






目录
1.Ai大模型使用感悟
大模型 api 调用
import openai
client = openai.OpenAI(api_key="······",
base_url="······")
response = client.chat.completions.create(model="yi", messages = [
{
"role": "user",
"content": "你是谁"
}
])
print(response.choices[0].message.content)api_key,base_url由学校提供,此处隐去
client.chat.completions.create()
以一系列消息作为输入,并将模型生成的消息作为输出,这段代码就是我们和ai交流的核心,这里model=‘调用模型名’(baichuan2/yi),message就是我们给ai发信息的内容,message是一个列表,装着很多个字典,每一个字典就是一次发送的信息,‘role’我们可以选择:
- 系统(system) 消息有助于设置助手的行为。在上面的例子中,助手被指示 “你是一个得力的助手”。
- 用户(user) 消息有助于指导助手。 就是用户说的话,向助手提的问题。
- 助手(assistant) 消息有助于存储先前的回复。这是为了持续对话,提供会话的上下文。
"content"字段就是内容。
然后我们在看看这个response长什么样子,
print(response)
ChatCompletion(id='---', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='巴黎是一个充满魅力和历史的城市,这里有无数的景点和活动。以下是一些建议,帮助您规划一个愉快的巴黎之旅:\n\n1. 参观经典地标:不要错过埃菲尔铁塔、凯旋门、卢浮宫和凡尔赛宫等著名景点。提前在网上预订门票,以避免排队。\n\n2. 探索艺术世界:巴黎拥有众多博物馆和画廊,包括奥塞美术馆和蓬皮杜中心。如果您对艺术感兴趣,可以安排专门的时间来欣赏这些作品。\n\n3. 漫步城市:巴黎的许多美丽景色都隐藏在城市的街道和小巷中。尝试步行或骑自行车游览,这样可以更接近当地人的生活方式。\n\n4. 体验法式美食:品尝当地的面包、奶酪和葡萄酒,不要错过街边的小吃摊贩,那里可以找到正宗的法式美食。\n\n5. 购物:巴黎是时尚之都,从高级时装到平价品牌,这里有各式各样的购物选择。香榭丽舍大街和蒙马特地区都是不错的购物地点。\n\n6. 了解历史:参观巴黎的地下墓穴、圣母院大教堂和协和广场等地方,这些地方见证了巴黎的悠久历史。\n\n7. 享受户外空间:巴黎有许多公园和花园,如卢森堡公园和杜乐丽花园,是放松身心的好去处。\n\n8. 晚上娱乐:巴黎的夜生活丰富多彩,从歌舞表演到现场音乐,总有适合您的东西。预订一场歌剧或音乐会,体验法式浪漫。\n\n9. 注意安全:在旅游景点和人多的地方要小心扒手,避免在夜间独自走在僻静的街道上。\n\n10. 规划行程:提前了解巴黎的交通系统,包括地铁、公交和出租车。购买一张Paris Pass或其他博物馆通行证,可以节省排队的时间。\n\n希望这些建议对您有所帮助!祝您在巴黎有一个美好的旅程。', role='assistant', function_call=None, tool_calls=None))], created=1709128837, model='ollama/yi:34b-chat', object='chat.completion', system_fingerprint=None, usage=CompletionUsage(completion_tokens=423, prompt_tokens=32, total_tokens=455))
我们发现我们需要的内容在response的choise,choise列表中的Choise作为第一个故是choise[0],然后我们再取message下content中,便可以拿出ai回复给我们的文本了。
星火api调用
我们在星火模型下申请试用资格
讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞 (xfyun.cn)
找到密钥等信息后访问星火认知大模型Web API文档 | 讯飞开放平台文档中心 (xfyun.cn)下载示例

SparkApi.py这个文件就是关键了,我们调用的时候用
import SparkApi
最好保证这个文件与项目在同一个文件夹
text =[]
def getText(role,content):
jsoncon = {}
