







 本文详细介绍了如何在Ubuntu 18.04环境中配置MMDetection,包括数据集划分、COCO格式转换、模型配置、训练与测试流程,以及如何生成结果指标如AP和Precision。同时分享了解决常见问题的方法,如编译错误和数据格式调整。
本文详细介绍了如何在Ubuntu 18.04环境中配置MMDetection,包括数据集划分、COCO格式转换、模型配置、训练与测试流程,以及如何生成结果指标如AP和Precision。同时分享了解决常见问题的方法,如编译错误和数据格式调整。
mmdetection训练自己的数据集
更新
2023/4/7更新 - 结果指标评估
0 环境配置
本篇文章在ubuntu18.04中配置。
主要版本如下:
Python 3.7
Cuda 10.1
Torch 1.7.0
参考mmdetection 环境配置(v2.14.0 (29/6/2021))
1 准备好数据集及标注文件
本篇使用COCO格式的数据集进行训练。
官方需求的格式如下,train2017和val2017放的是对应的照片。
mmdetection
├── mmdet
├── tools
├── configs
├── data
│ ├── coco
│ │ ├── annotations
│ │ │ ├── instances_train2017.json
│ │ │ ├── instances_val2017.json
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
我的data目录里格式如下,且标注文件为xml格式,需要做一些修改。
├── data
│ ├── images
│ │ ├── 1.jpg
│ │ ├── 2.jpg
......
│ │ ├── 10000.jpg
│ ├── annotations
│ │ ├── 1.xml
│ │ ├── 2.xml
......
│ │ ├── 10000.xml
1.1 首先把图片和标注文件划分为训练集和验证集。
划分后的目录如下所示
├── data
│ ├── images
│ ├── annotations
‘‘‘下面几个文件夹是划分后出现的’’’
│ ├── train_images
│ ├── train_annotations
│ ├── test_images
│ ├── test_annotations
使用的python脚本如下,split_images_and_XmlOrTxt.py,训练集比例默认0.9
可以直接将其放到和images同目录下
命令行运行python plit_images_and_XmlOrTxt.py --all_data_pat "自己存放图片的文件夹,默认images" --all_label_path "自己存放标签的文件夹,默认images"
例如我的存放图片的文件夹名字为my_images, 存放标签文件夹为 my_labels, 标签文件后缀为xml, 则需要执行以下命令python plit_images_and_XmlOrTxt.py --all_data_pat my_images --all_label_path my_labels
当标签后缀不为xml时候,如为txt,则在上述命令后加 --label_suffix txt即可。
#split_images_and_XmlOrTxt.py`
import os
import shutil
import random
from tqdm import tqdm
import numpy as np
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--label_suffix", default='xml' , help = "标签文件后缀 默认xml", type=str)
parser.add_argument("--all_data_path", default='images' , help="自己存放图片的文件夹,默认images", type=str)
parser.add_argument("--all_label_path", default='annotations' , help="自己存放标签的文件夹,默认images", type=str)
parser.add_argument("--train_percent", default=0.9 , help="训练集数据的比例,默认0.9", type=int)
args = parser.parse_args()
print('--------------')
print('开始处理')
'''
实现功能, 把images和对应的annotations里面的标签分割成训练集和测试集,
并把分割后的训练集图片放入train_images、标签放入train_annotations
测试集图片放入test_images、标签放入test_annotations
--mydata
----images
----annotations
'''
train_percent = args.train_percent #0-1
all_data_path = args.all_data_path
all_label_path = args.all_label_path
LabelSuffix = args.label_suffix #标签文件后缀 默认xml
train_images_path = 'train_images'
train_labels_path = 'train_annotations'
test_images_path = 'test_images'
test_labels_path = 'test_annotations'
#判断一下这几个目录是否存在,不存在则创建
if not os.path.exists(train_images_path):
os.mkdir(train_images_path)
if not os.path.exists(train_labels_path):
os.mkdir(train_labels_path)
if not os.path.exists(test_images_path):
os.mkdir(test_images_path)
if not os.path.exists(test_labels_path):
os.mkdir(test_labels_path)
data_file = os.listdir(all_data_path)
for i in tqdm(data_file):
shutil.copy(os.path.join(all_data_path, i), os.path.join(train_images_path, i))
shutil.copy(os.path.join(all_label_path, i[:-3] + LabelSuffix), os.path.join(train_labels_path, i[:-3] + LabelSuffix))
test_file = random.sample(data_file, int((1 - train_percent) * len(data_file)))
for j in tqdm(test_file):
