







 本文介绍了NLTK,一个用于Python的领先平台,它提供丰富的语言处理工具,包括语料库、词典资源、文本处理库和API,适用于各种用户群体。文章还展示了如何使用NLTK进行基本操作,如分词、标注、命名实体识别和句法分析。
本文介绍了NLTK,一个用于Python的领先平台,它提供丰富的语言处理工具,包括语料库、词典资源、文本处理库和API,适用于各种用户群体。文章还展示了如何使用NLTK进行基本操作,如分词、标注、命名实体识别和句法分析。
Natural Language Toolkit
NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.
NLTK是构建Python程序以处理人类语言数据的领先平台。它为50多个语料库和词汇资源(如WordNet)提供了易于使用的界面,以及一套用于分类、标记化、词干、标记、解析和语义推理的文本处理库,工业级NLP库的包装器,以及一个活跃的讨论论坛。
Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike. NLTK is available for Windows, Mac OS X, and Linux. Best of all, NLTK is a free, open source, community-driven project.
得益于一本介绍编程基础知识和计算语言学主题的实践指南,以及全面的API文档,NLTK适合语言学家、工程师、学生、教育工作者、研究人员和行业用户。NLTK可用于Windows、Mac OS X和Linux。最棒的是,NLTK是一个免费的、开源的、社区驱动的项目。
NLTK has been called “a wonderful tool for teaching, and working in, computational linguistics using Python,” and “an amazing library to play with natural language.”
NLTK被称为“使用Python教授和研究计算语言学的绝佳工具”,以及“使用自然语言的惊人库”
Natural Language Processing with Python provides a practical introduction to programming for language processing. Written by the creators of NLTK, it guides the reader through the fundamentals of writing Python programs, working with corpora, categorizing text, analyzing linguistic structure, and more. The online version of the book has been been updated for Python 3 and NLTK 3. (The original Python 2 version is still available at https://www.nltk.org/book_1ed.)
Python的自然语言处理提供了语言处理编程的实用介绍。它由NLTK的创建者编写,引导读者了解编写Python程序、使用语料库、对文本进行分类、分析语言结构等的基本知识。这本书的在线版本已经针对Python3和NLTK3进行了更新。(Python 2的原始版本仍在https://www.nltk.org/book_1ed.)
Some simple things you can do with NLTK
Tokenize and tag some text:
>>> import nltk
>>> sentence = """At eight o'clock on Thursday morning
... Arthur didn't feel very good."""
>>> tokens = nltk.word_tokenize(sentence)
>>> tokens
['At', 'eight', "o'clock", 'on', 'Thursday', 'morning',
'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
>>> tagged = nltk.pos_tag(tokens)
>>> tagged[0:6]
[('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'),
('Thursday', 'NNP'), ('morning', 'NN')]
Identify named entities:
>>> entities = nltk.chunk.ne_chunk(tagged)
>>> entities
Tree('S', [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'),
('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'),
Tree('PERSON', [('Arthur', 'NNP')]),
('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'),
('very', 'RB'), ('good', 'JJ'), ('.', '.')])
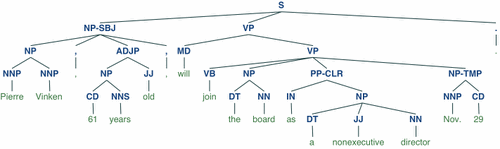
Display a parse tree:
>>> from nltk.corpus import treebank
>>> t = treebank.parsed_sents('wsj_0001.mrg')[0]
>>> t.draw()
NB. If you publish work that uses NLTK, please cite the NLTK book as follows:
Bird, Steven, Edward Loper and Ewan Klein (2009), Natural Language Processing with Python. O’Reilly Media Inc.


















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