jsoncon["role"] = role
jsoncon["content"] = content
text.append(jsoncon)
return text
def getlength(text):
length = 0
for content in text:
temp = content["content"]
leng = len(temp)
length += leng
return length
def checklen(text):
while (getlength(text) > 8000):
del text[0]
return text这几个是test文件中比较关键的几个函数,我们使用它们来获得模型的回复,text就相当于是上文的message,getText获得角色(role),内容(content),打包为字典jsoncon,合并到text中,checklen就是防止文本过多实现自动删除
if __name__ == '__main__':
text.clear
while(1):
Input = input("\n" +"我:")
question = checklen(getText("user",Input))
SparkApi.answer =""
print("星火:",end = "")
SparkApi.main(appid,api_key,api_secret,Spark_url,domain,question)
getText("assistant",SparkApi.answer)
print(str(text))使用SparkApi.main(appid,api_key,api_secret,Spark_url,domain,question),便可得到回复SparkApi.answer,最后getText是把模型的回复也加入对话之中(保存历史)
stable_diffusion webui 本地部署
本人采用本地部署stabledifusion,并未采用学校提供的云端页面,主要是自己部署能更加方便,专业,当时并未尝试是否可以通过api调用sd,线上部署不允许采用api调用(?)。requests.exceptions.ConnectionError: HTTPConnectionPool(host='127.0.0.1', port=7860): Max retries exceeded with url: /sdapi/v1/txt2img (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x000001EB7FDC9150>: Failed to establish a new connection: [WinError 10061] 由于目标计算机积极拒绝,无法连接。'))
下方是sd-webui界面
采用秋葉aaaki的个人空间-秋葉aaaki个人主页-哔哩哔哩视频 (bilibili.com) 秋叶大佬的整合包【AI绘画·24年1月最新】Stable Diffusion整合包v4.6发布!解压即用 防爆显存 三分钟入门AI绘画 ☆更新 ☆训练 ☆汉化 秋叶整合包_哔哩哔哩_bilibili
下载完成并且解压后,首先运行运行依赖
![]() 启动后,打开设置转换为中文界面,界面本地部署的webui可以自由的下载sd模型和lora等模型。位置
启动后,打开设置转换为中文界面,界面本地部署的webui可以自由的下载sd模型和lora等模型。位置
Lora:安装目录\sd-webui-aki-v4.6\models\Lora
大模型:安装目录\sd-webui-aki-v4.6\models\Stable-diffusion
stable_diffusion webui api 调用
我们先本地运行sd。打开绘世,点击运行。等待一会,会自动进入ui界面
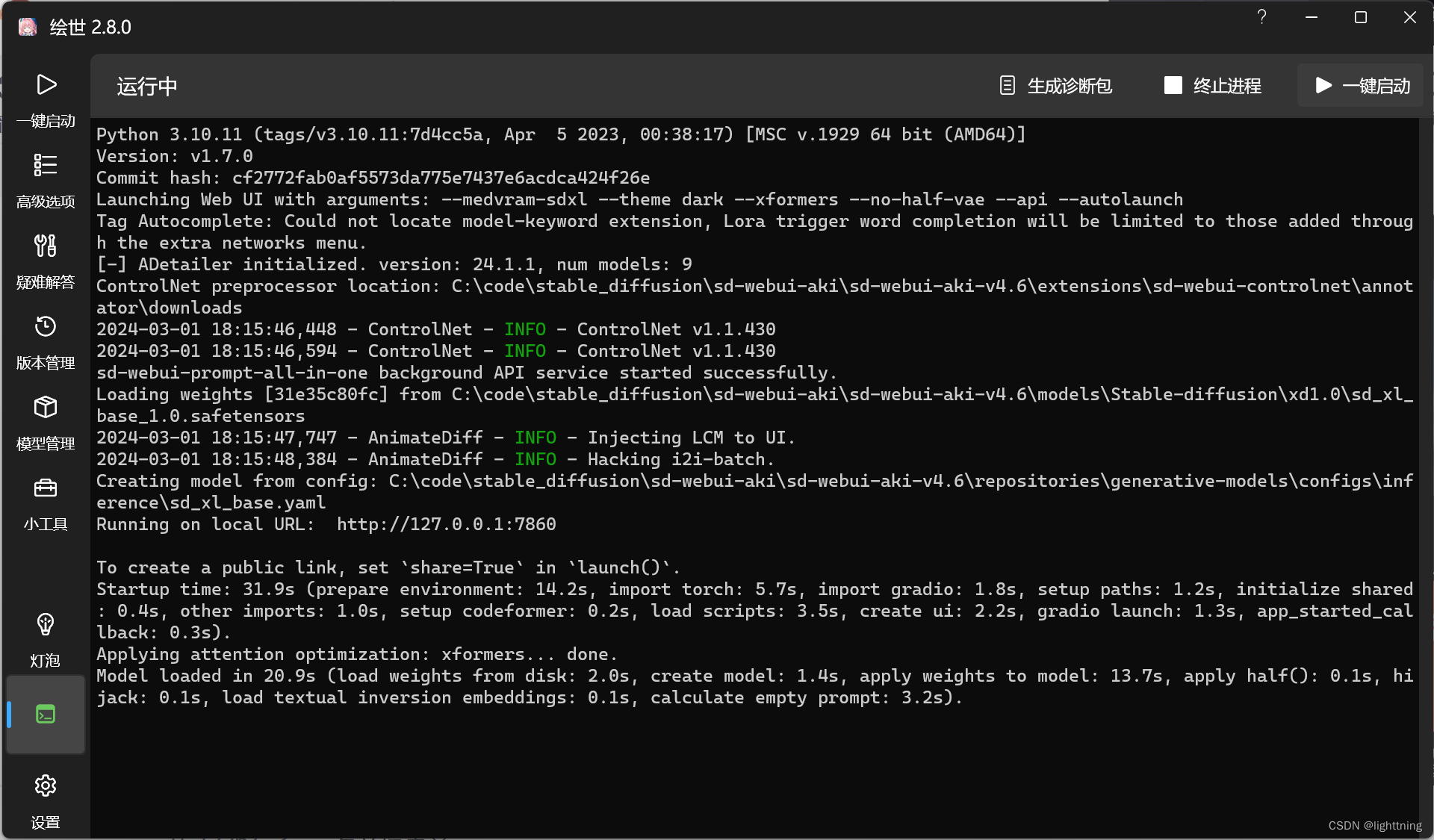
这个界面就是成功启动了。在窗口中找到网址:http://127.0.0.1:7860这个就是我们要填入的url。
import base64
import io
import requests
from PIL import Image
txt2imge_date={
"denoising_strength": 0,
"prompt": "puppy dogs", //提示词
"negative_prompt": "", //反向提示词
"seed": -1, //种子,随机数
"batch_size": 2, //每次张数
"n_iter": 1, //生成批次
"steps": 50, //生成步数
