









本节小结
本小节介绍了通过生成式方式求解类的后验概率的方法。通过对类先验概率 p ( C k ) p(C_k) p(Ck)和类条件概率 p ( x ∣ C k ) p(\textbf{x}|C_k) p(x∣Ck)分别建模,再根据贝叶斯定理 p ( C k ∣ x ) = p ( x ∣ C k ) p ( C k ) ∑ j p ( x ∣ C j ) p ( C j ) p(C_k|\textbf{x})=\frac{p(\textbf{x}|C_k)p(C_k)}{\sum_{j}p(\textbf{x}|C_j)p(C_j)} p(Ck∣x)=∑jp(x∣Cj)p(Cj)p(x∣Ck)p(Ck)得出类的后验概率。通过对类条件概率 p ( x ∣ C k ) p(\textbf{x}|C_k) p(x∣Ck)作简单假设,即得到了线性决策边界的模型。
在进行具体介绍之前,先对后验概率做下转换。二分类情形下,
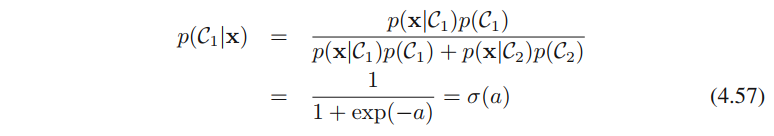
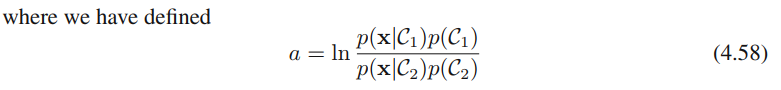
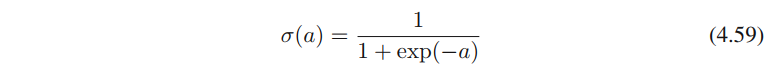
多分类的情形,
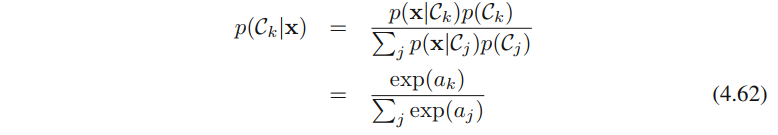
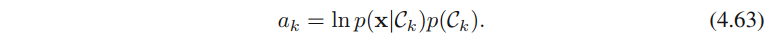
为什么要把后验概率
p
(
C
1
∣
x
)
p(C_1|\textbf{x})
p(C1∣x)转换成sigmoid形式(公式4.57)呢?转换成公式4.57的形式,当
a
a
a为
x
\textbf{x}
x的线性函数时,即可得出决策面是线性的。转换成softmax(公式4.62)的原因与之类似。
输入变量x按类型分,有连续型和离散型,4.2.1、4.2.2、4.2.3节分别做了介绍。
4.2.1介绍了连续型输入变量下的生成式模型。首先假定每个类条件概率分布为高斯分布并且协方差矩阵相同(注意:有了这个假定,才有了决策边界为线性),分布的具体形式为
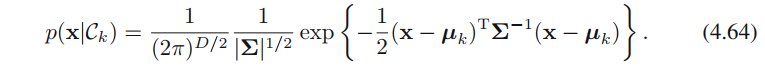
对二分类的情形,根据公式4.57和4.58,可得
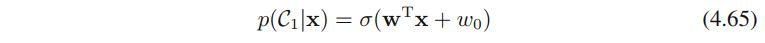
其中
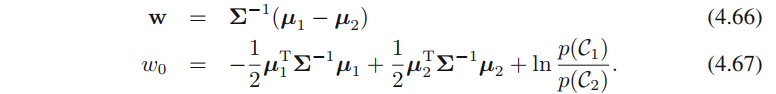
最终求得的决策边界对应于后验概率
p
(
C
k
∣
x
)
p(C_k|\textbf{x})
p(Ck∣x)(公式4.65)为常数的决策⾯,则
w
T
x
+
w
0
\textbf{w}^T\textbf{x}+w_0
wTx+w0为常数,从⽽决策边界在输⼊空间是线性的。多分类的情形与二分类类似。
4.2.2节对4.2.1节的模型通过最大似然法求解模型参数。需要确定的参数有类先验概率
p
(
C
k
)
p(C_k)