shutil.move(os.path.join(train_images_path, j), os.path.join(test_images_path, j))
shutil.move(os.path.join(train_labels_path, j[:-3] + LabelSuffix), os.path.join(test_labels_path, j[:-3] + LabelSuffix))
print('处理完成')
print('--------------')
1.2 把训练集和验证集各自的标注文件转换为coco格式。这里提供一个xml转coco的脚本,命令行运行,输入两个参数,第一个参数是存放标注的文件夹,第二个参数是生成的json文件名。
在运行前记得把文件头部的类别改为自己需要的。
PRE_DEFINE_CATEGORIES = {'liner': 1, 'sailboat': 2, 'warship': 3, 'canoe': 4,
'bulk carrier': 5, 'container ship': 6, 'fishing boat': 7} #ToDo
xml2coco.py如下:
#xml2coco.py
# pip install lxml
import sys
import os
import json
import xml.etree.ElementTree as ET
from tqdm import tqdm
PRE_DEFINE_CATEGORIES = {'liner': 1, 'sailboat': 2, 'warship': 3, 'canoe': 4,
'bulk carrier': 5, 'container ship': 6, 'fishing boat': 7} #ToDo
# If necessary, pre-define category and its id
# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,
# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,
# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,
# "motorbike": 14, "person": 15, "pottedplant": 16,
# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}
START_BOUNDING_BOX_ID = 0
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.'%(name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.'%(name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = os.path.splitext(filename)[0]
return int(filename)
except:
raise NotImplementedError('Filename %s is supposed to be an integer.'%(filename))
def convert(xml_list, xml_dir, json_file):
list_fp = open(xml_list, 'r')
json_dict = {"images":[], "type": "instances", "annotations": [],
"categories": []}
categories = PRE_DEFINE_CATEGORIES
bnd_id = START_BOUNDING_BOX_ID #每个标注框id唯一
image_id = 0 #每个图片id唯一
list_fp = tqdm(list_fp) #tqdm使用
for line in list_fp:
line = line.strip()
list_fp.set_description("Processing %s" % line)
xml_f = os.path.join(xml_dir, line)
tree = ET.parse(xml_f)
root = tree.getroot()
path = get(root, 'path')
if len(path) == 1:
filename = os.path.basename(path[0].text) #xml中path的文件名
elif len(path) == 0:
filename = get_and_check(root, 'filename', 1).text
else:
raise NotImplementedError('%d paths found in %s'%(len(path), line))
filename = line[:-3] + 'jpg'
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width,
'id':image_id}
json_dict['images'].append(image)
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(get_and_check(bndbox, 'xmin', 1).text)
ymin = int(get_and_check(bndbox, 'ymin', 1).text)
xmax = int(get_and_check(bndbox, 'xmax', 1).text)
ymax = int(get_and_check(bndbox, 'ymax', 1).text)
assert(xmax > xmin)
assert(ymax > ymin)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
segment = [xmin, ymin, xmin, ymin + o_height, xmin + o_width, ymin + o_height,
xmin + o_width, ymin]
ann = {'area': o_width*o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox':[xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': [segment]}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
image_id = image_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
list_fp.close()
os.remove(sys.argv[1] + '/../xml_list.txt')
if __name__ == '__main__':
if len(sys.argv) <= 1:
print('2 auguments are need.')