"cfg_scale": 7, //关键词相关性
"width": 512, //宽度
"height": 512, //高度
"restore_faces": false, //脸部修复
"tiling": false, //可平埔
"override_settings": {
"sd_model_checkpoint" :"wlop-any.ckpt [7331f3bc87]"
"sd_vae":"orangemix.vae.pt"
}, // 一般用于修改本次的生成图片的stable diffusion 模型,用法需保持一致
"script_args": [
0,
true,
true,
"LoRA",
"dingzhenlora_v1(fa7c1732cc95)",
1,
1
], // 一般用于lora模型或其他插件参数,如示例,我放入了一个lora模型, 1,1为两个权重值,一般只用到前面的权重值1
"sampler_index": "Euler" //采样方法
"enable_hr": False, //下面是高清修复模块
"denoising_strength": 0.5,
"hr_scale": 2,
"hr_upscaler": "Latent",
}
response=requests.post(url=f'{url}/sdapi/v1/txt2img',json=txt2imge_date)
image=Image.open(io.BytesIO(base64.b64decode(response.json()['images'][0])))调用分为两个部分,第一个是用requests.post请求向服务器发送请求,等待运行后服务器会发回来数据,但是这些数据并没有转换成图片,所以我们最后一行就是在解码这些数据,Image就是专门用来处理图像的库,我们先把response以json解读,选其中['images'][0](很好理解,我们可以设置出多张图片,如果要全部输出这里应该用循环)所以经过这段代码,图片便被python读取到image中了,下面两段代码,第一个是打开图片,下一个是将图片保存到file_path(要注意,保存要带后缀,eg:绝对(相对)路径/名字.jpg)
image.show
image.save(file_path)2.实践过程:尝试采用ai实现儿童绘本创作
思路和代码实现
以下代码改编自课堂演示代码Law_Agent,思路:使用大模型生成按照一定格式童话故事,然后通过处理修改故事结构,再次输入大模型来构造提示词工程,然后带入sd的api调用,生成图片。
import openai
import requests
import base64
from PIL import Image
import io
class aistory:
def __init__(self, api_key="----", model_name="yi"):
self.client = openai.OpenAI(api_key=api_key, base_url="----")
# self.client = openai.OpenAI(api_key=api_key)
self.model_name = model_name # baichuan2/yi
self.story=''
self.history = []
self.story_struct=[]
openai.api_key = api_key
def get_llm_response(self, prompt, system_prompt=None, with_history=False,assistant_prompt=None,pre_userpropmt=None): # LLM生成回复
messages = []
if system_prompt is not None:
messages.append({"role": "system", "content": system_prompt})
if pre_userpropmt is not None:
messages.append({"role": "user", "content": pre_userpropmt})
if assistant_prompt is not None:
messages.append({"role": "system", "content": assistant_prompt})
if with_history:
messages += self.history
messages.append({"role": "user", "content": prompt})
