






 Stable-DreamFusion是DreamFusion的PyTorch实现,结合预训练的文本到图像diffusion模型和NeRF(如mip-NeRF360)来生成三维模型。文章详细介绍了NeRF的工作原理,包括相机参数的使用,内外参数在坐标变换中的角色,以及如何通过体积渲染技术训练和优化NeRF场景表示。
Stable-DreamFusion是DreamFusion的PyTorch实现,结合预训练的文本到图像diffusion模型和NeRF(如mip-NeRF360)来生成三维模型。文章详细介绍了NeRF的工作原理,包括相机参数的使用,内外参数在坐标变换中的角色,以及如何通过体积渲染技术训练和优化NeRF场景表示。
上一篇文章将代码进行了部署和应用,但对于实现的原理还是一片模糊,所以这篇文章探究一下Stable-DreamFusion的实现
Stable-DreamFusion整体可以实现输入文字和图片,生成三维模型,作者说其是DreamFusion这篇论文的pytorch实现版,所以先看看DreamFusion这篇论文
DreamFusion实际上是文字生成三维模型,具体组成结构为一个预训练好的文本to图像的diffusion模型,一个NeRF,论文中具体为mip-NeRF 360,
具体流程为
(1)随机生成一个相机和光源
(2)从该相机渲染NeRF的图像,并用灯光进行阴影处理
(3)计算SDSloss相对于NeRF参数的梯度
(4) 使用优化器更新NeRF参数
在此流程中,我对diffusion模型还比较熟悉,但NeRF为新接触的事物,故学习NeRF
首先还是理解NeRF的作用和整体流程
这里感谢大佬的文章NeRF代码解读-相机参数与坐标系变换 - 知乎 (zhihu.com)
NeRF的作用通俗来讲应该是通过输入的多个不同视角下的图像合成出最后的三维目标。
具体流程是
(1)数据预处理:NeRF输入除了图像还需要相机参数,相机参数包含内外参数两类,相机外参(extrinsic matrix)是相机位置和朝向的组合,是一个4x4的矩阵,其作用是将世界坐标系的点变换到相机坐标系下,因为不熟悉怎么打公式,所以引用一下大佬的公式图,因为本科学习过机器人坐标变换,这里还是可以理解的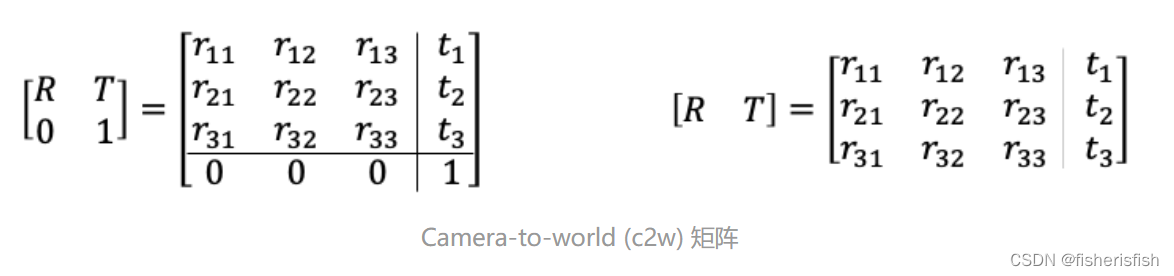

旋转矩阵的第一列到第三列分别表示了相机坐标系的X, Y, Z轴在世界坐标系下对应的方向;平移向量表示的是相机原点在世界坐标系的对应位置。
相机内参(intrinsic matrix)为投影属性,将相机坐标系下的3D坐标映射到2D的图像平面

内参矩阵K包含4个值,其中fx和fy是相机的水平和垂直焦距(对于理想的针孔相机,fx=fy)。焦距的物理含义是相机中心到成像平面的距离,长度以像素为单位。cx和cy是图像原点相对于相机光心的水平和垂直偏移量。cx,cy有时候可以用图像宽和高的1/2近似。
相机参数的作用很好理解,毕竟我们是要用图像合成三维模型,相机参数都是有用的计算映射矩阵。那么如何获得相机参数呢?对于模拟的数据,可以设定相机角度;对于真实的数据,可以利用运动恢复结构(structure-from-motion, SFM)技术估计几个相机间的相对位姿。这个技术可以利用开源软件包COLMAP: https://colmap.github.io/。输入多张图像,COLMAP可以估计出相机的内参和外参(也就是sparse model)。COLMAP后续的应用篇里再具体介绍用法和原理。
在NeRF里有imgs2poses.py来实现图像到相机坐标的实现,运行之后会保存为一个poses_bounds.npy,是一个Nx17的矩阵,其中N是图像的数量,即每一张图像有17个参数。其中前面15个参数可以重排成3x5的矩阵形式:

最后两个参数用于表示场景的范围Bounds (bds),是该相机视角下场景点离相机中心最近(near)和最远(far)的距离,所以near/far肯定是大于0的。
- 这两个值是怎么得到的?是在imgs2poses.py中,计算colmap重建的3D稀疏点在各个相机视角下最近和最远的距离得到的。
- 这两个值有什么用?之前提到体素渲染需要在一条射线上采样3D点,这就需要一个采样区间,而near和far就是定义了采样区间的最近点和最远点。贴近场景边界的near/far可以使采样点分布更加密集,从而有效地提升收敛速度和渲染质量。
后续再用load_llff.py来读取数据。
模型训练:准备好图像(用于提供real像素值)和17个参数,根据相机位姿和相机焦距得到成像平面,并根据图像的长宽限制成像范围。
取成像平面中某一位置(对应的real像素值是已知的),与相机位置的连线构成一条射线,得到二维的视角参数,在最近和最远距离内采样 n 个点,得到三维的位置参数,构成n个五维向量。
然后根据相机位姿参数转化到世界坐标系,送入MLP中,预测每个点的rgb和sigma,此时并不会直接对采样点进行监督,而是根据体渲染得到fake像素值,通过real和fake之间的误差来监督训练。
测试:和训练一致。
模型训练和测试这样子讲是很难理解的,具体而言还是得知道输入和输出,以及模型的结构还有数据在推理过程中的变化。
NeRF(Neural Radiance Fields)这个名字的含义就是神经辐射场,具体而言是一种三维场景表示(scene representation),而且是一种隐式的场景表示(implicit scene representation),因为不能像point cloud、mesh、voxel一样直接看见一个三维模型。NeRF将场景表示为空间中任何点的volume density 和颜色值 。 有了以NeRF形式存在的场景表示后,可以对该场景进行渲染,生成新视角的模拟图片。论文使用经典体积渲染(volume rendering)的原理,求解穿过场景的任何光线的颜色,从而渲染合成新的图像。
- 先将这些位置输入MLP以产生volume density和RGB颜色值;
- 取不同的位置,使用体积渲染技术将这些值合成为一张完整的图像;
- 因为体积渲染函数是可微的,所以可以通过最小化上一步渲染合成的、真实图像之间的差来训练优化NeRF场景表示。


















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









