







纵观整个模型训练流程,图片素材准备和打标环节占据的分量比重,绝对超过60%。
上一篇分享了图片素材准备,这一篇,开始对准备好的图片素材进行处理了。
素材处理
我已经收集了 霉霉 的25张图片:
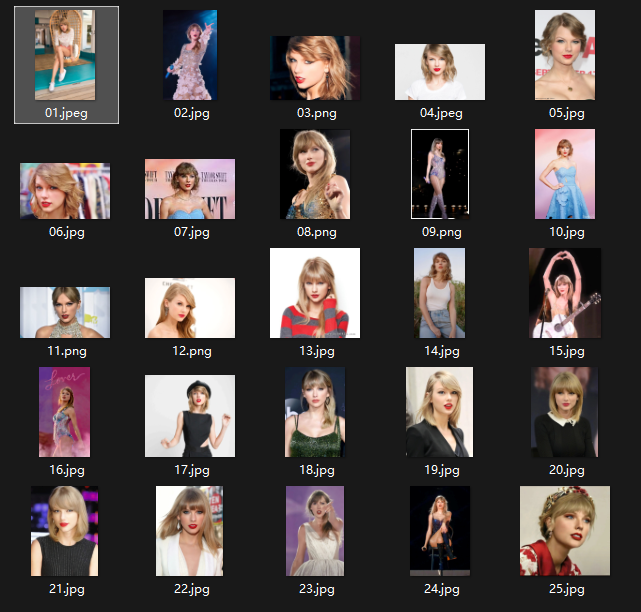
但是,发现一个问题,图片的长宽比例没有统一。
我们来到:https://www.birme.net/ 对图片进行裁剪。
上传准备好的图片:
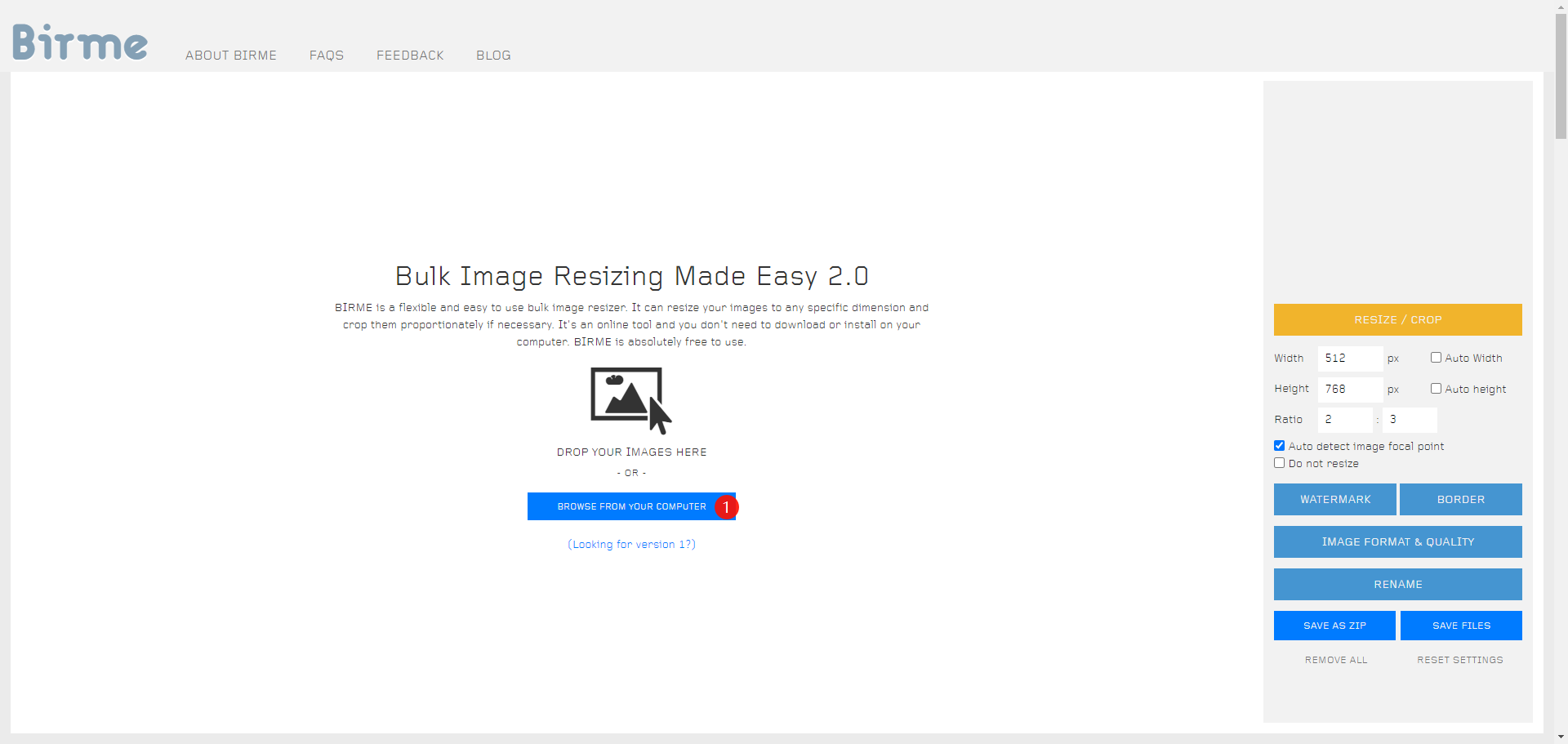
手动调整需要裁剪的范围:

调整后,点击下载压缩包:

得到宽高比例一致的图片素材:

素材打标
打标可使用的工具,较为推荐的是「朱尼酱」和一众热心用户共同开发的开源炼丹软件-cybertronfurnace1.4(仅限Windows系统使用)
下载地址:https://pan.quark.cn/s/7160111f893a#/list/share
玩车下载后解压缩,双击 cybertronfurnace1.4\cfurnace_ui\Cybertron Furnace.exe 即可启动。

第一次启动需要加载一些软件必须的部件,加载完毕后,就可以开始炼丹了:

填写触发词:1woman, Taylor_Swift,再把上一步裁剪好的素材上传:

在上传素材页面,因为图片已经裁剪好,分辨率选择 512*512,模式选择 无需裁剪,TAG 保持默认的 0.35:
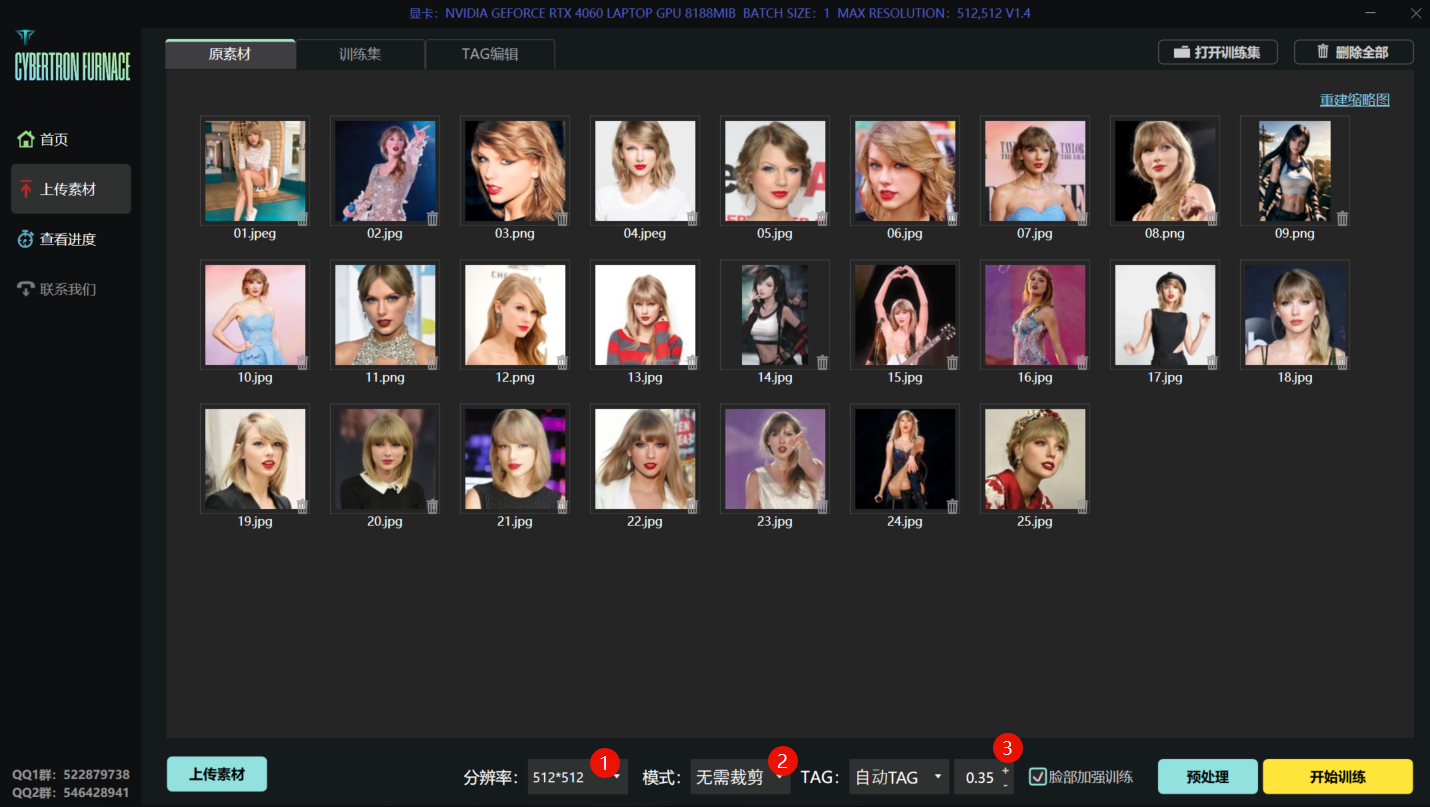
TAG(打标阈值)推荐0.35以上,
阈值过小:会生成冗余的提示词
阈值过大:提示词很少
点击「预处理」,软件就会自动在后台对图片进行裁剪和打标处理:

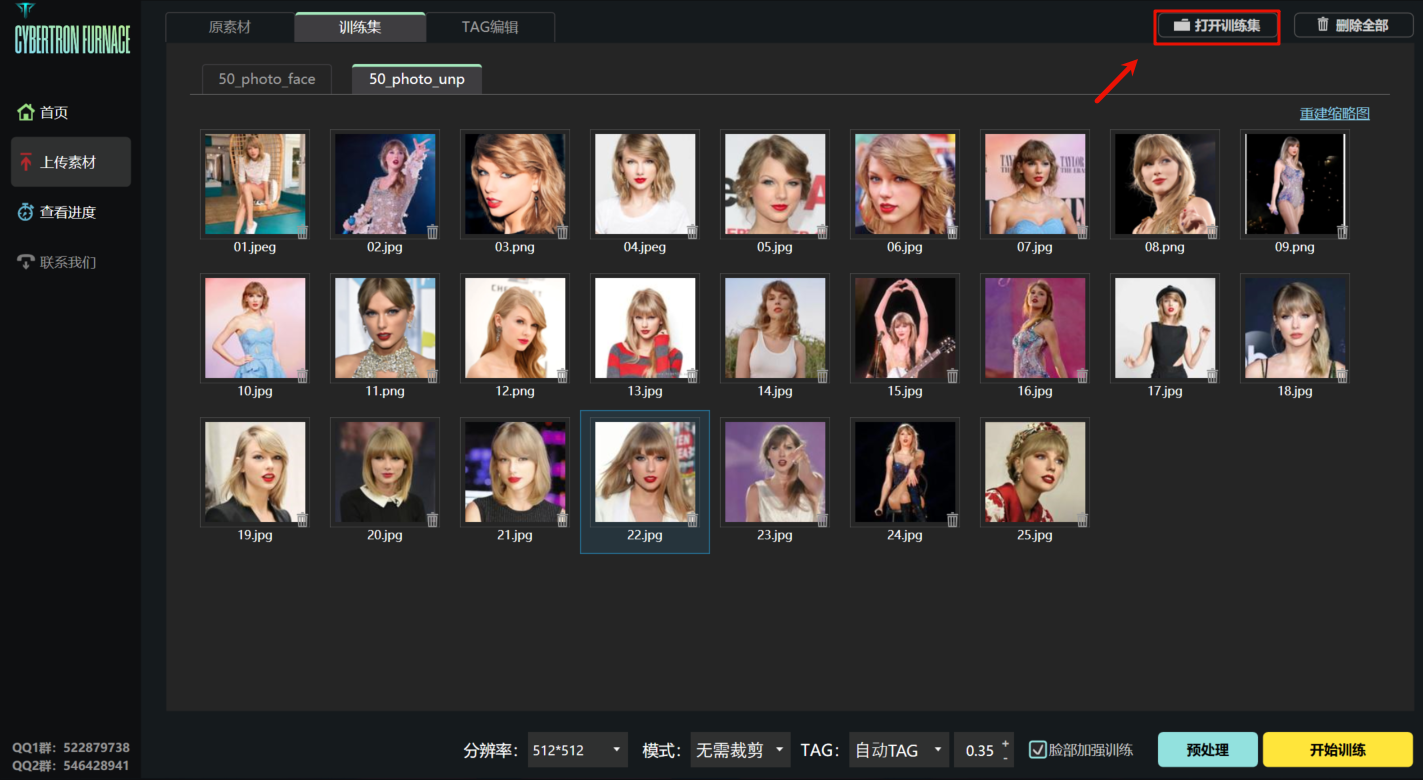
训练结束后,打开「训练集」会有2个文件夹(勾选了「脸部加强训练」):
- 专门脸部特写的图片
- 正常裁剪的图片
接着,点击「打开训练集」:
就能看到已经完成预处理的训练集文件夹:
来到以下的文件夹中,就能看到图片以及对应的打标文件:


今天先分享到这里~
开启实践:SD绘画 | 为你所做的学习过滤
















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