p(Ck)、类条件概率分布的均值
μ
k
\mu_{k}
μk、共同的协方差矩阵
Σ
\Sigma
Σ。最大似然的结果与直观意义相符,
p
(
C
k
)
p(C_k)
p(Ck)为类
C
k
C_k
Ck的样本数占所有类别的比例,
μ
k
\mu_{k}
μk的最大似然解为类
C
k
C_k
Ck的所有样本对应的x值的均值,
Σ
\Sigma
Σ的最大似然解为与每个类分别有关系的协⽅差矩阵求加权平均(最后半句的理解)。
需要注意的是,4.2.1节是通过类的后验概率来引入决策边界,4.2.2节的最大似然是联合概率分布
(
x
,
C
k
)
(\textbf{x},C_k)
(x,Ck)对应的参数的最大似然。
4.2.3节介绍了离散变量的模型。假定输入变量x的每个分量是独立的。假如每个分量都是二值变量,多分类下的条件概率分布为
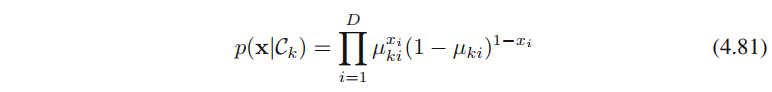
根据公式4.63,可得
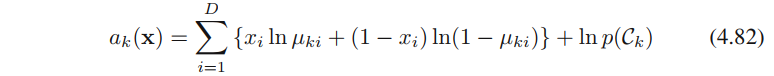
公式4.82是输入变量x的线性函数,从而决策面是线性的。
当每个分量是多值变量(多于2个值)时也可得出类似的结果。类似可得二分类下的情形。
本章并未对离散型输入变量下参数的求解方法进行介绍,实际上方法与4.2.2节类似,通过最大似然方法即可求解。
互动话题
-
x为连续型输入变量时,4.2.1小节假定每个类条件概率分布为高斯分布并且协方差矩阵相同,这个假定是否太强?
-
x为连续型输入变量时,4.2.3小节假定x的每个分量为独立的,这个假定是否太强。如果不满足这个假定会如何?
-
4.2.2节中似然函数的理解。
对于⼀个来⾃类别 C 1 C_1 C1的数据点 x n \textbf{x}_n xn,我们有 t n t_n tn = 1,因此
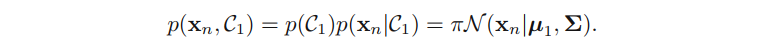
类似地,对于类别 C 2 C_2 C2,我们有 t n t_n tn = 0,因此
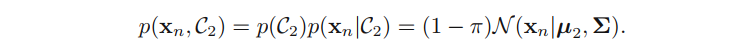
于是似然函数为
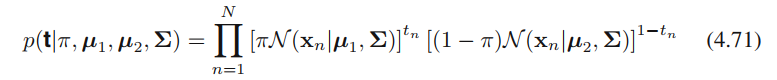
p ( t ∣ π , μ 1 , μ 2 , Σ ) p(\textbf{t}|\pi,\mu_1,\mu_2,\Sigma) p(t∣π,μ1,μ2,Σ)应当换成 p ( t,X ∣ π , μ 1 , μ 2 , Σ ) p(\textbf{t,X}|\pi,\mu_1,\mu_2,\Sigma) p(t,X∣π,μ1,μ2,Σ)更合理 -
本节为什么没有像第3章一样通过最大后验或贝叶斯方法求解?
后续工作
4.2.4节指数族分布需要等复习完2.4节之后再看。















 1108
1108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









