







本文主要介绍常见的商品推荐方法和推荐系统的评价指标。
1.推荐系统概述
推荐系统是主动从大量信息中找到用户可能感兴趣的信息的工具。推荐系统的核心问题是如何实现推荐个性化、如何向用户推荐匹配度高的产品(商品)或项目,本质是通过一定的方式将用户和项目联系起来。
自从Xerox Palo Alto研究中心于1992年研发出了基于协同过滤的实验系统Tapestry以来(主要功能:利用用户的显式反馈(评分和注释),帮助用户过滤邮件,解决邮件过载问题。),随着互联网、移动技术发展,推荐系统得到了快速的发展,已经渗透到了人们的衣食住行中。
推荐系统针对不同的服务对象,可以分为基于全体用户的推荐和基于单个用户的推荐(即个性化推荐)。以电子商务为例,基于全体用户的推荐,是对所有消费者给出同样的推荐,如根据物品流行度计算的top-k个项目,推荐给所有用户。基于单个用户的推荐,是针对不同的用户给出不同的推荐结果,如根据单个用户的行为记录,推测用户的喜好,从而做出一对一的推荐。
根据推荐系统使用数据源的不同,可以将推荐系统分为以下几类(分类标准源自参考文献1):
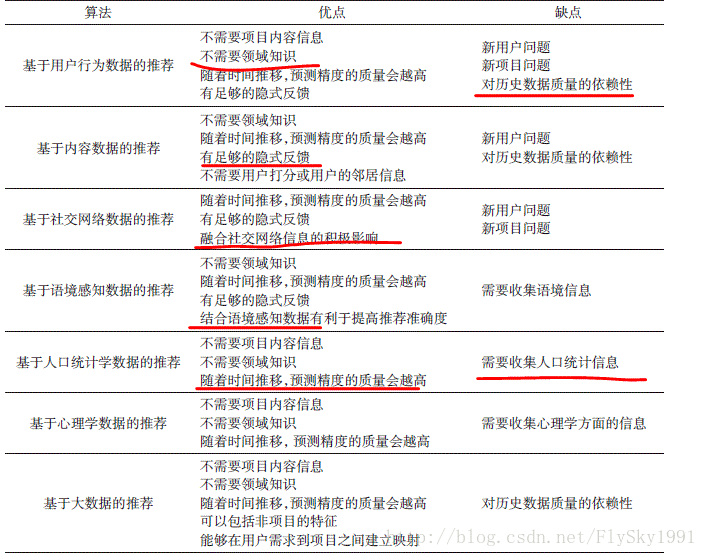
(1)基于用户行为数据的推荐
(2)基于项目内容数据的推荐
(3)基于社交网络数据的推荐
(4)基于语境感知的推荐
(5)基于人口统计学数据的推荐
(6)基于心理学数据的推荐
(7)基于大数据的推荐
上述几类推荐算法都有它的优势和不足之处,如基于用户行为数据的推荐不需要领域知识,只需要收集用户行为数据即可进行推荐,但存在冷启动问题(cold-start);基于人口统计学的推荐不需要用户的历史行为数据,能够很好地解决冷启动问题,但年龄、性别等人口统计学数据比较难以获取,并且推荐的粒度很粗(大多是针对某一类人群),单独使用无法事先完全的个性化推荐。有关上述推荐算法的优缺点详细分析,如下图所示:
2.常见的商品推荐方法
上面主要是从整体的角度介绍了下推荐系统算法的分类,下面重点介绍在电商领域常用的商品推荐方法及其优缺点和应用案例。
(1) 基于商品相似度的推荐:比如食物A和食物B,对于它们价格、味道、保质期、品牌等维度,可以计算它们的相似程度,如买了包子,很有可能顺路带一盒水饺回家。
优点:只要有商品的数据,在业务初期用户数据不多的情况下,也可以做推荐
缺点:预处理复杂,任何一件商品,有成百上千的维度,如何选取合适的维度进行计算是难题。
典型:亚马逊早期的推荐系统
(2)基于关联规则的推荐:最常见的就是通过用户购买的习惯,经典的就是“啤酒尿布”的案例,首先要做关联规则,数据量一定要充足,否则置信度太低,当数据量上升了,业内的算法有Apriori、FP-Growth等。
