







*此系列为斯坦福李飞飞团队的系列公开课“cs231n convolutional neural network for visual recognition ”的学习笔记。本文主要是对module 1 的part1 Image classification 的翻译与学习。
图像分类是指对于输入的图像,从一系列的标签中找出正确的与之对应的标签,图像分类是许多复杂的计算机视觉算法的基础。
对于计算机而言,它看到的图像可以看成是一个三维数组,其中灰度图像的宽度和高度各占一维,还有一维是RGB的组合。
几乎所有的图像分类算法都会面临以下几方面问题:
1. 观察角度会变化。
2. 物体大小会变化,观察范围会变化。
3. 变形。
4. 背景干扰。
5. 类内变化。例如,椅子的形状可以有很多种。
数据驱动方法
我们并不是去写一个算法来识别图像中的猫,而是想对待孩童一样,我们把每一个类型中大量的图片提供给计算机,然后写一个学习算法,让计算机自己学会分类。这种方法是基于数据驱动的。需要训练集和标签数据集。
图像分类过程
图像分类是为每一个数组分配一个标签。这个模式化过程如下:
-输入--训练集,有许多有标签的图像构成。
-学习--用训练集训练分类器,进行数学建模。
-评价--用未标签的新数据评价分类器的性能。正确率越高,学习的效果越好。
最近邻域分类法
此法并不是卷积网络的方法,图像分类的实践中也很少用到,但是这个方法有助于帮我们理解图像分类。
最近领域法将测试图片和训练集中的每一幅图求距离,两幅图像之间的距离是指这两幅图像中的每一个对于像素的差距之和。使用下面这个公式来求取:
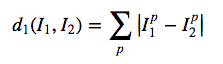
在求得测试集图像与训练集的没衣服图像的距离之后,找到距离最近的图像,将测试集图像归为此类。
输入训练集及测试集
cs231n通过函数`Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/')`导入 CIFAR-10 数据集, CIFAR-10 中有50000个训练样本,每个样本大小是32 x 32 x 3,每个样本有一个标签。此外,CIFAR-10 中还有10000个测试样本。我在网络上没有搜到`load_CIFAR10()`函数的源代码,因此需要自己动手来写一个数据导入程序。
import numpy as np
def unpickle(file):
import cPickle
fo = open(file,'rb')
dict = cPickle.load(fo)
fo.close()
return dict
def load_CIFAR10(file):
#get the training data
dataTrain = []
labelTrain = []
for i in range(1,6):
dic = unpickle(file+"\\data_batch_"+str(i))
for item in dic["data"]:
dataTrain.append(item)
for item in dic["labels"]:
labelTrain.append(item)
#get test data
dataTest = []
labelTest = []
dic = unpickle(file+"\\test_batch")
for item in dic["data"]:
dataTest.append(item)
for item in dic["labels"]:
labelTest.append(item)
return (dataTrain,labelTrain,dataTest,labelTest)
Xtr, Ytr, Xte, Yte = load_CIFAR10('C:\\Users\\Administrator\\Documents\\python Scripts\\cifar-10-batches-py')
#print "Xte:%d" %(len(dataTest))
#print "Yte:%d" %(len(labelTest))
dataTr = np.asarray(Xtr)
dataTs = np.asarray(Xte)
labelTr = np.asarray(Ytr)
labelTs = np.asarray(Yte)
print dataTr.shape
print dataTs.shape
print labelTr.shape
print labelTs.shape获取CIFAR-10 数据集的主要过程是,先将CIFAR-10 数据集的训练数据写入一个字典变量中,再将字典变量中的data和label分别拿到两个数组中去。用同样的方法获取测试数据,最后返回四个数组。
在程序最初版本里,路径中都是单斜杠,可是总是编译不通过,始终报错提示:invalid mode ('rb') or filename: 'C:\\Users\\Administrator\\Documents\\Python Scripts\\cifar-10-batches-py\test_batch'
将路径中所有的单斜杠都变成双斜杠后,编译就能通过了。
导入数据后,通过最简单的邻域聚类的方法,对图像进行分类
datatr, labeltr, datate, labelte = load_CIFAR10('C:\\Users\\Administrator\\ywj\\data\\cifar-10-python\\cifar-10-batches-py')
#print "Xte:%d" %(len(dataTest))
#print "Yte:%d" %(len(labelTest))
Xtr = np.asarray(datatr)
Xte = np.asarray(datate)
Ytr = np.asarray(labeltr)
Yte = np.asarray(labelte)
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072
print Xtr.shape
print Xte.shape
print Ytr.shape
print Yte.shape
print type(Xtr)
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in xrange(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred
nn = NearestNeighbor() # create a Nearest Neighbor classifier class
nn.train(Xtr_rows, Ytr) # train the classifier on the training images and labels
Yte_predict = nn.predict(Xte_rows) # predict labels on the test images
# and now print the classification accuracy, which is the average number
# of examples that are correctly predicted (i.e. label matches)
print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) )
KNN
用邻域分析来对CIFAR-10数据集进行图像分类的算法复杂度比较高,准确率也不高(斯坦福的讲义中为38.6%),我们可以用KNN(k-Nearest Neighbor Classifier)对图像分类的算法进行改进。在KNN中,我们找到k个与测试集距离最近的图像,通过投票,确定测试集图像的类别。之前的算法可以看作是k=1的特例。
验证集超参数优化
KNN方法需要给出参数K,如何选取最佳的参数K?通常采用的方法是尝试所有不同的可能的值,找出中间的最优解。但值得一提的是,不建议采用测试集来筛选超参数,这样会造成过拟合。建议大家只在机器学习的模型建立后使用且仅使用一次测试集。
我们可以将训练集分成两部分,一部分仍旧作为训练集,只是规模有所减小,另一部分作为验证集。以 CIFAR-10 为例,我们将原先50000张图片的训练集分为49000张图片的训练集和1000张图片的验证集,验证集用来调整超参数。
Split your training set into training set and a validation set. Use validation set to tune all hyperparameters. At the end run a single time on the test set and report performance.(将训练集划分为训练集和验证集,用验证集调整所有的超参数,最后,测试集只用一遍,用于测试模型)
交叉验证
有时,训练样本比较小,无法分割为训练集和验证集,此时可采用交叉验证的方式来调整超参数。仍旧是以 CIFAR-10 为例,我们可以将训练集的50000张图片划分成5个子集,用其中4个子集作为训练集,剩余那个作为验证集。总共有五种划分的方式。在每一种方式下,对模型进行评估。最后,在不同的组合里取平均。

邻域分类器的优缺点:
训练简单,测试复杂。
神经网络与之相反,神经网络是训练复杂,测试简单。
邻域分类器的计算复杂度很大,如何简化计算复杂度是一个研究热点。现有的降低NN计算复杂度的算法有:ANN, kdtree,k-means等。
对于低维数据而言,KNN是有时是一个不错的选择。但很少用于图像分类。通过逐个像素来比较图像,再进行分类的思路并不可取。
















 1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