response = self.client.chat.completions.create(
model=self.model_name,
messages=messages
)
return response.choices[0].message.content.strip()
def story_MAKE(self,main):
sys_prompt='你是一个中文早教儿童童话小说家,你的任务是创作一个童话绘本故事,语言优美,故事情节有趣,充满童趣。充满画面感'
pre_userpropmt='接下来请以主题:山羊的智慧写出故事,仿照上面内容格式,用换行分割为一个个段落,每个段落有完整的动作,场景,角色'
assistant_prompt='''主题:山羊的智慧\n内容:\n段落一:一只山羊和一只狐狸住在山上。狐狸总想吃掉山羊,山羊整天担惊受怕。\n人物:山羊,狐狸 \n场景:山上\n情感:害怕\n段落二:有一日,山羊去山下,一不小心掉进了一口井里。狐狸看见了,得意地说:“哈哈!山羊兄弟,你怎么在这里?这井里的水是不是很甜呀?”山羊回答说:“你说的没错,这井里的水的确很甜。”说完,咕咚咕咚喝了几口,“啊!这水实在太甜了。我从没喝过这么甜的井水。”山羊抹了抹嘴上的水说。\n人物:山羊,狐狸\n场景:水井\n情感:害怕\n动作:山羊掉进水井\n段落三:狐狸正感觉口渴,也想下去喝几口。可是,又不知怎样下到井里。于是,狐狸问山羊:“山羊兄弟,我也口渴了。我怎样才能下到井里?”山羊冒充想了想:“这样吧,你踩着我的头,就能下来了。”狐狸踩着山羊的头下到了井里。#喝完水后,狐狸问:“山羊兄弟,我们怎么爬出井去?”山羊不假思考地说:“这好办。我先踩着你的头上去,然后我再伸下一条腿拉你上去。我俩不就都出去了吗。”“这个办法好!”狐狸就让山羊踩着自己的头。山羊顺利爬出了井。\n人物:山羊,狐狸 \n场景:水井\n情感:焦急\n动作:狐狸口渴\n段落四:山羊爬出井,对狐狸说:“该死的狐狸,你就好幸亏井里喝水吧!”聪明人做事,常常会预先想清结果再去做\n人物:山羊,狐狸\n场景:水井\n情感:害怕\n动作:羊爬出水井'''
prompt=f"""接下来请以主题:{main}写出故事,仿照上面内容格式,用换行分割为一个个段落,每个段落有完整的动作,场景,角色,形式中保证有人物,场景,角色,动作"""
print('正在生成故事:。。。。')
response = self.get_llm_response(prompt, sys_prompt, with_history=True,assistant_prompt=assistant_prompt,pre_userpropmt=pre_userpropmt)
print(response)
print('生成完成')
self.story=response
j=response.split('\n')
# while not j[2].replace(' ','')=='段落' :
#
# prompt = '''请按照上述格式重写。如下主题:智慧
# 内容:\n段落一:一只山羊和一只狐狸住在山上。狐狸总想吃掉山羊,山羊整天担惊受怕。\n人物:山羊,狐狸 \n场景:山上\n情感:害怕\n段落二:有一日,山羊去山下,一不小心掉进了一口井里。狐狸看见了,得意地说:“哈哈!山羊兄弟,你怎么在这里?这井里的水是不是很甜呀?”山羊回答说:“你说的没错,这井里的水的确很甜。”说完,咕咚咕咚喝了几口,“啊!这水实在太甜了。我从没喝过这么甜的井水。”山羊抹了抹嘴上的水说。\n人物:山羊,狐狸\n场景:水井\n情感:害怕\n动作:山羊掉进水井\n段落三:狐狸正感觉口渴,也想下去喝几口。可是,又不知怎样下到井里。于是,狐狸问山羊:“山羊兄弟,我也口渴了。我怎样才能下到井里?”山羊冒充想了想:“这样吧,你踩着我的头,就能下来了。”狐狸踩着山羊的头下到了井里。#喝完水后,狐狸问:“山羊兄弟,我们怎么爬出井去?”山羊不假思考地说:“这好办。我先踩着你的头上去,然后我再伸下一条腿拉你上去。我俩不就都出去了吗。”“这个办法好!”狐狸就让山羊踩着自己的头。山羊顺利爬出了井。\n人物:山羊,狐狸 \n场景:水井\n情感:焦急\n动作:狐狸口渴\n段落四:山羊爬出井,对狐狸说:“该死的狐狸,你就好幸亏井里喝水吧!”聪明人做事,常常会预先想清结果再去做\n人物:山羊,狐狸\n场景:水井\n情感:害怕\n动作:羊爬出水井'''
# print(prompt)
# response = self.get_llm_response(prompt, sys_prompt, with_history=True)
# print('fianlai:', response)
# self.story = response
return self.story
