









前面学习了基础神经网络算法,可以得知神经网络基本结构中:神经元(Node)的个数,层数(Layer),以及激活函数的类型和神经元之间的连接形式都是可以自己选择的,这就导致结构的多样性,那么如何选择呢?当然是视情况而定了。
浅层与深层(Shallow versus Deep Neural Networks)
浅(shallow)层以为着较少(few)的隐含层(hidden layers)。其意味着:
- 训练效率高
- 简单的结构设计
- 理论上如果神经元足够多,那么就足够强,拟合任何问题
深层(deep)层以为着较少(few)的隐含层(hidden layers)。其意味着:
- 训练时间消耗大
- 复杂的结构设计
- 非常有力,可以拟合任何问题
- 更有意义
对于深度神经网络来说,由于层数较多,那每一层的任务相对来说比较简单,许多层完成一个复杂任务。并且常常用于一些使用原始特征比较困难的学习任务。
深度学习的挑战和关键技术(Challenges and Key Techniques)
difficult structural decisions:
结构设计困难
- subjective with domain knowledge: like convolutional NNet for
images
具有主观性,一般会结合专业知识进行设计,像卷积神经网络
high model complexity:
高模型复杂度
- no big worries if big enough data
如果数据不够多会导致过拟合 - regularization towards noise-tolerant: like
对噪声的容忍度提高- dropout (tolerant when network corrupted),对网络出现问题导致噪声的容忍度
- denoising (tolerant when input corrupted),对输入噪声的容忍度
hard optimization problem:
很难优化
- careful initialization to avoid bad local minimum: called pre-training
仔细选择初始值以防止不好的局部最优解,叫做预训练
huge computational complexity (worsen with big data):
高计算复杂度
- novel hardware/architecture: like mini-batch with GPU
随着硬件的更新换代,这一问题得到缓和。
林老师认为这几条中初始化和正则化属于比较关键的技术。
二阶段深度学习框架(A Two-Step Deep Learning Framework)
第一阶段是:
for ℓ = 1 , … , L . pre-train { w i j ( ℓ ) } assuming w ∗ ( 1 ) , … w ∗ ( ℓ − 1 ) fixed \text { for } \ell = 1 , \ldots , L . \text { pre-train } \left\{ w _ { i j } ^ { ( \ell ) } \right\} \text { assuming } w _ { * } ^ { ( 1 ) } , \ldots w _ { * } ^ { ( \ell - 1 ) } \text { fixed } for ℓ=1,…,L. pre-train {wij(ℓ)} assuming w∗(1),…w∗(ℓ−1) fixed
什么意思呢,简单来说就是,先获得第一层的权重值,然后固定第一层的权重值来获得第二层的权重值,依次执行到最后一层。这一过程叫做预训练(pre-train)。可以看出这是一个多输入多输出问题(MIMO),但是丝毫不影响神经网络的训练,这是由于反向传播算法的实现,如果有不懂的话可以看前一篇《机器学习技法之神经网络》。
第二阶段是:
train with backprop on pre-trained NNet to fine-tune all { w i j ( ℓ ) } \text { train with backprop on pre-trained NNet to fine-tune all } \left\{ w _ { i j } ^ { ( \ell ) } \right\} train with backprop on pre-trained NNet to fine-tune all {wij(ℓ)}
