







一、词汇表达
1. 编码
①独热编码 | one-hot representation
独热编码是指在向量中用一个位置来代表一个词
one-hot 的缺点如下:
- 无法表达词语之间的关系
- 而且这种过于稀疏的向量,导致计算和存储的效率都不高
②词嵌入 | word embedding
词嵌入是指用多个特征来表示一个词,而这多个特征也就形成了一个空间(维数为特征的数量),所以就相当于将该词(多维向量)嵌入到了所属空间中。
词嵌入的优势有:
- 可以将文本通过一个低维向量来表达,不像 one-hot 那么长。
- 语意相似的词在向量空间上也会比较相近
2. 向量相似性
①余弦相似度
余弦相似度通过测量两个向量的夹角的余弦值来度量它们之间的相似性。而其他任何角度的余弦值都不大于1;并且其最小值是-1。
s
i
m
(
u
,
v
)
=
u
T
v
∣
∣
u
∣
∣
∗
∣
∣
v
∣
∣
sim(u, v)=\frac{u^Tv}{||u||*||v||}
sim(u,v)=∣∣u∣∣∗∣∣v∣∣uTv
②欧氏距离
欧氏距离是用于衡量个体在空间上存在的距离,距离越远说明个体间的差异越大
d
(
u
,
v
)
=
∣
∣
u
−
v
∣
∣
d(u, v)=||u-v||
d(u,v)=∣∣u−v∣∣
3. 词嵌入算法
①Word2vec
Word2Vec是用来生成词向量的工具。Word2Vec是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层,模型框架根据输入输出的不同,主要包括CBOW(通过上下文来预测当前词)和Skip-gram(通过当前词来预测上下文)模型。
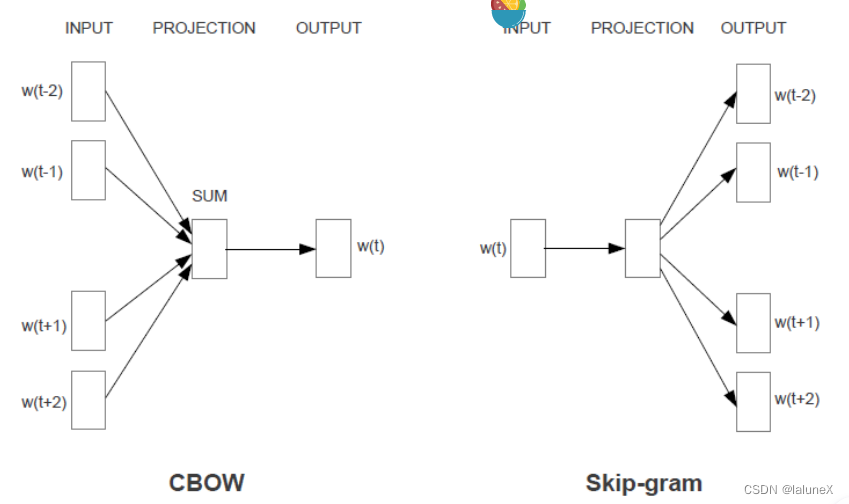
1. CBOW
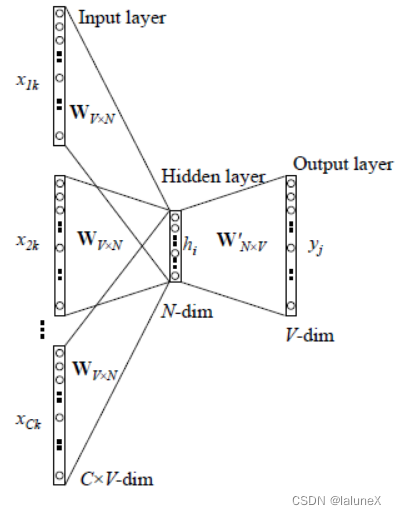
1、输入层:上下文单词是One-Hot编码词向量,V为词汇表单词个数,N为自定义的词向量的维度,C为上下文单词个数
2、初始化一个权重矩阵 W V × N W_{V×N} WV×N,然后用所有输入的One-Hot编码词向量左乘该矩阵,得到维数为N的向量 w 1 , w 2 , w 3 , . . . , w c w_1, w_2, w_3,..., w_c w1,w2,w3,...,wc,这里的N由自己根据任务需要设置
3、将所得的向量 w 1 , w 2 , w 3 , . . . , w c w_1, w_2, w_3,..., w_c w1,w2,w3,...,wc相加求平均作为隐藏层向量 h i h_i hi
4、初始化另一个权重矩阵 W V × N ′ W_{V×N}^′ WV×N′,用隐藏层向量 h i h_i hi左乘 这个矩阵,得到V维的向量y,y的每一个元素代表相对应的每个单词的概率分布
5、y中概率最大的元素所指示的单词为预测出的目标词(target word),而它与true label的One-Hot编码词向量做比较,误差越小越好(根据误差更新两个权重矩阵)