def promptmake(self,stroy_struct):
story=''
sys_prompt=f'''你是一个stable diffusion画家,你的任务是用stable diffusion创作一个童话绘本的图片,你要根据我提供的内容输出对应的提示词(prompt),请用英语的单个单词完成,并用逗号分割开,不用写负面提示词,表现主角的动作神态,客体等在后面加入内容人物场景情感的英文翻译。'''
for key, value in stroy_struct.items():
story += f'{key}:{value}\n'
pre_prompt='请你对\n所描绘的场景构造提示词工程'
assistant_prompt ='Prompt:monkey,squirrel,make friends,forest,happy,friendship,thank,smile,grass,together,enjoyed,fun,\nlocation:forest,monkey,\nmotivation:make friends,\nemotion:happy'
prompt=f'''请你对\n{story}所描绘的场景构造提示词工程'''
print(prompt)
response = self.get_llm_response(prompt, sys_prompt, with_history=True,assistant_prompt=assistant_prompt)
print(response)
# prompt='详细一些,请包含所有的信息,根据我提供的内容输出对应的提示词(prompt),请用英语的单个单词完成,并用逗号分割开,不用写负面提示词,'
# response = self.get_llm_response(prompt, sys_prompt, with_history=True)
# prompt = '再详细一些,请包含所有的信息。但不要自己加入新的东西'
# response = self.get_llm_response(prompt, sys_prompt, with_history=True)
print('fianlai:',response)
while True:
reprompt=''
promptli = response.replace('.', ',').replace('"', '').split('\n')
for i in promptli:
j = i.split(':')[-1].split(',')
for n in range(len(j)):
while j[n].startswith(' ') or j[n].endswith(' '):
j[n] = j[n].strip(' ')
j = ','.join(j) + ','
reprompt += j
print('即将输入如下',reprompt)
text=input('这里是修改区域,您可以对他发出指令:(\'退出\')')
if text=='退出':
break
response = self.get_llm_response(prompt, sys_prompt, with_history=True)
print('生成', response)
return reprompt我仿照示例定义了与ai交互的类(aistory),第一个是基本的参数def __init__(self, api_key="----", model_name="yi"):,这里传入的参数构建类(面向对象编程),声明了他有什么属性。接下来就是功能:get_llm_response,story_MAKE,promptmake。分别是获取回复,写故事,写提示词
def get_llm_response(self, prompt, system_prompt=None, with_history=False,assistant_prompt=None,pre_userpropmt=None):
传入文本返回回复,这里对原来进行修改,加入一组对话:pre_userpropmt,回复一个assistant_prompt,我们直接构建了一次对话,强化格式。
def story_MAKE(self,main):
sys_prompt='你是一个中文早教儿童童话小说家,你的任务是创作一个童话绘本故事,语言优美,故事情节有趣,充满童趣。充满画面感'
pre_userpropmt='接下来'
