






 本文详细介绍了如何在使用sd1.0模型的API中进行操作,包括分辨率升级、关键词识别功能、风格控制以及refiner的使用。特别强调了新版本对显卡的要求以及与sd1.5模型的区别,同时提供了一份代码示例以指导API参数配置。
本文详细介绍了如何在使用sd1.0模型的API中进行操作,包括分辨率升级、关键词识别功能、风格控制以及refiner的使用。特别强调了新版本对显卡的要求以及与sd1.5模型的区别,同时提供了一份代码示例以指导API参数配置。
如何使用sd1.0模型
在api使用sdxl1.0时我们会发现在步骤和内容上会和我们使用sd1.5存在不同,同时,sdxl1.0对显卡要求较高。xl1.0拥有出色的句子识别功能(这是对前文儿童故事绘图的一次尝试),强大的风格模块,堪比lora。
0.模型不同(废话):笔者采用sd_xl_base_1.0.safetensors,现阶段xl1.0微调模型有了一定发展,但在丰富度和数量上还是sd1.5占据优势
1.分辨率扩大:eg512*512 to 1024*1024(不需要放大模型)
2.在关键词上可以识别句子(英文),但也可以采用原有形式,不需要再输入质量画面(masterpice,best quality)等提示词也可以有很好的效果,负面提示词也可以做到少输入。
3.使用风格关键词(很重要):出现"style"参数,一些可选风格如下(webui中截图)
4.生成时要使用refiner:sd_xl_refiner_1.0.safetensors,refiner有模型选择,选择时机总步数的多少就开始切换,模型(20步,0.8,16步开始后使用refiner选择的模型)
代码实现
代码
import requests
import base64
from PIL import Image
import io
def stablediffusionXl(file_path,prompt='',nep='',url='http://127.0.0.1:7860'):
txt2imge_date={
'prompt':prompt,
'sampler_name':'Euler a',
"style": "Fairy Tale",
'steps':20,
'batch_size':1,
'height':1024,
'width':1024,
'cfg_scale':7,
"override_settings": {
"sd_model_checkpoint": "xd1.0\sd_xl_base_1.0.safetensors [31e35c80fc]",
"sd_vae":"sdxl_vae.safetensors"
},
#下方使用refiner
"refiner": True,
'refiner_checkpoint':'xd1.0\sd_xl_refiner_1.0.safetensors [7440042bbd]',
'refiner_switch_at':0.8,
#'negative_prompt':'(negative_hand-neg:1.2),(((bad-hands-5))),EasyNegative,FastNegativeV2,BadNegAnatomyV1-neg,EasyNegative,NSFW,logo,text,blurry,low quality,bad anatomy,sketches,lowres,normal quality,monochrome,grayscale,worstquality,signature,watermark,cropped,bad proportions,out of focus,username,bad face'+nep,
}
print('\n正在生成图片...')
response=requests.post(url=f'{url}/sdapi/v1/txt2img',json=txt2imge_date)
image=Image.open(io.BytesIO(base64.b64decode(response.json()['images'][0])))
image.show()
print('图片生成完成!')
image.save(file_path)
if __name__ == '__main__':
stablediffusionXl('test.jpg','Two birds, live in the same tree. They are best friends and sing together all day long. However one day suddenly one bird is shot by an arrow from a hunter rendering it unable to fly. The other very worried decides to bring it into the human world for help. Characters: Bird A & Bird B Scenery: Under the tree Emotion: Worry Action: Bird B saves Bird A')问题:如何使用我们不知道的api参数
与先前的api模块相比,这里明显多了许多字段,我们在webui中的操作就是打勾选中,调整参数,但在api调用中我们找不到掉用方法怎么办?