即以预训练获取的权值作为初始值,然后使用反向传播算法进行迭代优化。
自编码器(Autoencoder)
信息保留式编码(Information-Preserving Encoding)
实际上每一层神经元的特征转换类似于编码过程(或者说转换表现形式),如果经过编码后,表现形式改变(different representation),但是代表的信息不变(same info)的话,便将之称为信息保留式编码(Information-Preserving Encoding)。所以经过信息保留式编码后的可以准确的解码为原来的表现形式。
那么现在的想法就是使用这种编码形式实现预训练,获取初始权值。
信息保留式神经网络(Information-Preserving Neural Net)
假设当前需求的神经网络只有一层隐含层,那么这种编码形式的神经网络结构图如下:
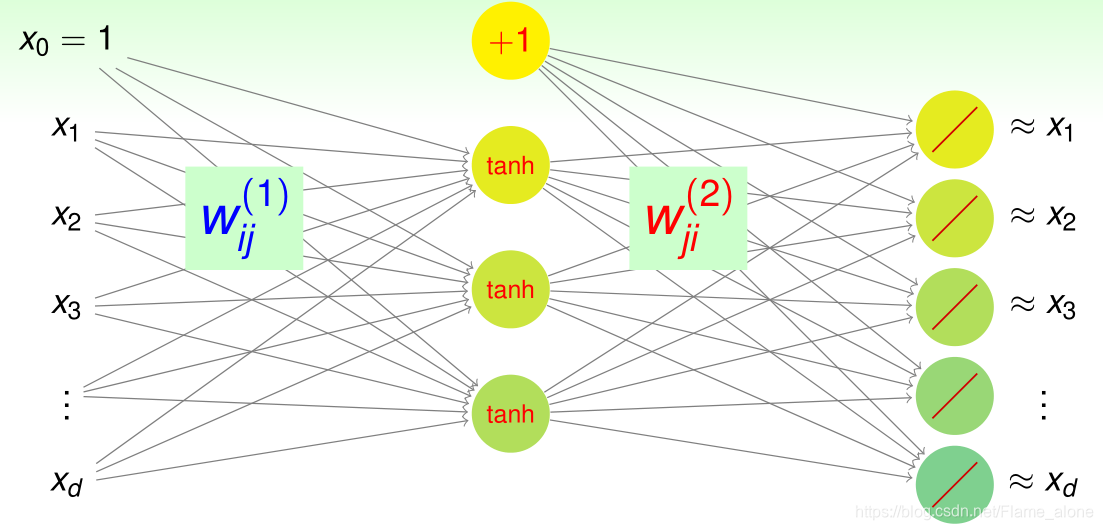
这种以
d
−
d
~
−
d
NNet with goal
g
i
(
x
)
≈
x
i
d - \tilde { d } - d \text { NNet with goal } g _ { i } ( \mathbf { x } ) \approx x _ { i }
d−d~−d NNet with goal gi(x)≈xi 为结构形式的神经网络叫做自编码器(Autoencoder)。实际上就是在学习一个逼近恒等(自身)的函数(approximate identity function),identity 意思为将某个东西对应到它本身。
那么这次称编码权重(encoding weights)为: w i j ( 1 ) \mathbf{w}^{(1)}_{ij} wij(1),解码权重(decoding weights)为: w i j ( 2 ) \mathbf{w}^{(2)}_{ij} wij(2)
逼近恒等函数(Approximating Identity Function)
这种函数的意义是:这种逼近过程会使用到(仰赖)一些已获得样本数据(observed data)中的隐藏结构(hidden structures),
对于监督学习,这种潜在的结构(hidden structure,比如说进行文字识别时学到的笔画)可以用于作为合理的特征转换 Φ ( x ) \Phi(\mathbf{x}) Φ(x)( reasonable transform)。这种潜在结构等于是原数据的信息表示(‘informative’ representation)。
对于无监督学习,自编码器更像是在学习数据的类型表示(‘typical’ representation of data)。在密度估计(density estimation)中,如果这类数据越多,那么这类数据的逼近越好,也就是自编码器的误差越少。在异常检测(outlier detection)中,如果自编码器的误差很小,那么代表该数据属于原来的训练数据。
所以说自编码器(autoencoder)是通过逼近恒等函数实现的一种表示学习(representation-learning through approximating identity function)。
基本的自编码器(Basic Autoencoder)
Basic Autoencoder 的表现形式为:
d − d ~ − d NNet with error function ∑ i = 1 d ( g i ( x ) − x i ) 2 d - \tilde { d } - d \text { NNet with error function } \sum _ { i = 1 } ^ { d } \left( g _ { i } ( \mathbf { x } ) - x _ { i } \right) ^ { 2 } d−d~−d NNet with error function i=1∑d(gi(x)−xi)2
有以下特点:
- backprop easily applies; shallow and easy to train
反向传播算法容易应用,隐含层少易于训练 - usually