print('Usage: %s XML_DIR OUTPU_JSON.json'%(sys.argv[0]))
exit(1)
res = os.listdir(sys.argv[1])
res.sort()
with open(sys.argv[1] + '/../xml_list.txt','a') as f:
for i in range(len(res)):
f.write(res[i])
f.write('\n')
convert(sys.argv[1] + '/../xml_list.txt', sys.argv[1], sys.argv[2])
1.3 然后修改文件名,按照如下所示放置数据文件。
mmdetection
├── mmdet
├── tools
├── configs
├── data
│ ├── coco
│ │ ├── annotations
│ │ │ ├── instances_train2017.json
│ │ │ ├── instances_val2017.json
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
至此,数据集的准备工作完成。
2 修改相关配置文件
这里以faster_rcnn_r101_fpn_1x_coco_20200130-f513f705.pth模型为例,配置文件为mmdetection/configs/faster_rcnn/faster_rcnn_r101_fpn_1x_coco.py。
上面的步骤已经准备好了coco数据集,但是官方提供的代码中,class_name和class_num是需要修改的。
2.1 定义数据种类
2.1.1 需要修改的地方在mmdetection/mmdet/datasets/coco.py。把CLASSES的那个tuple改为自己数据集对应的种类tuple即可。
class CocoDataset(CustomDataset):
CLASSES = ('liner', 'sailboat', 'warship', 'canoe', 'bulk carrier', 'container ship', 'fishing boat')
注意:如果只有一个类,要加上一个逗号,否则将会报错。
2.1.2在mmdetection/mmdet/core/evaluation/class_names.py修改coco_classes数据集类别,这个关系到后面test的时候结果图中显示的类别名称。例如:
去对应目录寻找
def coco_classes():
return [
'liner', 'sailboat', 'warship', 'canoe', 'bulk carrier', 'container ship', 'fishing boat'
]
2.2 修改模型文件
(因为模型为faster_rcnn_r101_fpn_1x,所以配置对应的config文件)
找到mmdetection/configs/faster_rcnn/faster_rcnn_r101_fpn_1x_coco.py文件,打开后发现
_base_ = './faster_rcnn_r50_fpn_1x_coco.py'
继续沿着这个路径去找文件,发现指向的以下文件
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
#指向的是model dict,修改其中的num_classes类别为自己的类别。
'../_base_/datasets/coco_detection.py',
#data dict中的workers_per_gpu=2设置为0,train_pipeline和test_pipeline中的img_scale根据自己的图片尺寸修改。
'../_base_/schedules/schedule_1x.py',
#optimizer dict中修改学习率lr。当gpu数量为8时,lr=0.02;当gpu数量为4时,lr=0.01;我只有一个gpu,所以设置lr=0.0025
'../_base_/default_runtime.py'
]
(如果是尝试训练,以上修改就可以,如果想要优化自己的模型等等,可以参考这个博客的代码详解这里)
