







目录
前言
之前本来是想一次性把MMDetection2好好学习一下,后来跑了Mask-RCNN模型,发现效果还是没有Facebook的Detectron2框架跑的Mask-RCNN效果好,所以准备放弃MMDetection2框架了orz,但是之前挖的坑,还是要填起来,所以这次记录一下之前训练自己数据集的步骤吧。
在这篇博客中,你将会学习如何使用你自定义的数据集对预训练模型进行inference,test以及train操作。我们将使用ballon dataset作为一个例子来描述整个过程。
基本的几个步骤如下所示:
1、准备自定义的数据集
2、准备一个配置文件
3、使用自定义的数据集对模型进行train、test、inference操作
一、准备自定义的数据集
在MMDetection中有三种方式定义一个新的数据集:
- 将数据集直接制作成COCO的格式。
- 将数据集制作成中间格式(middle format)。
- 自己重新实现一个数据集。
通常,我们比较推荐前两种方式,因为它们相比于第三种方式更加容易些。在这篇博客笔记中,我们将会给一个把数据转化为COCO格式的例子。
备注:MMDetection现在只对COCO格式的数据集提供mask AP的evaluation方法。所以,实例分割的使用者应该将自己的数据集转化为COCO格式。
(如果COCO格式的数据集自己已经准备好了,下面这一段其实可以跳过)
COCO标注格式
下面是用于实例分割任务的COCO格式中的关键字,如果想要了解更多的细节,请点击这里。
{
"images": [image],
"annotations": [annotation],
"categories": [category]
}
# 图片信息
image = {
"id": int,
"width": int,
"height": int,
"file_name": str,
}
# 标注信息
annotation = {
"id": int,
"image_id": int,
"category_id": int,
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
}
# 类别信息
categories = [{
"id": int,
"name": str,
"supercategory": str,
}]假定我们使用的是ballon dataset。在下载完这个数据集之后,我们需要实现一个函数来将下载的数据集的标签文件转化为COCO数据集的格式。然后我们使用实现好的COCO数据集导入数据进行模型的train和evaluation操作。
如果你仔细去查看一下ballon数据集,你会发现这个数据集的标注如下所示:
{'base64_img_data': '',
'file_attributes': {},
'filename': '34020010494_e5cb88e1c4_k.jpg',
'fileref': '',
'regions': {'0': {'region_attributes': {},
'shape_attributes': {'all_points_x': [1020,
1000,
994,
1003,
1023,
1050,
1089,
1134,
1190,
1265,
1321,
1361,
1403,
1428,
1442,
1445,
1441,
1427,
1400,
1361,
1316,
1269,
1228,
1198,
1207,
1210,
1190,
1177,
1172,
1174,
1170,
1153,
1127,
1104,
1061,
1032,
1020],
'all_points_y': [963,
899,
841,
787,
738,
700,
663,
638,
621,
619,
643,
672,
720,
765,
800,
860,
896,
942,
990,
1035,
1079,
1112,
1129,
1134,
1144,
1153,
1166,
1166,
1150,
1136,
1129,
1122,
1112,
1084,
1037,
989,
963],
'name': 'polygon'}}},
'size': 1115004}将ballon数据集标注信息转化为coco格式的代码如下所示:
import os.path as osp
def convert_balloon_to_coco(ann_file, out_file, image_prefix):
data_infos = mmcv.load(ann_file)
annotations = []
images = []
obj_count = 0
for idx, v in enumerate(mmcv.track_iter_progress(data_infos.values())):
filename = v['filename']
img_path = osp.join(image_prefix, filename)
height, width = mmcv.imread(img_path).shape[:2]
images.append(dict(
id=idx,
file_name=filename,
height=height,
width=width))
bboxes = []
labels = []
masks = []
for _, obj in v['regions'].items():
assert not obj['region_attributes']
obj = obj['shape_attributes']
px = obj['all_points_x']
py = obj['all_points_y']
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
x_min, y_min, x_max, y_max = (
min(px), min(py), max(px), max(py))
