






束搜索指在每一个时间步解码时,不再只保留一个分数最高的作为输出,保留num_beams个。当num_beams=1时,束搜索就退化成了贪心搜索。
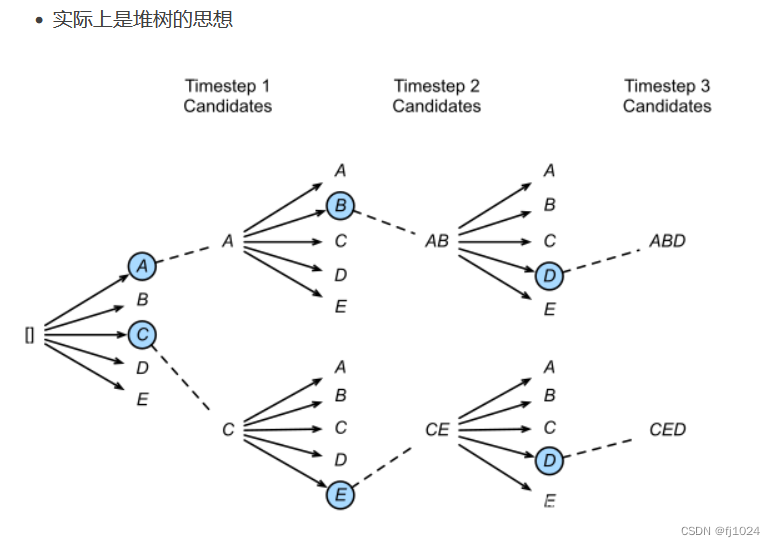
缺点,虽然比贪心搜索强不少,但是也会生成出重复、空洞、前后矛盾的文本。
改进方法:
随机采样,用随机采样(sampling)代替取概率最大的词。增大所选词的范围,引入更多的随机性。
temperature随机采样,用过温度参数控制softmax函数产生单词概率的平滑程度。
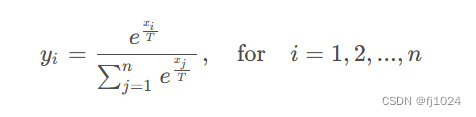
通过调整温度参数 T 的值,可以改变输出向量 y中每个元素的相对大小。当温度参数 T 较高时,指数运算的结果会变得更加平均,导致概率分布更加均匀,各个类别的概率差异较小。而当温度参数 T 较低时,指数运算的结果会更加集中,导致概率分布更加尖锐,各个类别的概率差异较大。
当温度参数 T趋近于无穷大时,softmax函数的输出将趋近于均匀分布,即每个类别的概率接近于 1\n,其中 n是类别的数量。而当温度参数T趋近于零时,softmax函数的输出将趋近于一个独热编码,即只有最大值对应的类别的概率接近于1,其他类别的概率接近于0。
top k 采样 这个方法就是在采样前将输出的概率分布截断,取出概率最大的k个词构成一个集合,然后将这个子集词的概率再归一化,最后从新的概率分布中采样词汇。
top p 采样 累加概率,前若干个词多概率进行累加一直到达到p的阈值,然后取出前面这若干个词,重新进行概率归一化,并把剩下词的概率设为0。
惩罚重复:为了解决重复问题,还可以通过惩罚因子将出现过词的概率变小或者强制不使用重复词来解决。















 82
82











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