d
>
d
~
d > \tilde { d }
d>d~ : compressed representation
一般情况下隐含层神经元个数小于输入(或输出),从而达到一种数据压缩的效果 - 数据的格式为: { ( x 1 , y 1 = x 1 ) , ( x 2 , y 2 = x 2 ) , … , ( x N , y N = x N ) } \left\{ \left( \mathbf { x } _ { 1 } , \mathbf { y } _ { 1 } = \mathbf { x } _ { 1 } \right) , \left( \mathbf { x } _ { 2 } , \mathbf { y } _ { 2 } = \mathbf { x } _ { 2 } \right) , \ldots , \left( \mathbf { x } _ { N } , \mathbf { y } _ { N } = \mathbf { x } _ { N } \right) \right\} {(x1,y1=x1),(x2,y2=x2),…,(xN,yN=xN)},所以也被用于无监督学习(categorized as unsupervised learning technique)。
- 有时候加入约束条件 w i j ( 1 ) = w j i ( 2 ) w _ { i j } ^ { ( 1 ) } = w _ { j i } ^ { ( 2 ) } wij(1)=wji(2) 作为一种正则化,但是在计算梯度时会更复杂。
其中 w i j ( 1 ) w _ { i j } ^ { ( 1 ) } wij(1) 用作预训练权重。
那么使用自编码器进行预训练的过程为:
第一阶段是:
for
ℓ
=
1
,
…
,
L
.
pre-train
{
w
i
j
(
ℓ
)
}
assuming
w
∗
(
1
)
,
…
w
∗
(
ℓ
−
1
)
fixed
\text { for } \ell = 1 , \ldots , L . \text { pre-train } \left\{ w _ { i j } ^ { ( \ell ) } \right\} \text { assuming } w _ { * } ^ { ( 1 ) } , \ldots w _ { * } ^ { ( \ell - 1 ) } \text { fixed }
for ℓ=1,…,L. pre-train {wij(ℓ)} assuming w∗(1),…w∗(ℓ−1) fixed
by training basic autoencoder on
{
x
n
(
ℓ
−
1
)
}
with
d
~
=
d
(
ℓ
)
\text { by training basic autoencoder on } \left\{ \mathbf { x } _ { n } ^ { ( \ell - 1 ) } \right\} \text { with } \tilde { d } = d ^ { ( \ell ) }
by training basic autoencoder on {xn(ℓ−1)} with d~=d(ℓ)
实际上就是一层一层的训练,这里有一个疑问为什么不一起训练,是复杂度问题吗?
第二阶段是:
train with backprop on pre-trained NNet to fine-tune all { w i j ( ℓ ) } \text { train with backprop on pre-trained NNet to fine-tune all } \left\{ w _ { i j } ^ { ( \ell ) } \right\} train with backprop on pre-trained NNet to fine-tune all {wij(ℓ)}
当然自编码的实现由正则化规则和不同的结构( different architectures and regularization schemes)而丰富多样。
降噪自编码器(Denoising Autoencoder)
下面学习一种新的正则化技术。
过拟合的成因一般有三种:数据量过小,噪声过大,算法过于强大。
那么现在提出一种降噪模型,什么意思呢?