3 开始训练
训练前在mmdetection的目录下新建work_dirs文件夹。
重要:若改动框架源代码后,一定要注意重新编译后再使用。类似这里修改了几个源代码文件后再使用train命令之前,先要编译,执行下面命令。
pip install -v -e . # or "python setup.py develop"
最后,执行训练指令。
python tools/train.py configs/faster_rcnn/faster_rcnn_r101_fpn_1x_coco.py --work-dir work_dirs
注:以上训练是没有使用预训练模型的。如需使用,在
configs/faster_rcnn/下有个README.md,里面有模型的下载链接,下载完后自己选择放一个目录,我一般是习惯在mmdetection根目录下新建一个checkpoints文件夹,模型都放在这里面,然后在configs/_base_/default_runtime.py文件中修改load_from = None,把None改成你的模型所在,比如load_from = 'checkpoints/xxx.pth',然后训练就可以使用预训练模型了。
4 使用训练好的模型进行测试
1、以下方式默认是对验证集进行测试的,如果需要对自己无标签的测试集进行测试,需要在1.3中把测试集图片放去test2017,然后生成对应的伪标签 instances_val2017.json 放入annotations文件夹。伪标签生成代码因为篇幅原因放在另一篇博客了,点这里
2、在'.configs//_base_/datasets/coco_detection.py'中,修改data dcit中的test dict
#修改前
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
#修改后
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_test2017.json',
img_prefix=data_root + 'test2017/',
3、开始测试
#测试训练集,并展示结果
python tools/test.py configsxxx.py checkpoints/xxx.pth --show
#如果多个图片时候,按键盘 q 切换下一张
#测试训练集,并生成对应json格式标注文件
python tools/test.py configsxxx.py checkpoints/xxx.pth --eval-options "jsonfile_prefix=result" --format-only
#会在执行目录下生成results.bbox.json的文件
注:第二条命令行执行时候后面那里一定要用双引号,要不然json文件不会生成
此外,如果仅仅是想对于任意单张图片进行测试,可以使用demo/image_demo.py
#
python demo/image_demo.py xxximg.jpg xxconfig.py xxxcheckpoint.pth
#在这个demo里面,如果想获取每张图片的检测结果具体数值(bbox),
在 model = init_detector(args.config, args.checkpoint, device=args.device)
# test a single image
result = inference_detector(model, args.img)
这几行代码下面(大概在29行的位置)加入,下面那段程序。
if isinstance(result, tuple):
bbox_result, segm_result = result
else:
bbox_result, segm_result = result, None
labels = [
np.full(bbox.shape[0], i, dtype=np.int32)
for i, bbox in enumerate(bbox_result)
]
labels = np.concatenate(labels)
labels = labels[:, np.newaxis] # 拼接数组之前把一维数组 (1,) 变成 (1,1) 才可以拼接