data_anno = dict(
image_id=idx,
id=obj_count,
category_id=0,
bbox=[x_min, y_min, x_max - x_min, y_max - y_min],
area=(x_max - x_min) * (y_max - y_min),
segmentation=[poly],
iscrowd=0)
annotations.append(data_anno)
obj_count += 1
coco_format_json = dict(
images=images,
annotations=annotations,
categories=[{'id':0, 'name': 'balloon'}])
mmcv.dump(coco_format_json, out_file)使用上面这个函数就可以将对应的标注文件转化为对应COCO数据集的格式,之后我们就可以使用这个数据集进行模型的训练和评估了。
二、准备一个配置文件
1、配置文件准备
第二步就是准备一个配置文件来保证我们的数据集可以被成功的导入。假定我们使用的模型是Mask-RCNN+FPN,我们首先需要创建一个文件夹configs/ballon/(在configs文件夹中创建一个ballon文件夹,这个命名按照自己的项目自己命名来就好了),接着在刚创建的ballon文件夹中创建一个名字叫做mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py。文件结构如下所示:
├── configs
│ └── ballon # 这个地方命名按照自己的项目来就好了
│ └── mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py # 这个地方命名也可以按照自己的项目来,只不过MMDetection有自己推荐的命名规则mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py文件的内容如下所示:
# 1、这个新的配置文件继承了基础的配置文件(下面这一行就是继承父类配置文件的意思)
_base_ = 'mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco.py'
# 2、我们需要对类别数进行一下修改 num_classes的数目按照自己项目来
# 注意一下num_classes填写的数目不包括背景(例如如果你是总共32个类别,加上背景33个类别,这个地方只需要填32就好了)
model = dict(
roi_head=dict(
bbox_head=dict(num_classes=1),
mask_head=dict(num_classes=1)))
# 3、更改数据集的参数
dataset_type = 'CocoDataset' #数据集的格式类型COCODataset 它会按照COCO的格式来读取导入数据
classes = ('balloon',) # 自己数据集中各个类别的名称(背景的名称不用写上去)
data = dict(
samples_per_gpu=2, #每块GPU上的sample的个数,batch_size = gpu数目*samples_per_gpu
workers_per_gpu=2, #每块GPU上的workers的个数
train=dict(
img_prefix='balloon/train/', #自己转为COCO数据集中train文件夹路径
classes=classes,
ann_file='balloon/train/annotation_coco.json'), #自己转化为COCO数据集train中的标签文件路径
val=dict(
img_prefix='balloon/val/', #自己转为COCO数据集中val文件夹路径
classes=classes,
ann_file='balloon/val/annotation_coco.json'), #自己转为COCO数据集中val中标签文件路径
# 这个地方的测试集信息和val是一样的,如果自己单独还做了测试集,可以改成自己测试集的路径,没有的话,就和上面val保持一致。
test=dict(
img_prefix='balloon/val/', #自己转为COCO数据集中val文件夹路径
classes=classes,
ann_file='balloon/val/annotation_coco.json')) #自己转为COCO数据集中val中标签文件路径
# 4、设置优化器的学习率
# 因为模型默认的是8块GPU,每块gpu的sample为2,所以它的学习率是0.02
# 如果你是单卡,samples_per_gpu=1 相当于总batch size=1,那这个地方lr= 0.02/16 = 0.00125
# 如果你是单卡,samples_per_gpu=2 相当于总batch size=2, 那这个地方lr= 0.02/4 = 0.005
#...依此类推
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
# 5、使用预训练的Mask RCNN model来获取更高的精度(从github上clone下来的项目里面是没有checkpoints文文件夹的,需要自己创建以及下载相应的预训练文件,详情请看我下面的步骤)
load_from = 'checkpoints/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth'2、预训练文件准备
因为配置文件中需要导入预训练的模型(不导入也可以,不导入就将配置文件中load_from这个一行去掉就好了,或者load_from=None),但是我们从github上clone下来的这个项目是不包含checkpoints文件的,所以我们需要自己创建./checkpoints文件夹,并下载自己所需的预训练文件。
那预训练模型到哪去下载呢?