assistant_prompt='''主题:山羊的智慧\n内容:\n段落一:一只山羊和一只狐狸住在山上。狐狸总想吃掉山羊,山羊整天担惊受怕。\n人物:山羊,狐狸 \n场景:山上\n情感:害怕\n段落二:有一日,山羊去山下,一不小心掉进了一口井里。狐狸看见了,得意地说:“哈哈!山羊兄弟,你怎么在这里?这井里的水是不是很甜呀?”山羊回答说:“你说的没错,这井里的水的确很甜。”说完,咕咚咕咚喝了几口,“啊!这水实在太甜了。我从没喝过这么甜的井水。”山羊抹了抹嘴上的水说。\n人物:山羊,狐狸\n场景:水井\n情感:害怕\n动作:山羊掉进水井\n''
prompt=f"""接下来请以主题:{main}写出故事,仿照上面内容格式,用换行分割为一个个段落,每个段落有完整的动作,场景,角色,形式中保证有人物,场景,角色,动作"""
print('正在生成故事:。。。。')
response = self.get_llm_response(prompt, sys_prompt, with_history=True,assistant_prompt=assistant_prompt,pre_userpropmt=pre_userpropmt)
print(response)
print('生成完成')
self.story=response
j=response.split('\n')
return self.story事先传入system和一定的对话,方便大模型回复给我们合适的回复。
下面就是构造故事的结构,把每一段独立解释,分割成列表。然后就是使用sd绘画保存和展示。
def make_stroy_struct(story):
sli=story.split('\n')[2::]
print(sli)
strli = []
for i in range(0, len(sli), 5):
di = {}
sl = sli[i].split(':')
biaoti, neirong = sl[0], sl[-1]
if biaoti[0:2] == '段落':
biaoti = '内容'
di[biaoti] = neirong
for j in sli[i + 1:i + 5]:
sl = j.split(':')
biaoti, neirong = sl[0], sl[-1]
di[biaoti] = neirong
strli.append(di)
print(strli)
return strli
def stablediffusion(file_path,prompt='',nep='',url='http://59.78.189.139:7860/'):
txt2imge_date={
'prompt':'guofeng,outdoor,extremely detailed CG unity 8k wallpaper,ultra- detailed,8k,hires,best quality,(masterpiece:1.2),huge filesize,wallpaper,fairy-tale,early education,best quality,masterpiece,ultra high res,delicate eyes,childpaiting,crayon drawing,'+prompt,
'sampler_name':'DPM++ 2M SDE Karras',
'steps':20,
'batch_size':1,
'height':512,
'width':512,
'cfg_scale':7,
"override_settings": {
# "sd_model_checkpoint": "2d\儿童绘本 _ CrayonPaiting_1.0.safetensors [391faa56e2]",
#"sd_vae":"orangemix.vae.pt"
},
"enable_hr": False,
"denoising_strength": 0.25,
"hr_scale": 2,
"hr_upscaler": "R-ESRGAN 4x+",
'negative_prompt':'(negative_hand-neg:1.2),(((bad-hands-5))),EasyNegative,FastNegativeV2,BadNegAnatomyV1-neg,EasyNegative,NSFW,logo,text,blurry,low quality,bad anatomy,sketches,lowres,normal quality,monochrome,grayscale,worstquality,signature,watermark,cropped,bad proportions,out of focus,username,bad face'+nep,