优点:简单易操作,上手速度快,部署起来也非常方便
缺点:需要有较多的数据,精度效果一般
典型:早期运营商的套餐推荐
(3)基于物品的协同推荐:假设物品A被小张、小明、小董买过,物品B被小红、小丽、小晨买过,物品C被小张、小明、小李买过;直观的看来,物品A和物品C的购买人群相似度更高(相对于物品B),现在我们可以对小董推荐物品C,小李推荐物品A。
优点:相对精准,结果可解释性强,副产物可以得出商品热门排序
缺点:计算复杂,数据存储瓶颈,冷门物品推荐效果差
典型:早期一号店商品推荐
(4)基于用户的协同推荐:假设用户A买过可乐、雪碧、火锅底料,用户B买过卫生纸、衣服、鞋,用户C买过火锅、果汁、七喜;直观上来看,用户A和用户C相似度更高(相对于用户B),现在我们可以对用户A推荐用户C买过的其他东西,对用户C推荐用户A买过买过的其他东西。
(5)基于模型的推荐:常用的方法有svd+、特征值分解等,将用户的购买行为的矩阵拆分成两组权重矩阵的乘积,一组矩阵代表用户的行为特征,一组矩阵代表商品的重要性,在用户推荐过程中,计算该用户在历史训练矩阵下的各商品的可能性进行推荐。
优点:精准,对于冷门的商品也有很不错的推荐效果
缺点:计算量非常大,矩阵拆分的效能及能力瓶颈一直是受约束的
典型:惠普的电脑推荐
(6)基于时序的推荐:主要应用于Twitter,Facebook,豆瓣这样的社交网站,比如说在只有赞同和反对的情况下,怎么进行评论排序。
(7)基于深度学习的推荐:现在比较火的CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)都有运用在推荐上面的例子,但是都还是试验阶段,相对比较成熟的有基于word2vec的方法。
优点:推荐效果非常精准,所需要的基础存储资源较少。
缺点:工程运用不成熟,模型训练调参技巧难。
典型:苏宁易购的会员商品推荐
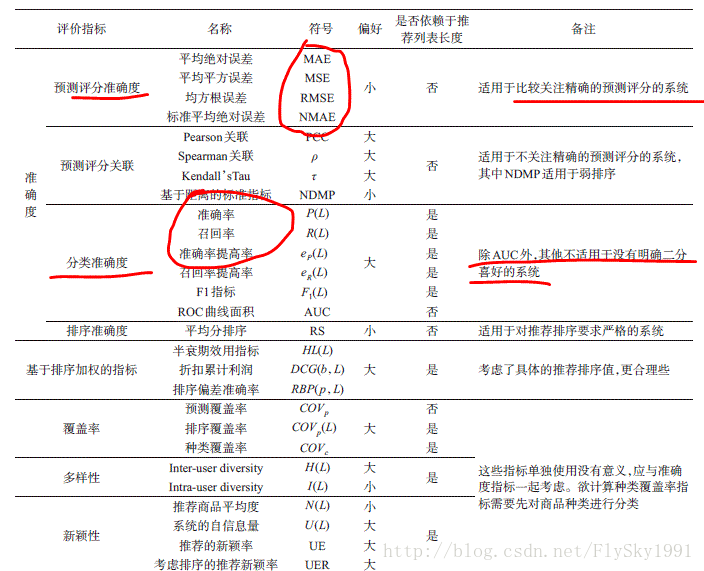
3.推荐系统评价指标
常见的推荐系统评价指标如下图所示:
Reference:
[1]朱杨勇.孙婧.推荐系统研究进展[J]。计算机科学与探索,2015,9(5):513-525
[2]深度学习在电商商品推荐中的应用 (http://www.afenxi.com/post/47739)














 2803
2803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









