






对多元函数求偏导,把求得的各个参数的导数以向量的形式写出来就是梯度。模型参数为Θ,损失函数为![]()
使用梯度下降法更新参数为:

批量梯度下降法BGD需要计算整个数据样本集,梯度下降速度慢,收敛速度会很慢,但每次下降方向为总体的平均梯度,得到一个全局最优解。
随机梯度下降法SGD每次参数计算仅仅计算一个样本,训练速度很快,每次迭代都不能代表整体最优方向,导致梯度下降波动大,更容易从一个局部最优跳到另一个局部最优,准确度下降。
小批量梯度下降法就是结合BGD和SGD的折中,对于含有n个训练样本的数据集,每次参数更新,选择一个大小为m的mini-batch数据样本计算其梯度。既保证速度有保证了准确率。选择合适的learning rate比较困难,所有参数都是用同样的learning rate。
动量优化法加速梯度下降,有momentum和nesterov两种算法。
momentum算法思想:参数更新时在一定程度上保留之前更新的方向,同时又利用当前batch的梯度微调最终的更新方向,简言之就是通过积累之前的动量来加速当前的梯度。mt表示t时刻的动量,u动量因子,通常选取0.9,在SGD的基础上添加动量,更新参数。
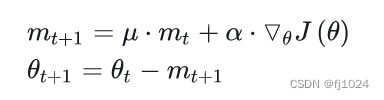
在梯度方向改变时,momentum能够降低参数更新速度,从而减少震荡;在梯度方向相同时,momentum可以加速参数更新, 从而加速收敛。momentum能够加速SGD收敛,抑制震荡。
nesterov是是momentum的改进,在梯度更新时做一个矫正。

加上nesterov项后,梯度在大的跳跃后,进行计算对当前梯度进行校正。
自适应学习率优化算法:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法。
















 731
731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