bboxes = np.vstack(bbox_result)
my_results = np.hstack((bboxes, labels))
np.set_printoptions(suppress=True) # numpy 输出的时候不使用科学计数法
# np.set_printoptions(precision=4) # 设精度为3
# bboxes是没有经过筛选框的, TODO 可以通过score-thr>0.3筛选
my_results = my_results[my_results[:, 4] > args.score_thr]
'''
my_results: 行数为目标的个数,
0-5列 xmin, ymin, xmax, ymax , 置信度 , label
[[396.008 246.362 472.983 282.095 0.997 6. ]
[421.504 153.122 482.345 193.91 0.839 6. ]
[407.489 156.391 461.481 191.087 0.582 6. ]
[411.581 170.763 475.659 191.881 0.542 6. ]
[499.179 166.213 575.396 191.727 0.372 6. ]]
'''
my_results = np.around(my_results, 4)
5 可视化训练过程日志
#可视化log
python tools/analysis_tools/analyze_logs.py plot_curve xxxx.log.json --keys loss_cls loss_bbox
#xxxx.log.json为你训练过程中给产生的日志文件,一般在work_dirs目录下,
#--key 后面可以跟参数 loss_cls 、loss_bbox等等,或者也可以跟bbox_mAP等等
#loss_cls 、loss_bbox这些由于模型的不同,可能名字会有些不同,具体以你json文件里面的为准
注:最好不要loss_cls这一类 和bbox_mAP这一类同时使用,因为loss_cls 是每个iter都有,一个epoch会有很多个iter,但是bbox_mAP是每个epoch结束有,一般出现的次数等于epoch数量。如果两者同时出现会导致图像非常扭曲!!!
6 结果指标评估
由于默认的指标评估看起来不直观,且没有每个类别的具体指标。本文使用的是COCO格式数据集,需要进行转换。
6.1 先使用 test.py生成 results.pkl 文件
python tools/test.py work_dir/faster_rcnn_r50_fpn_1x_coco.py work_dir/latest.pth --out results.pkl
- work_dir/faster_rcnn_r50_fpn_1x_coco.py: 模型配置文件
- work_dir/latest.pth: 训练好的模型
- --out results.pkl: 代表输出到根目录的results.pkl文件中, 也可以输出到指定目录
6.2 使用VOC标准计算各个类别 map
这里要用到旧版本 1.0.0 下的 tools/voc_eval.py 文件, 由于该文件已经在2.11.0版本中移除, 所以需要去官网下载, 链接: voc.eval.py文件 , 后文也会复制一份放在本文中
下载后将 voc_eval.py 放到 tools 目录下, 然后执行如下命令,采用voc标准计算mAP:
python tools/voc_eval.py results.pkl work_dirs/faster_rcnn_r50_fpn_1x_coco.py
便可以得到如下结果:
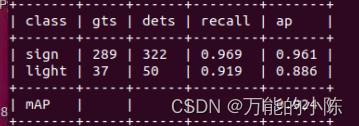
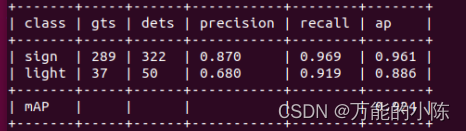
6.3 增加评估指标precision
但是发现里面并没有precision这项指标,因为需要对原代码修改。
修改后的检测结果
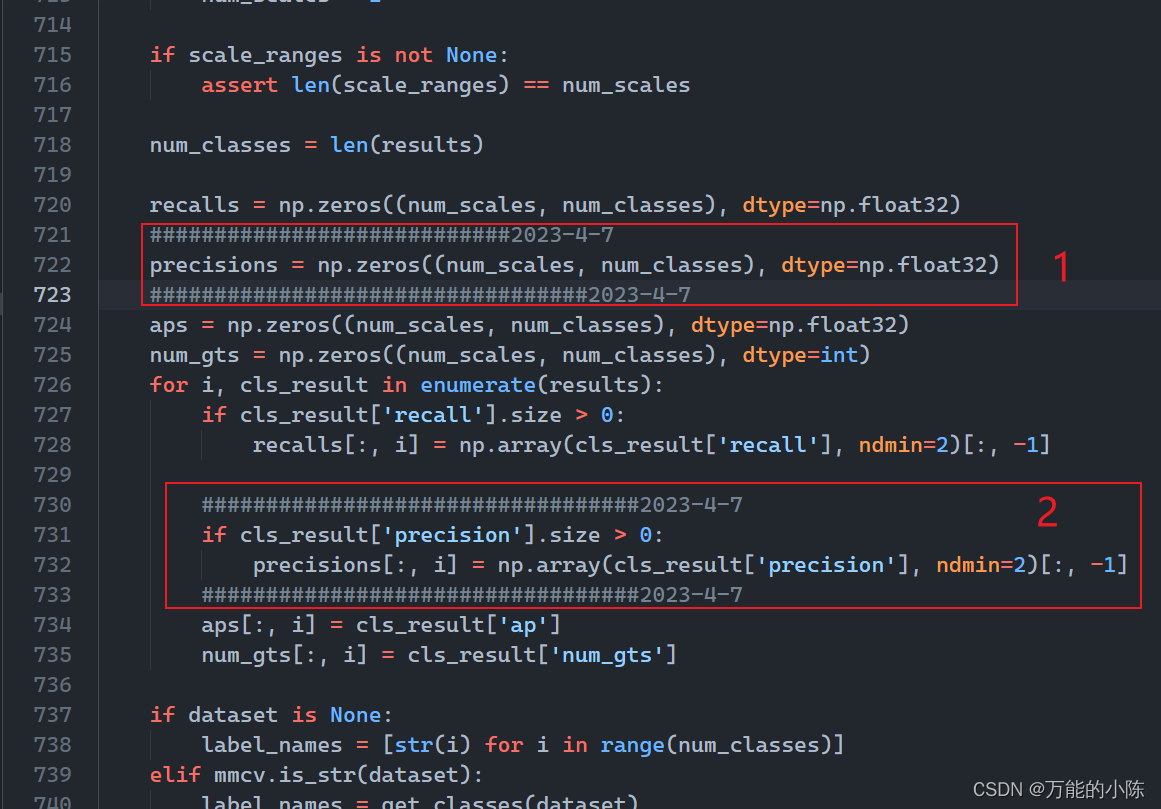
6.3.1 具体步骤
1.mmdet/core/evaluation/mean_ap.py文件中,找到print_map_summary函数。