}
print('\n正在生成图片...')
response=requests.post(url=f'{url}/sdapi/v1/txt2img',json=txt2imge_date)
image=Image.open(io.BytesIO(base64.b64decode(response.json()['images'][0])))
image.show()
print('图片生成完成!')
image.save(file_path)
def drawandshow(story,a):
strli = story
n=1
for i in strli:
print(i)
prompt = a.promptmake(i)
file_path = r'ai/第{}段.png'.format(n)
print(f'生成第{n}段图片...',end='')
stablediffusion(file_path,prompt)
n += 1
if __name__ == '__main__':
a=aistory()
story=a.story_MAKE('友情')
story_struct=make_stroy_struct(story)
drawandshow(story_struct,a)
print('故事完成')问题与反思
实践问题:大模型输出的文本质量不(太)高,api调用速度过慢,格式十分不确定,代码难以预测ai输出的文本内容。同时ai绘图结果不稳定,输出连贯的故事仍然比较困难。
其他探索和改进:1.下载使用童话风的大模型,更加贴合主题。 2.训练自己的画风lora,进行一定画风的固定,此处省略(感兴趣可与笔者交流)。 3.采用不同的大模型(尝试星火,百川,零一万物)。 4.学习了comfyui,并且尝试创造了自己的工作流。
2024最新尝试:调用sdxl1.5模型生成图片
改写sd函数部分详情请见stable_diffusion api调用sdxl1.0模型示例-CSDN博客
def stablediffusionXl(file_path,prompt='',nep='',url='http://127.0.0.1:7860'):
txt2imge_date={
'prompt':'extremely detailed CG unity 8k wallpaper,ultra- detailed,8k,hires,best quality,(masterpiece:1.2),huge filesize,wallpaper,fairy-tale,early education,best quality,masterpiece,ultra high res,delicate eyes,childpaiting,crayon drawing,'+prompt,
'sampler_name':'DPM++ 2M SDE Karras',
"style": "Fairy Tale",
'steps':20,
'batch_size':1,
'height':1024,
'width':1024,
'cfg_scale':7,
"override_settings": {
"sd_model_checkpoint": "xd1.0\sd_xl_base_1.0.safetensors [31e35c80fc]",
"sd_vae":"sdxl_vae.safetensors"
},
#下方使用refiner
"refiner": True,
'refiner_checkpoint':'xd1.0\sd_xl_refiner_1.0.safetensors [7440042bbd]',
'refiner_switch_at':0.8,
#'negative_prompt':'(negative_hand-neg:1.2),(((bad-hands-5))),EasyNegative,FastNegativeV2,BadNegAnatomyV1-neg,EasyNegative,NSFW,logo,text,blurry,low quality,bad anatomy,sketches,lowres,normal quality,monochrome,grayscale,worstquality,signature,watermark,cropped,bad proportions,out of focus,username,bad face'+nep,
}
print('\n正在生成图片...')