在训练前需要定义好损失函数(一般为交叉熵代价函数),采用梯度下降算法更新W和W’。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量,也叫做word embedding。因为One-Hot编码词向量中只有一个元素为1,其他都为0,所以第i个词向量乘以矩阵W得到的就是矩阵的第i行
2. Skip-gram
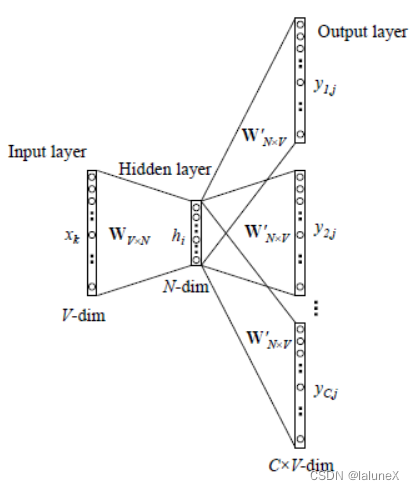
1、输入层:V为词汇表单词个数,N为自定义的词向量的维度,C为上下文单词个数,首先我们选句子中间的一个词作为我们的输入词
2、然后再根据skip_window(它代表着我们从当前input word的一侧(左边或右边)选取词的数量)来获得窗口中的词。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word。最后会得到 (input word, output word) 形式的训练数据
3、神经网络基于这些训练数据中每对单词出现的次数习得统计结果,并输出一个概率分布,这个概率分布代表着到我们词典中每个词有多大可能性跟input word同时出现。
4、通过梯度下降和反向传播更新矩阵W和W’
5、W中的行向量即为每个单词的Word embedding
在前面两节中我们介绍了CBOW和Skip-gram最理想情况下的实现,即训练迭代两个矩阵W和W’,之后在输出层采用softmax函数来计算输出各个词的概率。但在实际应用中这种方法的训练开销很大,不具有很强的实用性,为了使得模型便于训练,有学者提出了Hierarchical Softmax和Negative Sampling两种改进方法。
3. Hierarchical Softmax(分级softmax)
Hierarchical Softmax对原模型的改进主要有两点,
- 第一点是从输入层到隐藏层的映射,没有采用原先的与矩阵W相乘然后相加求平均的方法,而是直接对所有输入的词向量求和。假设输入的词向量为(0,1,0,0)和(0,0,0,1),那么隐藏层的向量为(0,1,0,1)。
- 第二点改进是采用哈夫曼树来替换了原先的从隐藏层到输出层的矩阵W’。哈夫曼树的叶节点个数为词汇表的单词个数V,一个叶节点代表一个单词,而从根节点到该叶节点的路径确定了这个单词最终输出的词向量。
最后预测输出向量时候,它原来本质上是个多分类的问题,但是通过hierarchical softmax的技巧,把V分类的问题变成了log(V)次二分类。
4. Negative Sampling(负采样)
尽管哈夫曼树的引入为模型的训练缩短了许多开销,但对于一些不常见、较生僻的词汇,哈夫曼树在计算它们的词向量时仍然需要做大量的运算。
正采样从句中找一个input word,之后找一个word做其上下文,最后置target为1
负采样是选同正采样相同的input word,然后再从字典集中随机找一个单词(无论是否出现在该句中),最后置target为0,共有k个负样本。这样就形成了训练数据