将下述形式的样本数据(将原数据和人工噪声混合数据作为输入,将原数据作为输出)输入自编码器中:
{ ( x ~ 1 , y 1 = x 1 ) , ( x ~ 2 , y 2 = x 2 ) , … , ( x ~ N , y N = x N ) } where x ~ n = x n + artificial noise \begin{array} { c } \left\{ \left( \tilde { \mathbf { x } } _ { 1 } , \mathbf { y } _ { 1 } = \mathbf { x } _ { 1 } \right) , \left( \tilde { \mathbf { x } } _ { 2 } , \mathbf { y } _ { 2 } = \mathbf { x } _ { 2 } \right) , \ldots , \left( \tilde { \mathbf { x } } _ { N } , \mathbf { y } _ { N } = \mathbf { x } _ { N } \right) \right\} \\ \text { where } \tilde { \mathbf { x } } _ { n } = \mathbf { x } _ { n } + \text { artificial noise } \end{array} {(x~1,y1=x1),(x~2,y2=x2),…,(x~N,yN=xN)} where x~n=xn+ artificial noise
训练出模型:
g ( x ~ ) ≈ x g ( \tilde { x } ) \approx x g(x~)≈x
人工的噪声或者说 hint(例如旋转图像,缩小图像) 常常用于神经网络或者其他模型。
主成分分析(Principal Component Analysis)
线性自编码器假设函数(Linear Autoencoder Hypothesis)
对于一个线性神经网络模型来说,这里则不需要 tanh 函数了,也就是说
h k ( x ) = ∑ j = 0 d ~ w j k ( 2 ) ( ∑ i = 0 d w i j ( 1 ) x i ) h _ { k } ( \mathbf { x } ) = \sum _ { j = 0 } ^ { \tilde { d } } w _ { j k } ^ { ( 2 ) } \left( \sum _ { i = 0 } ^ { d } w _ { i j } ^ { ( 1 ) } x _ { i } \right) hk(x)=j=0∑d~wjk(2)(i=0∑dwij(1)xi)
现在考虑三个特殊条件:
- 为了简化,先不考虑 x 0 x_0 x0,让输入和输出个数一样 ,也就是
h k ( x ) = ∑ j = 0 d ~ w j k ( 2 ) ( ∑ i = 1 d w i j ( 1 ) x i ) h _ { k } ( \mathbf { x } ) = \sum _ { j = 0 } ^ { \tilde { d } } w _ { j k } ^ { ( 2 ) } \left( \sum _ { i = 1 } ^ { d } w _ { i j } ^ { ( 1 ) } x _ { i } \right) hk(x)=j=0∑d~wjk(2)(i=1∑dwij(1)xi)
-
假设 d ~ < d \tilde { d } < d d~<d,以确保非零解(non-trivial solution),因为当 d ~ > = d \tilde { d } >= d d~>=d 可以想象出权重向量是非常稀疏的。
-
加入前面提及的正则化约束条件 w i j ( 1 ) = w j i ( 2 ) = w i j w _ { i j } ^ { ( 1 ) } = w _ { j i } ^ { ( 2 ) } = w _ { i j } wij(1)=wji(2)=wij
h k ( x ) = ∑ j = 0 d ~ w k j ( ∑ i = 1 d w i j x i ) h _ { k } ( \mathbf { x } ) = \sum _ { j = 0 } ^ { \tilde { d } } w _ { k j } \left( \sum _ { i = 1 } ^ { d } w _ { i j } x _ { i } \right) hk(x)=j=0∑d~wkj(i=1∑dwijxi)
同时可以获取权重矩阵 W = [ w i j ] of size d × d ~ \mathrm { W } = \left[ w _ { i j } \right] \text { of size } d \times \tilde { d } W=[wij] of size d×d~,那么线性自编码器的假设函数为:
h ( x ) = W W T x \mathbf { h } ( \mathbf { x } ) = \mathrm { WW } ^ { T } \mathbf { x } h(x)=WWTx
线性自编码器的误差函数(Linear Autoencoder Error Function)
可以根据平方误差写出误差函数:
E i n ( h ) = E i n ( W ) = 1 N ∑ n = 1 N ∥ x n − W W T x n ∥ 2 with d × d ~ matrix W E _ { \mathrm { in } } ( \mathbf { h } ) = E _ { \mathrm { in } } ( \mathrm { W } ) = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \left\| \mathbf { x } _ { n } - \mathrm { WW } ^ { T } \mathbf { x } _ { n } \right\| ^ { 2 } \text { with } d \times \tilde { d } \text { matrix } \mathrm { W } Ein(h)=Ein(W)=N1n=1∑N∥∥xn−WWTxn∥∥2 with d×d~ matrix W
但是这里有一点,需要计算关于 W \mathrm { W } W 的四次多项式。
这里用到一些线性代数的知识,特征分解(eigen-decompose):
W W T = V Γ V T \mathrm { WW } ^ { T } = \mathrm { V } \Gamma \mathrm { V } ^ { T } WWT=VΓVT
W \mathrm { W } W 是正规矩阵的充要条件是:存在酉矩阵,使得 W \mathrm { W } W 酉相似于对角矩阵
其中
- V \mathrm { V } V 是 d × d d \times d d×d 的正交(orthogonal)矩阵(又叫酉矩阵),并且 V V T = V T V = I d \mathrm { VV } ^ { T } = \mathrm { V } ^ { T } \mathrm { V } = \mathrm { I } _ { d } VVT=VTV=Id。
- Γ \Gamma Γ 为对角矩阵,且只有 ≤ d ~ \leq \tilde d ≤d~ 个非零项。
W W T x n = V Γ V T x n \mathrm { WW } ^ { T } \mathbf { x } _ { n } = \mathrm { V } \Gamma \mathrm { V } ^ { T } \mathbf { x } _ { n } WWTxn=VΓVTxn 中的各个参数的物理意义:
- V T \mathrm { V } ^ { T } VT :将数据 x n \mathbf { x } _ { n } xn 进行坐标转换(旋转和镜像)。
- Γ \Gamma Γ :令上一步获取的矩阵中 ≥ d − d ~ \geq d -\tilde d ≥d−d~ 个参数为零,并缩放其他参数。
- V \mathrm { V } V :将上一步获取的数据,根据系数和基向量进行坐标重构(反旋转和反镜像)。
那么根据这个物理意义可以写出如下表示:
x n = V I V T x n \mathbf { x } _ { n } = \mathrm { VIV } ^ { T } \mathbf { x } _ { n } xn=VIVTxn
也就是说只进行旋转和反旋转,并不对参数进行设成零或放缩操作。
那么误差函数最小化问题便转换为了 Γ \Gamma Γ 和 V \mathrm { V } V 的优化问题。
也就是说:
min V min Γ 1 N ∑ n = 1 N ∥ VIV T x n ⏟ x n − V Γ V T x n ⏟ W W ⊤ x n ∥ 2 \min _ { \mathbf { V } } \min _ { \Gamma } \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \| \underbrace { \operatorname { VIV } ^ { T } \mathbf { x } _ { n } } _ { \mathbf { x } _ { n } } - \underbrace { \operatorname { V } \Gamma \mathbf { V } ^ { T } \mathbf { x } _ { n } } _ { \mathbf { W } \mathbf { W } ^ { \top } \mathbf { x } _ { n } } \| ^ { 2 } VminΓminN1n=1∑N∥xn VIVTxn−WW⊤xn VΓVTxn∥2
直观上来说由于 V \mathrm { V } V 只是做了一个旋转动作,所以并不会影响向量的长度,所以将其拿掉。
min V min Γ 1 N ∑ n = 1 N ∥ ( I − Γ ) V T x n ∥ 2 \min _ { \mathbf { V } } \min _ { \Gamma } \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \| \left( I - \Gamma \right) {\mathbf { V } ^ { T } \mathbf { x } _ { n } } \| ^ { 2 } VminΓminN1n=1∑N∥(I−Γ)VTxn∥2
先不考虑 V \mathrm { V } V,可以改写为:
min Γ ∑ ∥ ( I − Γ ) ( some vector ) ∥ 2 \min _ { \Gamma } \sum \| ( \mathrm { I } - \Gamma ) ( \text { some vector } ) \| ^ { 2 } Γmin∑∥(I−Γ)( some vector )∥2
由于 I − Γ \mathrm { I }-\Gamma I−Γ 是一个对角矩阵,那么为了满足上述优化问题,那么该对角矩阵应该有尽可能多的零值。由于 Γ \Gamma Γ 中有 ≤ d ~ \leq \tilde d ≤d~ 非零值,那么也就是说最多有 d ~ \tilde d d~ 个 1 使得 I − Γ \mathrm { I }-\Gamma I−Γ 零值最多。