只能求助源码了AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI (github.com)这一个是git上的源码,我们可以把它下载下来。这个文件也存在在我们安装的秋叶整合包,位置也是一样的,我们用vscode打开整个文件
便能找到其中stable-diffusion-webui-master\modules\api,这里就是整个说明书了。
找到api下的txt2image:
self.add_api_route("/sdapi/v1/txt2img", self.text2imgapi, methods=["POST"], response_model=models.TextToImageResponse)选中self.text2imgaapi,右键点击后选择转到定义,便可找到它在哪了
同样我们找到这里到底应用的了什么
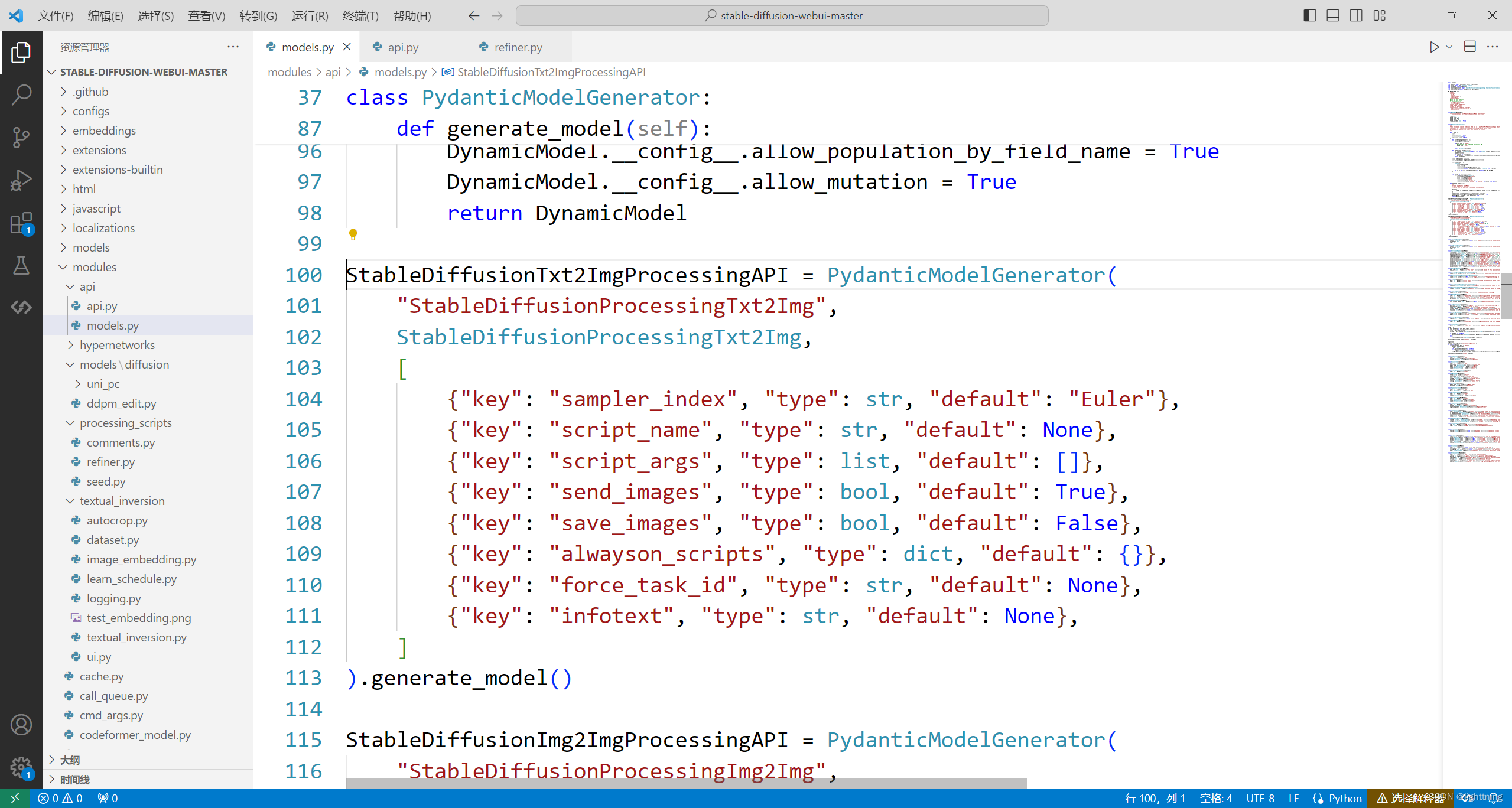
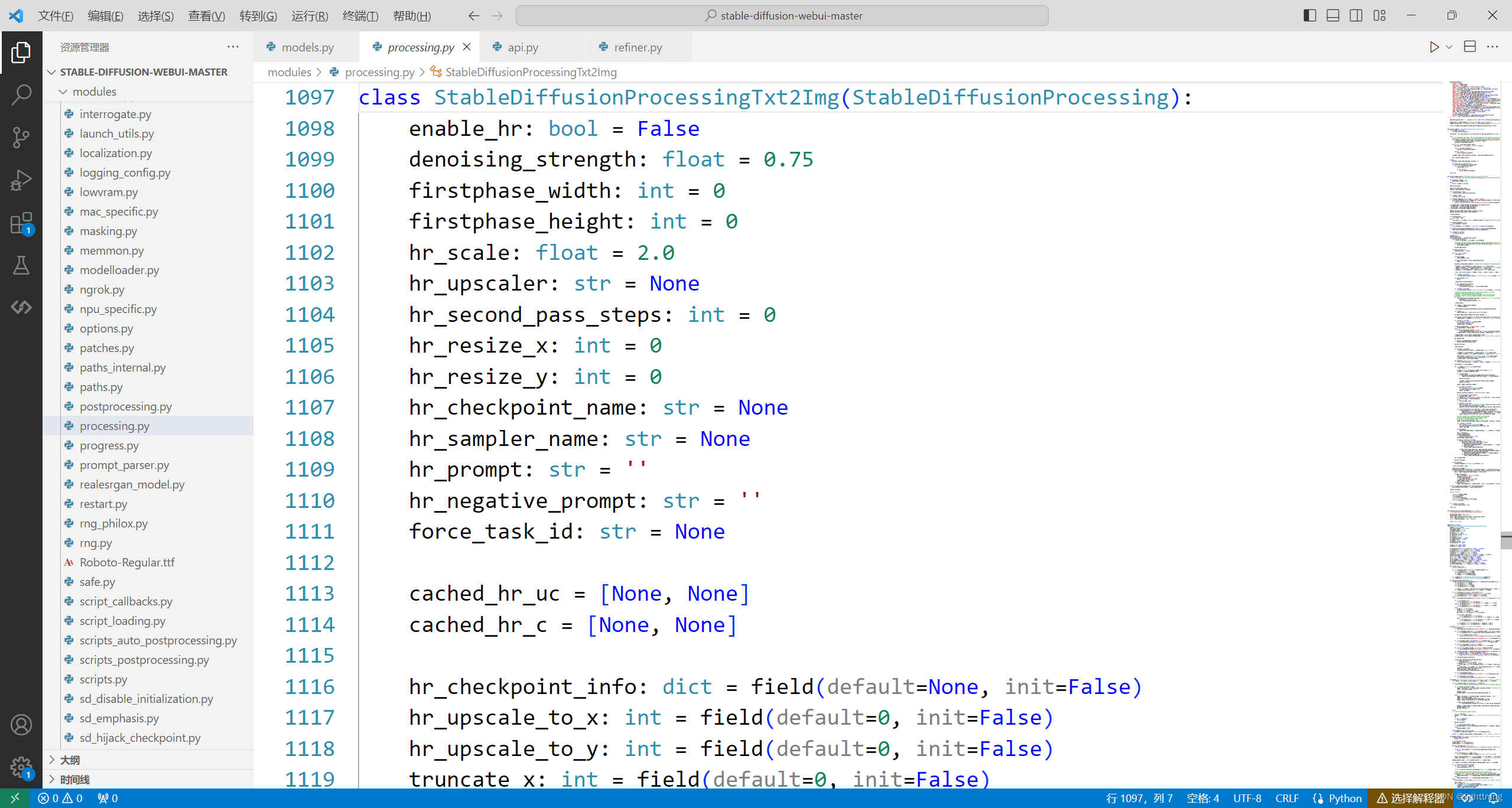
展示一部分这里的代码,这里按照这样的格式:字段:类型=初始值
class StableDiffusionProcessingTxt2Img(StableDiffusionProcessing):
enable_hr: bool = False
denoising_strength: float = 0.75
firstphase_width: int = 0
firstphase_height: int = 0
hr_scale: float = 2.0
hr_upscaler: str = None
hr_second_pass_steps: int = 0
hr_resize_x: int = 0
hr_resize_y: int = 0
hr_checkpoint_name: str = None
hr_sampler_name: str = None
hr_prompt: str = ''
hr_negative_prompt: str = ''
force_task_id: str = None
cached_hr_uc = [None, None]
cached_hr_c = [None, None]
hr_checkpoint_info: dict = field(default=None, init=False)
hr_upscale_to_x: int = field(default=0, init=False)
hr_upscale_to_y: int = field(default=0, init=False)
truncate_x: int = field(default=0, init=False)
truncate_y: int = field(default=0, init=False)
