







一、CNN基础构件
输入
一般为黑白(一个channel)或者彩色(三个channel)的图片,下面假设输入为三个通道。
卷积层
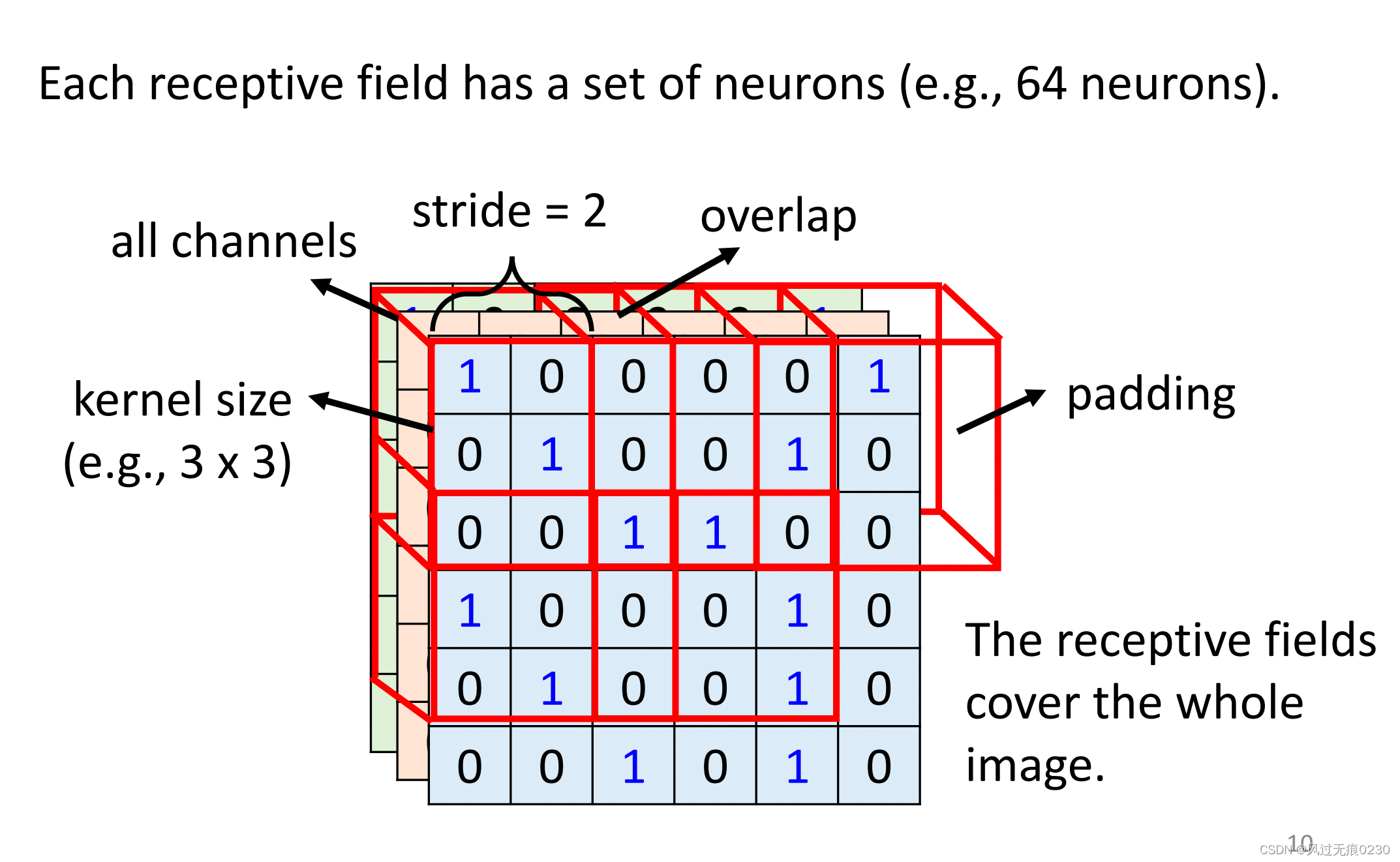
- receptive field:感受野,对应图片某个位置的模式(pattern)
- filter:滤波器,模式提取
- kernel size:人为设定的滤波器大小
- stride:滤波器每次移动的步长
- padding:边缘填充0的长度
- channel:输入的深度(depth)
卷积层对当前输入进行模式提取,产生的tensor继续传到下一层。一个卷积层可以有多个滤波器对不同的模式进行提取,滤波器的个数决定了下层输入的channel数。滤波器的参数由梯度下降计算产生。
池化层
类似将图片缩小不会改变图片表示的对象这个原理,池化层将输入进行缩小,可以减少后面训练的计算量,一般接在卷积层后面。最常用的做法是最大池化。
但池化也会伤害模型的表现,再加上计算能力的大幅提升,近年来很多模型都倾向于不使用池化层。
完整的CNN结构

二、模型的训练
-
CNN常见模型选择
链接: https://pytorch.org/vision/stable/models.html -
常用的数据增强(Augmentation)方法
链接: https://pytorch.org/vision/stable/transforms.html
也常会对测试数据进行增强 -
交叉验证(Cross Validation)和集成(Ensemble)可以提高模型的表现
-
使用残差区块(residual block)可以提高模型的性能,这种方法在增加模型层数的同时,也不会因为梯度消失的原因损害模型的性能,因为它可以模拟出输出完全等于输入的函数














 5690
5690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