那么现在先假设
Γ = [ I d ~ 0 0 0 ] \Gamma = \left[ \begin{array} { c c } \mathrm { I } _ { \tilde { d} } & 0 \\ 0 & 0 \end{array} \right] Γ=[Id~000]
然后在求取 V \mathrm { V } V 的值来满足这一条件,那么根据 I − Γ = [ 0 0 0 I d − d ~ ] \mathrm { I }-\Gamma = \left[ \begin{array} { c c } 0 & 0 \\ 0 & \mathbf { I } _ { d - \tilde { d } } \end{array} \right] I−Γ=[000Id−d~] 的最优解将优化问题改为:
min V ∑ n = 1 N ∥ [ 0 0 0 I d − d ~ ] V T x n ∥ 2 ≡ max v ∑ n = 1 N ∥ [ I α ~ 0 0 0 ] V T x n ∥ 2 \min _ { \mathbf { V } } \sum _ { n = 1 } ^ { N } \left\| \left[ \begin{array} { c c } 0 & 0 \\ 0 & \mathbf { I } _ { d - \tilde { d } } \end{array} \right] \mathbf { V } ^ { T } \mathbf { x } _ { n } \right\| ^ { 2 } \equiv \max _ { \mathbf { v } } \sum _ { n = 1 } ^ { N } \left\| \left[ \begin{array} { c c } \mathbf { I } _ { \tilde { \alpha } } & 0 \\ 0 & 0 \end{array} \right] \mathbf { V } ^ { T } \mathbf { x } _ { n } \right\| ^ { 2 } Vminn=1∑N∥∥∥∥[000Id−d~]VTxn∥∥∥∥2≡vmaxn=1∑N∥∥∥∥[Iα~000]VTxn∥∥∥∥2
首先假设 d ~ = 1 \tilde d = 1 d~=1,那么只有 V T \mathrm { V }^{T} VT 的第一行 v T \mathrm{v}^T vT 被用到了:
max v ∑ n = 1 N v T x n x n T v subject to v T v = 1 \max _ { \mathbf { v } } \sum _ { n = 1 } ^ { N } \mathbf { v } ^ { T } \mathbf { x } _ { n } \mathbf { x } _ { n } ^ { T } \mathbf { v } \text { subject to } \mathbf { v } ^ { T } \mathbf { v } = 1 vmaxn=1∑NvTxnxnTv subject to vTv=1
那么最优解用拉格朗日乘数法可以表示为:
∑ n = 1 N x n x n T v = λ v \sum _ { n = 1 } ^ { N } \mathbf { x } _ { n } \mathbf { x } _ { n } ^ { T } \mathbf { v } = \lambda \mathbf { v } n=1∑NxnxnTv=λv
可以看出 v \mathbf { v } v 是 X T X X ^ { T } X XTX 的一个特征向量,其中 X T = [ x 1 , ⋯ , x N ] X^T = [\mathbf x_1,\cdots,\mathbf x_N] XT=[x1,⋯,xN]。那么最优的 v \mathbf { v } v 应该是最大特征值对应的特征向量。
那么对于任意的 d ~ \tilde d d~, { v j } j = 1 d ~ \left\{ \mathbf { v } _ { j } \right\} _ { j = 1 } ^ { \tilde { d} } {vj}j=1d~ 应该是 Top d ~ \tilde d d~ 特征值对于的特征向量,而 w j \mathbf { w }_j wj 的组成基本上就是这些特征向量,也就是说:
optimal { w j } = { v j with [ [ γ j = 1 ] ] } = top eigenvectors \text { optimal } \left\{ \mathbf { w } _ { j } \right\} = \left\{ \mathbf { v } _ { j } \text { with } \left[ \kern-0.15em\left[ \gamma _ { j } = 1 \right] \kern-0.15em \right]\right\} = \text { top eigenvectors } optimal {wj}={vj with [[γj=1]]}= top eigenvectors
线性自编码器:实际上就是投影到这些与数据 { x n } \left\{ \mathbf { x } _ { n } \right\} {xn} 最匹配的几个正交向量。
线性自编码器的本质就是,向这些垂直的向量上做投影后,保证它们的和最大。