我们以Mask-RCNN为例,打开./configs/mask_rcnn/README.md文件,每个模型都会有一个README.md文件的(如果你是用Fast-RCNN模型那就到Faster-RCNN的文件夹中去找),在README.md文件中可以找到自己所需的checkpoints下载地址,如下图所示:
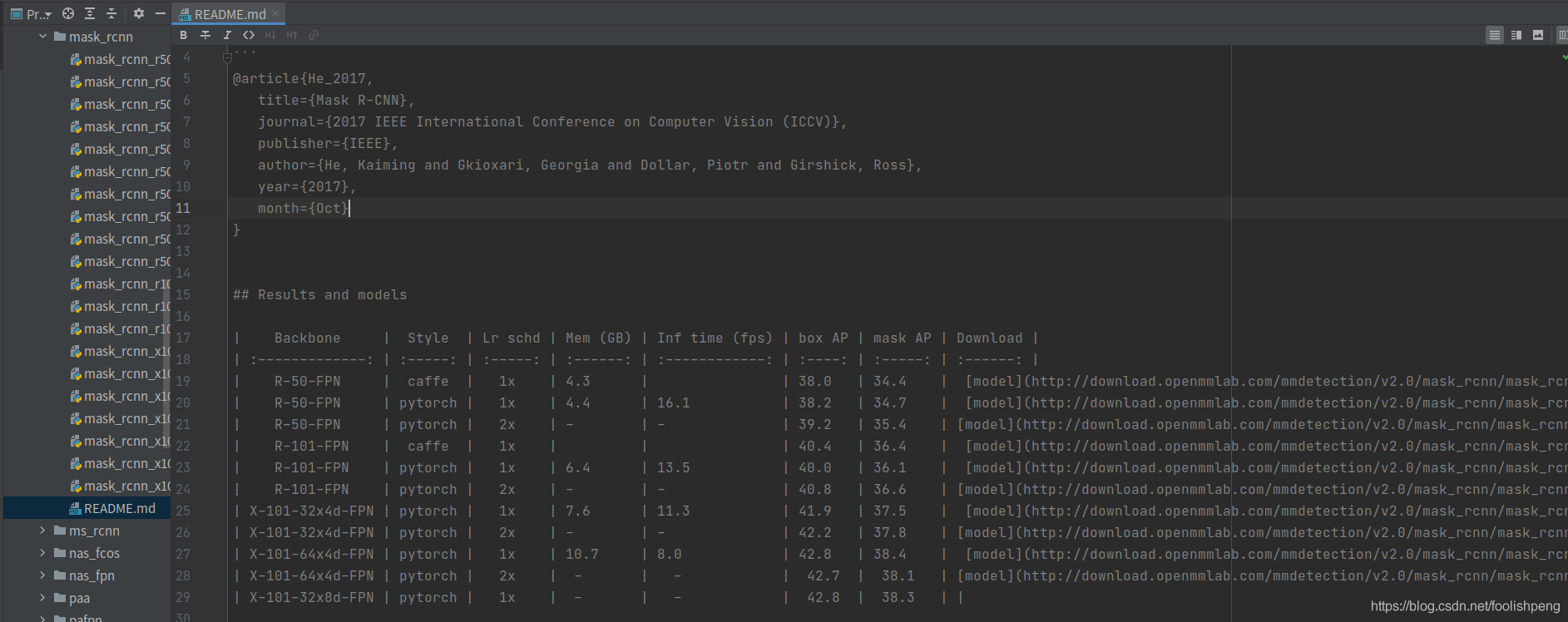
选择相应的预训练文件进行下载,下载完成后放到./checkpoints文件夹中就好了。
三、Train、test、inference模型
使用新的配置文件来训练模型,你只需要简单的按照下面的命令行来进行就好了:
# configs/ballon/ballon/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py是上面创建的配置文件路径,按照你自己项目实际的创建的配置文件路径来
# 如果你要用的GPU id是0,1,2的话就设置CUDA_VISIBLE_DEVICES=0,1,2 我这里只使用0号gpu
# 使用了几块gpu --gpus后面就写几
CUDA_VISIBLE_DEVICES=0 python tools/train.py configs/ballon/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py --gpus 1在训练过程当中生成的日志文件和checkpoints文件都会保存在./work_dirs//mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon(你之前命名的配置文件名)/
想要test已经训练好的模型,你可以按照下面简单的一行命令行来:
python tools/test.py
configs/ballon/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py #模型配置文件的路径
work_dirs/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon/latest.pth #之前自己训练好的checkpoint文件路径
#(官方文档写的是work_dirs/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_balloon.py/latest.pth 应该是写错了)
--eval bbox segm #进行test的评价指标四、总结
终于,终于,终于把这个训练自己的数据集的教程写(翻译)完了,ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ!!!
我自己按照这个流程训练了自己的数据集,主要是COCO数据集可能制作稍微麻烦些,因为我是用labelme标注的数据集,还需要自己转为对应的COCO格式(我自己转换的COCO数据集格式好像出了问题,后来用的项目组里面其他小伙伴转换好的数据集。下次写个博客记录一下怎么转COCO格式?),除此之外,暂时还没有遇到过什么大的问题,就是学习率对结果的影响会比较大,这个地方需要注意一下。
估计之后不会再更新这个MMDetection2博客了,因为我调了好多次参数,mask-rcnn的效果还是没有Detectron2框架跑的mask-rcnn效果好,我知道这肯定是我自己水平的原因,不可能是MMDetection2这个框架的实现没有Detectron2好这个原因。希望对想要使用MMDetection2的朋友有所帮助,同时欢迎再评论区拍砖!(好像变成了一个MMDetection2劝退贴(逃~)
码字不易,如果对你有所帮助,麻烦点个赞再走吧:)
未经许可,请勿随意转载!















 7658
7658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