修改下面5个地方
红色框框内为新加的内容
precisions = np.zeros((num_scales, num_classes), dtype=np.float32)
if cls_result['precision'].size > 0:
precisions[:,i] = np.array(cls_result['precision'], ndmin=2)[:,-1]
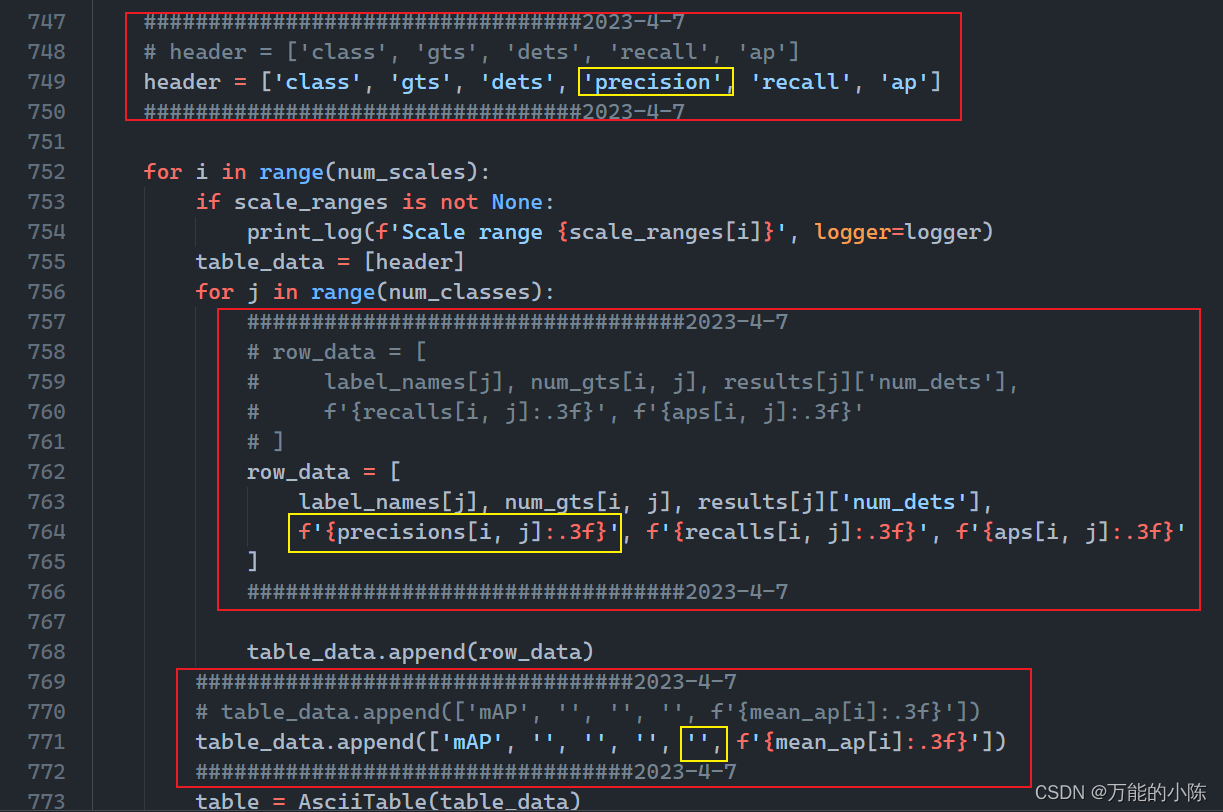
黄色框内为具体更改的地方
f'{precisions[i,j]:.3f}'
最后:遇到的一些问题以及解决方法。
1、如果出现model num_class == 80 , num_class == 15的一个错误,很可能是你修改完类别后没有重新编译,此时重新执行一下pip install -v -e . # or "python setup.py develop" 应该就可以解决问题。
2、 问题:
class_name
rles = maskUtils.frPyObjects(mask_ann, img_h, img_w) File
"pycocotools/_mask.pyx", line 292, in pycocotools._mask.frPyObjects
IndexError: list index out of range
解决方法:(我在使用mask_rcnn模型训练时候碰到,因为coco数据集中的segmentation代表边界点,一般是分割时候使用,所以在转格式时候就把segmentation置空了,结果就出现这个错误。后来在矩形框中取了四个定点,四条边的中点共8个点,然后就不报错了)。即instances_train2017.json文件中segmentation不能为空。
3、 问题:
File "/home/chen/anaconda3/envs/mmdet/lib/python3.7/site-packages/mmcv/image/geometric.py", line 517, in impad
value=pad_val)
cv2.error: OpenCV(4.5.2) /tmp/pip-req-build-947ayiyu/opencv/modules/core/src/copy.cpp:1026: error: (-215:Assertion failed) top >= 0 && bottom >= 0 && left >= 0 && right >= 0 && _src.dims() <= 2 in function 'copyMakeBorder'
解决方法:因为有些数据集图像是手机拍摄的,然后位置角度信息可能就会跟正常不太一样,读取时候就会造成超出边界。造成这个问题的原因可能不仅仅一种,所以可以先试试以下代码,检查一下图片是否有问题
import glob
import mmcv
from PIL import Image
import json
import numpy as np
img_path = "/path/to/your/images/"
print("parsing images...")
images = glob.glob(img_path+"*.jpg")
print("checking images...")
inverted = []
for f in images:
if str(mmcv.imread(f).shape) != str(np.array(Image.open(f)).shape):
inverted.append(f)
print(len(inverted),"bad images :",inverted)
如果存在有问题的图片,把这些图片去除就可以。如果有问题图片过多,可以尝试旋转图片90度,然后删除EXIF信息。以上方法参考这里https://github.com/open-mmlab/mmdetection/issues/3482
参考博客


















 696
696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