maximize ∑ ( maginitude after projection ) 2 \text { maximize } \sum ( \text { maginitude after projection } ) ^ { 2 } maximize ∑( maginitude after projection )2
实现流程为:
1. calculate d ~ top eigenvectors w 1 , w 2 , … , w d ~ of X T X 2. return feature transform Φ ( x ) = W ( x ) \begin{array} { l }\qquad \text { 1. calculate } \tilde { d } \text { top eigenvectors } \mathbf { w } _ { 1 } , \mathbf { w } _ { 2 } , \ldots , \mathbf { w } _ { \tilde { d } } \text { of } \mathbf { X } ^ { T } \mathbf { X } \\ \qquad \text { 2. return feature transform } \mathbf { \Phi } ( \mathbf { x } ) = \mathbf { W } ( \mathbf { x } ) \end{array} 1. calculate d~ top eigenvectors w1,w2,…,wd~ of XTX 2. return feature transform Φ(x)=W(x)
主成分分析(PCA)的实现与之类似,其本质是做完投影后再这些投影上的变化量(variance)最大,也就是说具有多样性,即找出那些差异性较大的特征,也就是相关性较小的特征将被留下,如果两个特征的相关性较大那么尽可能只留其中一个:
maximize ∑ ( variance after projection ) \text { maximize } \sum ( \text { variance after projection } ) maximize ∑( variance after projection )
所以 PCA 经常用于降维。
PCA的具体实现流程 :
1. let x ‾ = 1 N ∑ n = 1 N x n , and let x n ← x n − x ‾ 2. calculate d ~ top eigenvectors w 1 , w 2 , … , w d ~ of X T X 3. return feature transform Φ ( x ) = W ( x − x ‾ ) \begin{array} { l }\qquad \text { 1. let }\overline { \mathbf { x } } = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \mathbf { x } _ { n } , \text { and let } \mathbf { x } _ { n } \leftarrow \mathbf { x } _ { n } - \overline { \mathbf { x } } \\ \qquad \text { 2. calculate } \tilde { d } \text { top eigenvectors } \mathbf { w } _ { 1 } , \mathbf { w } _ { 2 } , \ldots , \mathbf { w } _ { \tilde { d } } \text { of } \mathbf { X } ^ { T } \mathbf { X } \\ \qquad \text { 3. return feature transform } \mathbf { \Phi } ( \mathbf { x } ) = \mathbf { W } ( \mathbf { x } - \overline { \mathbf { x } } ) \end{array} 1. let x=N1∑n=1Nxn, and let xn←xn−x 2. calculate d~ top eigenvectors w1,w2,…,wd~ of XTX 3. return feature transform Φ(x)=W(x−x)
特征值和特征向量的意义:图片压缩
以图片压缩为例,比如说,有下面这么一副 512 × 512 512\times512 512×512 的图片(方阵才有特征值,所以找了张正方形的图):

这个图片可以放到一个矩阵里面去,就是把每个像素的颜色值填入到一个 512 × 512 512\times512 512×512 的 A 矩阵中。
加入该矩阵可以对角化的话,那么可以做如下特征分解(谱分解):
A = P Λ P − 1 A = P \Lambda P ^ { - 1 } A=PΛP−1
其中, Λ \Lambda Λ 是对角阵,对角线上是从大到小排列的特征值。
在
Λ
\Lambda
Λ 中只保留前面50个的特征值(也就是最大的50个,其实也只占了所有特征值的百分之十),其它的都填0,重新计算矩阵后,恢复为下面这样的图像:

效果还可以,其实一两百个特征值之和可能就占了所有特征值和的百分之九十了,其他的特征值都可以丢弃了。















 7007
7007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