response=requests.post(url=f'{url}/sdapi/v1/txt2img',json=txt2imge_date)
image=Image.open(io.BytesIO(base64.b64decode(response.json()['images'][0])))
image.show()
print('图片生成完成!')
image.save(file_path)
生成过程
下面是一次生成过程
友情"
内容:
1. 一只名叫小松鼠的小动物,和一只叫小兔子的小动物住在同一个森林里。他们是最要好的朋友,无论去哪里都会一起。
有一天,他们在森林里发现了一些漂亮的蘑菇,小兔子说:“这些蘑菇看起来很美味,我们一起尝尝吧!” 小松鼠同意了,于是他们开始品尝这些蘑菇。 2. 在他们的正前方有一棵大树,树下有一个大大的蘑菇群。他们都吃得很开心,突然一阵大风吹过,把小兔子的帽子吹跑了。
他非常担心他的帽子被风吹到远处去找不回,小松鼠看到他担心的样子,决定和他一起找帽子。他们开始在森林里寻找那顶帽子,最终在小溪边找到了它。 3. 小兔子感激地抱着小松鼠说:“谢谢你陪我找帽子,我真的很感谢你对我的帮助和支持!”
小松鼠笑着说:“我们是最好的朋友,我当然会帮助你啦!” 他们的友谊变得更加深厚了。他们一起回到了森林里继续玩耍和探险。
故事完成
第1段: 1. 一只名叫小松鼠的小动物,和一只叫小兔子的小动物住在同一个森林里。他们是最要好的朋友,无论去哪里都会一起。 完成
第2段: 有一天,他们在森林里发现了一些漂亮的蘑菇,小兔子说:“这些蘑菇看起来很美味,我们一起尝尝吧!” 小松鼠同意了,于是他们开始品尝这些蘑菇。 2. 在他们的正前方有一棵大树,树下有一个大大的蘑菇群。他们都吃得很开心,突然一阵大风吹过,把小兔子的帽子吹跑了。 完成
第3段: 他非常担心他的帽子被风吹到远处去找不回,小松鼠看到他担心的样子,决定和他一起找帽子。他们开始在森林里寻找那顶帽子,最终在小溪边找到了它。 3. 小兔子感激地抱着小松鼠说:“谢谢你陪我找帽子,我真的很感谢你对我的帮助和支持!”完成
第4段: 小松鼠笑着说:“我们是最好的朋友,我当然会帮助你啦!” 他们的友谊变得更加深厚了。他们一起回到了森林里继续玩耍和探险。完成
1. 一只名叫小松鼠的小动物,和一只叫小兔子的小动物住在同一个森林里。他们是最要好的朋友,无论去哪里都会一起。 有一天,他们在森林里发现了一些漂亮的蘑菇,小兔子说:“这些蘑菇看起来很美味,我们一起尝尝吧!” 小松鼠同意了,于是他们开始品尝这些蘑菇。 2. 在他们的正前方有一棵大树,树下有一个大大的蘑菇群。他们都吃得很开心,突然一阵大风吹过,把小兔子的帽子吹跑了。 他非常担心他的帽子被风吹到远处去找不回,小松鼠看到他担心的样子,决定和他一起找帽子。他们开始在森林里寻找那顶帽子,最终在小溪边找到了它。 3. 小兔子感激地抱着小松鼠说:“谢谢你陪我找帽子,我真的很感谢你对我的帮助和支持!” 小松鼠笑着说:“我们是最好的朋友,我当然会帮助你啦!” 他们的友谊变得更加深厚了。他们一起回到了森林里继续玩耍和探险。




补充一些丢失了文本,但是由上一段代码生成的图片,采用了不同的lora和模型





















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