applied_old_hires_behavior_to: tuple = field(default=None, init=False)
latent_scale_mode: dict = field(default=None, init=False)
hr_c: tuple | None = field(default=None, init=False)
hr_uc: tuple | None = field(default=None, init=False)
all_hr_prompts: list = field(default=None, init=False)
all_hr_negative_prompts: list = field(default=None, init=False)
hr_prompts: list = field(default=None, init=False)
hr_negative_prompts: list = field(default=None, init=False)
hr_extra_network_data: list = field(default=None, init=False)
我们找到了StableDiffusionProcessingTxt2Img,下面就是一些特有的参数,但上面还有一层StableDiffusionProcessing我们往下,找到最源头的类代码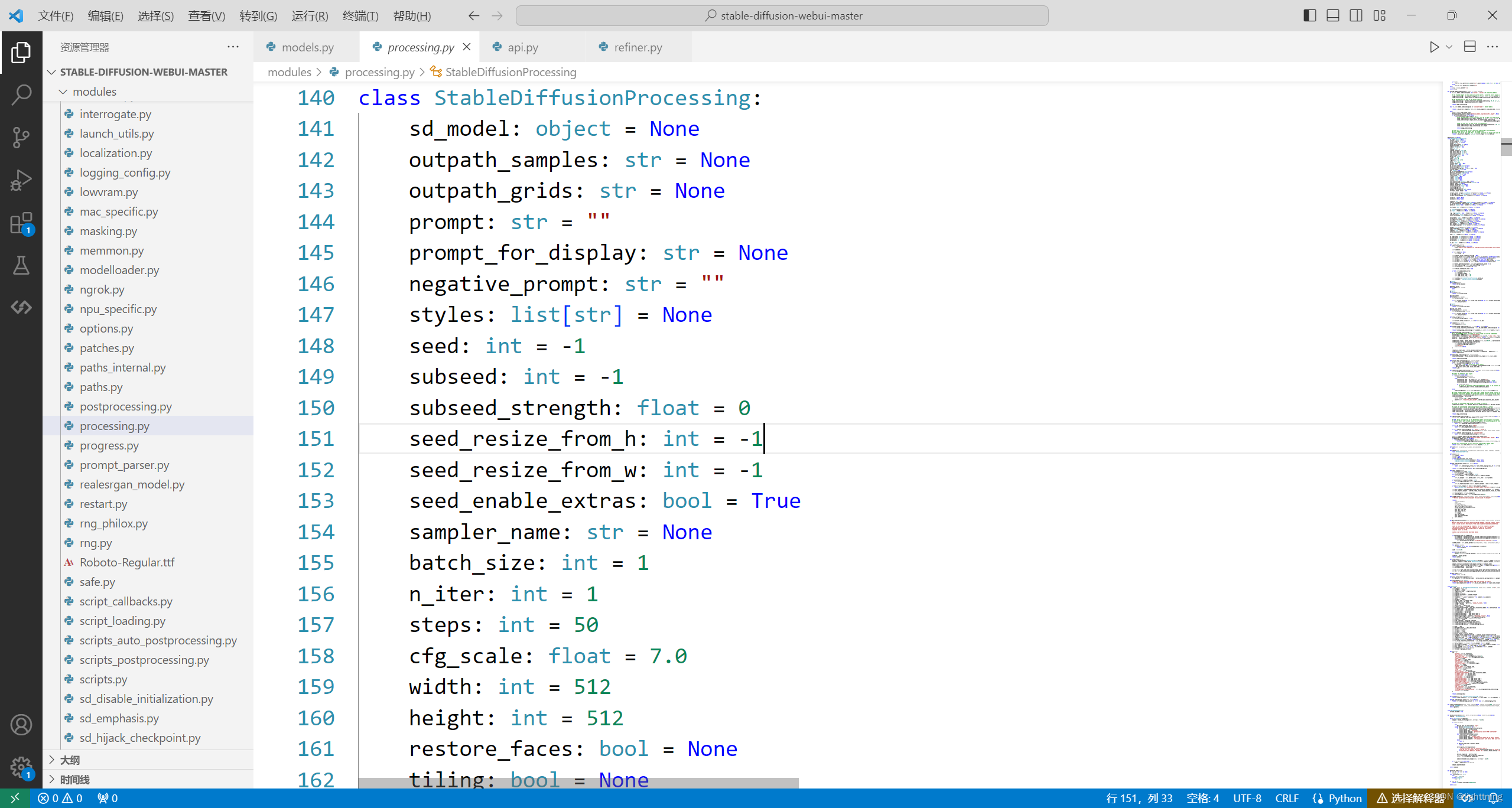
class StableDiffusionProcessing:
sd_model: object = None
outpath_samples: str = None
outpath_grids: str = None
prompt: str = ""
prompt_for_display: str = None
negative_prompt: str = ""
styles: list[str] = None
seed: int = -1
subseed: int = -1
subseed_strength: float = 0
seed_resize_from_h: int = -1
seed_resize_from_w: int = -1
seed_enable_extras: bool = True
sampler_name: str = None
batch_size: int = 1
n_iter: int = 1
steps: int = 50
cfg_scale: float = 7.0
width: int = 512
height: int = 512
restore_faces: bool = None
tiling: bool = None
do_not_save_samples: bool = False
do_not_save_grid: bool = False