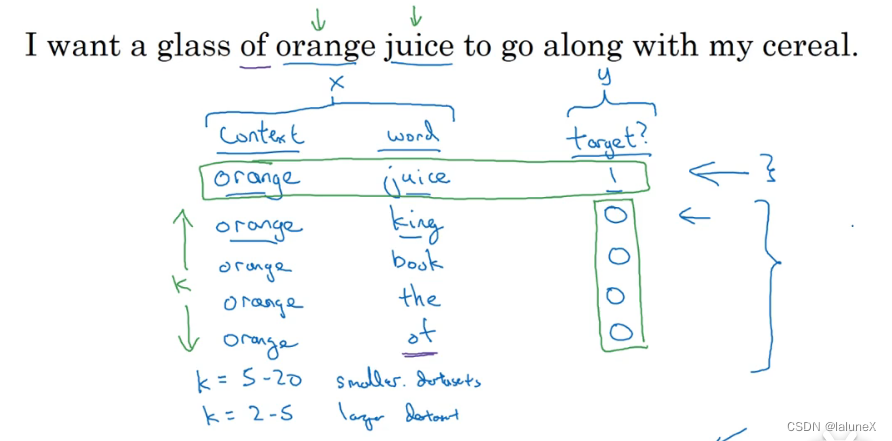
也就是说对训练集进行了采样,从而减小了训练集的大小,只用了target中的1和部分0
②GloVe
GloVe 是对 Word2vec 方法的扩展,它将全局统计和 Word2vec 的基于上下文的学习结合了起来。

二、Beam Search
1. 介绍
Beam Search(集束搜索)是一种近似搜索算法,它是为了减少搜索所占用的空间和时间,所以在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。但缺点就是有可能存在潜在的最佳方案被丢弃
集束宽度是一个需要设置的参数,它代表着每次保留高质量结点的数量
集束搜索本质上也是贪心的思想,只不过它考虑了更多的候选搜索空间
2. 束搜索的改进
原公式:
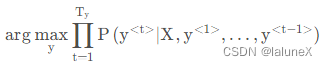
因为每个条件概率都是小于1,而对于长句来说,多个小于1的数值相乘,会使算法对长句的预测不好。而且若数值太小,导致电脑的浮点表示不能精确地存储,而是取对数
解决方法:对beam search的目标函数的改进
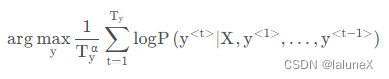
α∈[0,1]是一个超参数,一般取α = 0.7。若α = 0,则不归一化;若α = 1,则标准的长度归一化。
3. 束搜索的误差分析
在实际项目中,当模型拟合效果不佳时,如何判断是RNN模型还是Beam Search出了问题呢?

在翻译任务中,
y
∗
y^*
y∗表示人工翻译结果,
y
^
\hat{y}
y^表示算法结果。
- 第一种出错原因:期望值概率高,但是Beam Search没有选择期望值,是Beam Search的问题,可以通过增加B来改善。
- 第二种出错原因:RNN模型对期望值给出了错误的概率,给一个好的句子小的概率,所以RNN模型出错,需要在RNN模型上花更多时间。
4. Bleu得分
BLEU(Bilingual Evaluation Understudy),即双语评估替补。所谓替补就是代替人类来评估机器翻译的每一个输出结果。Bleu score 所做的,给定一个机器生成的翻译,自动计算一个分数,衡量机器翻译的好坏
B
l
e
u
=
B
P
∗
e
x
p
(
1
n
∑
i
=
1
N
P
n
)
Bleu=BP*exp(\frac{1}{n}\sum_{i=1}^NP_n)
Bleu=BP∗exp(n1∑i=1NPn)
其中,BP是简短惩罚因子,惩罚一句话的长度过短,防止训练结果倾向短句的现象,其表达式为:
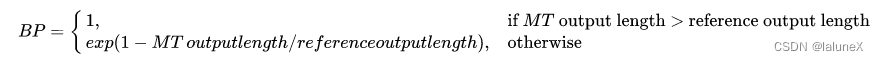
三、其他
1. 参考链接
- https://www.cnblogs.com/lfri/p/15032919.html
本文只用于个人学习与记录,侵权立删















 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









