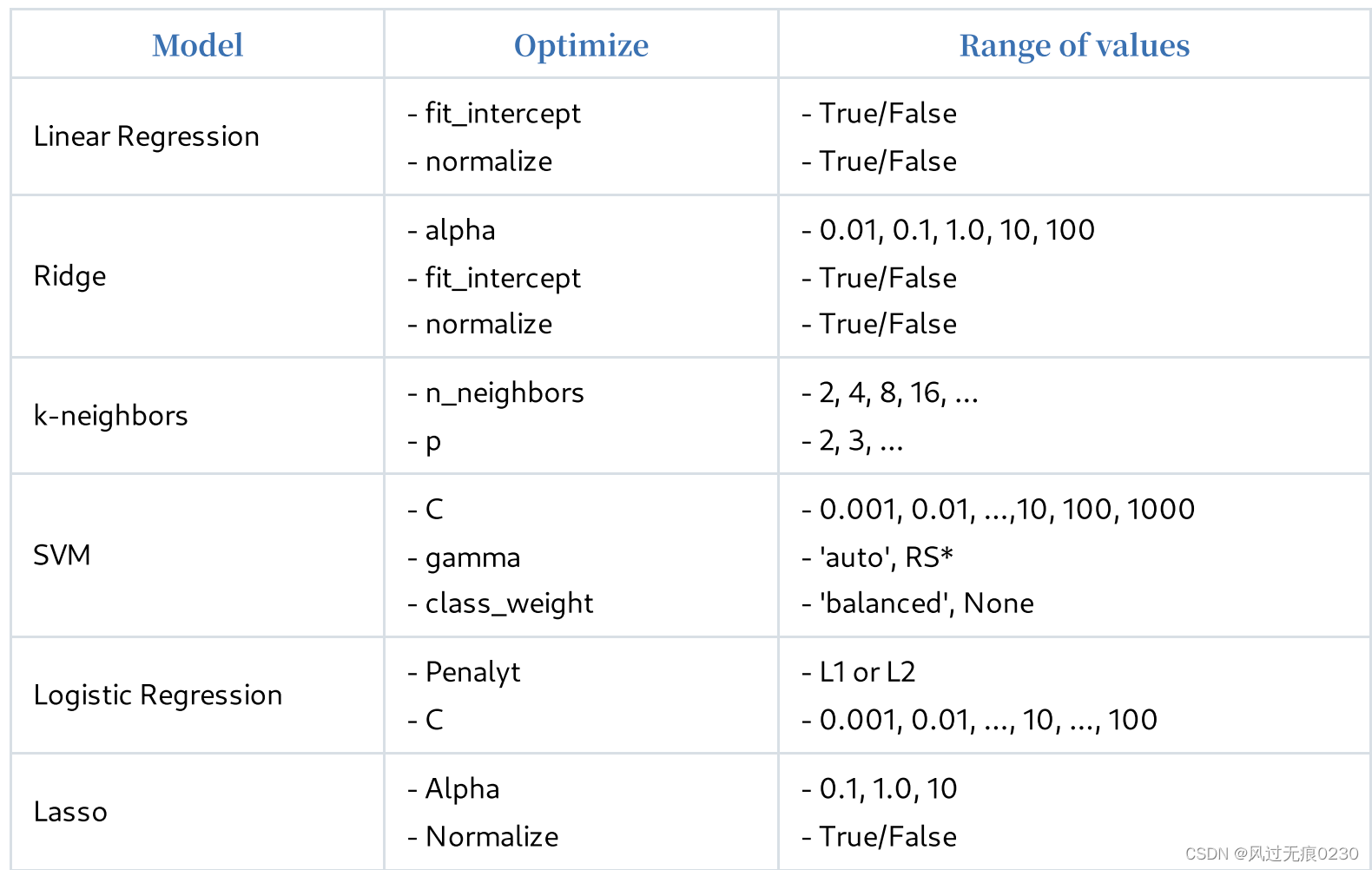
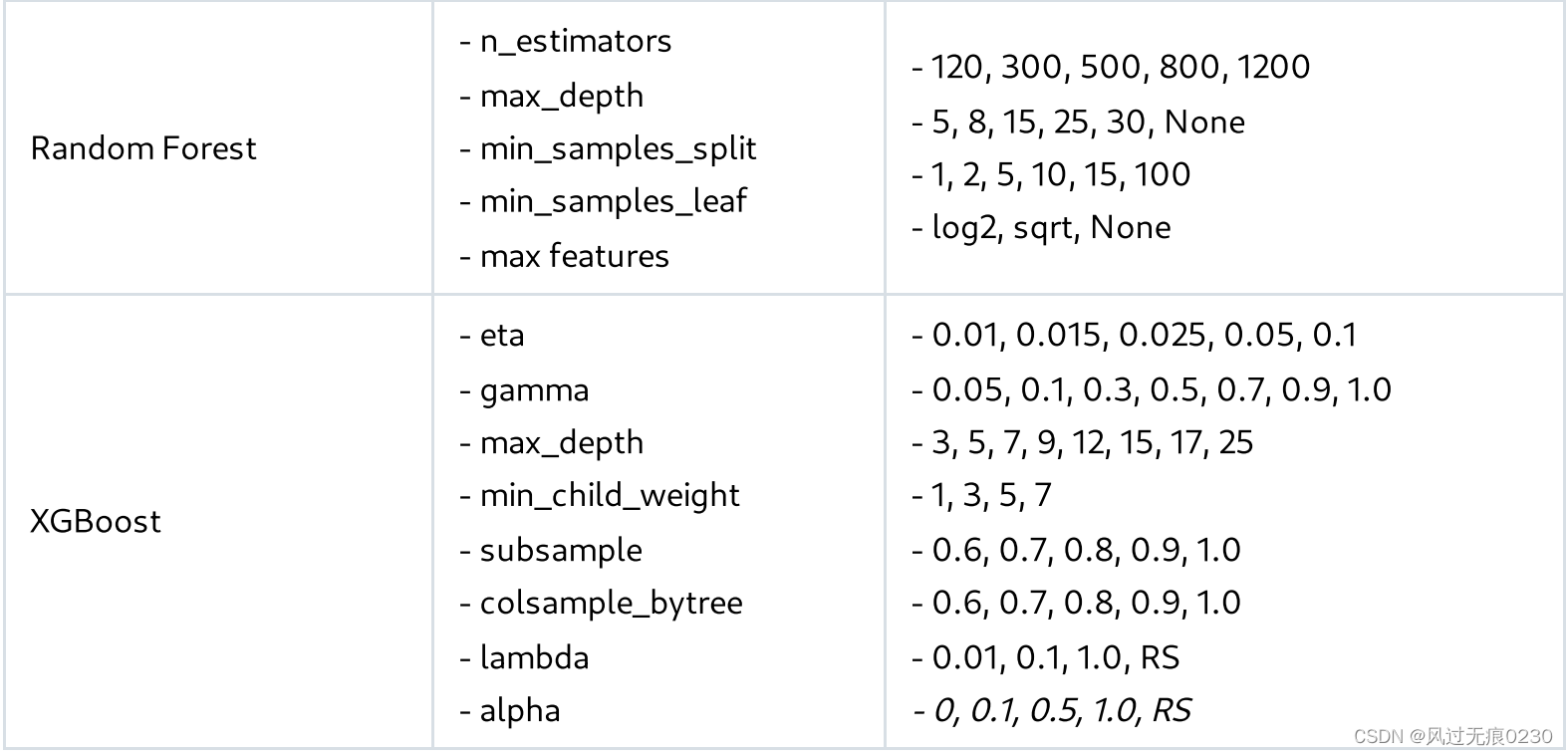
可以参考下表,了解如何调整。RS*表示随机搜索应该更好。
7.总结
上述调整超参数的方法是最常见的,几乎适用于所有模型:线性回归、逻辑回归、基于树的方法、梯度提升模型(如xgboost、lightgbm),甚至是神经网络。
虽然这些方法已经存在,但学习时必须从手动调整超参数开始,即手工调整。手工调整可以帮助你学习基础知识,例如,在梯度提升中,当你增加深度时,你应该降低学习率。如果使用自动工具,就无法学习到这一点。
一旦你能更好地手动调整参数,你甚至可能不需要任何自动超参数调整。创建大型模型或引入大量特征时,容易造成过拟合。为避免过度拟合,需要在训练数据特征中引入噪声或对代价函数进行惩罚。这种惩罚称为正则化。比如在神经网络中,可以使用dropout、添加增强、噪声等方法对模型进行正则化。














 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