extra_generation_params: dict[str, Any] = None
overlay_images: list = None
eta: float = None
do_not_reload_embeddings: bool = False
denoising_strength: float = None
ddim_discretize: str = None
s_min_uncond: float = None
s_churn: float = None
s_tmax: float = None
s_tmin: float = None
s_noise: float = None
override_settings: dict[str, Any] = None
override_settings_restore_afterwards: bool = True
sampler_index: int = None
refiner_checkpoint: str = None
refiner_switch_at: float = None
token_merging_ratio = 0
token_merging_ratio_hr = 0
disable_extra_networks: bool = False
firstpass_image: Image = None
scripts_value: scripts.ScriptRunner = field(default=None, init=False)
script_args_value: list = field(default=None, init=False)
scripts_setup_complete: bool = field(default=False, init=False)
cached_uc = [None, None]
cached_c = [None, None]
comments: dict = None
sampler: sd_samplers_common.Sampler | None = field(default=None, init=False)
is_using_inpainting_conditioning: bool = field(default=False, init=False)
paste_to: tuple | None = field(default=None, init=False)
is_hr_pass: bool = field(default=False, init=False)
c: tuple = field(default=None, init=False)
uc: tuple = field(default=None, init=False)
rng: rng.ImageRNG | None = field(default=None, init=False)
step_multiplier: int = field(default=1, init=False)
color_corrections: list = field(default=None, init=False)
all_prompts: list = field(default=None, init=False)
all_negative_prompts: list = field(default=None, init=False)
all_seeds: list = field(default=None, init=False)
all_subseeds: list = field(default=None, init=False)
iteration: int = field(default=0, init=False)
main_prompt: str = field(default=None, init=False)
main_negative_prompt: str = field(default=None, init=False)
prompts: list = field(default=None, init=False)
negative_prompts: list = field(default=None, init=False)
seeds: list = field(default=None, init=False)
subseeds: list = field(default=None, init=False)
extra_network_data: dict = field(default=None, init=False)
user: str = field(default=None, init=False)
sd_model_name: str = field(default=None, init=False)
sd_model_hash: str = field(default=None, init=False)
sd_vae_name: str = field(default=None, init=False)
sd_vae_hash: str = field(default=None, init=False)
is_api: bool = field(default=False, init=False)refiner_checkpoint: str = None
refiner_switch_at: float = None
我们找到了refiner字段,明白了如何使用refiner,调用时的各种参数设置。明白如何查资料,便可以调用源代码作者的各种方法模型了

















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









