







在上一篇文章添加链接描述中我们介绍了寒武纪显卡实现基本的softmax代码,这里我们借助于寒武纪的流水并行来编写进一步的策略。
pingpongGDRAM2NRAM流水
仅仅计算max和sum使用流水
我们先考虑不使用SRAM的流水,我们设置两个NRAM上的长度为maxNum上的数组src0和src1以及两个NRAM上的指针read和write,一开始设置write=src0,并且使用memcpy把sourc1的开头maxNum数据加载到write上,然后开始进入循环,其中循环次数为repeat-1。在循环内部不断交换read和write指针指向的数组,内部使用memcpy_async把后面的数据加载到write里面,发起这段命令以后马上针对read的数据进行计算,参考表格如下:

循环结束以后,发现最后还有maxNum的元素存储在write里面没有计算,为此需要针对这部分数据特殊处理,最后针对remain这部分不能整除的数据继续特殊处理即可。这里一定要注意的就是在循环内部一定要在计算结束以后加入同步机制__sync_all_ipu();
但是在计算出全局最大值和数值和以后,我们还要重新从GDRAM中读取数据到NRAM实现指数变换,在这个过程我们可以类似的使用这种方法来做流水,此时如果仅仅针对数据从GDRAM到NRAM和计算这两部分做流水,那么这个循环就没必要做__sync_all_ipu(),因为计算结束以后把数据写回GDRAM的这个过程可以保证数据结束,参考下面这个代码。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float src0[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
__mlu_entry__ void softmaxKernel(float* dst, float* source1, float* globalMax, float* globalSum, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分taskId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source1 = source1 + indStart;//设定起始偏移量
//------------------------------------下面开始计算max
__nram__ float destOldMax;
__nram__ float destNewMax;
__bang_write_zero(destSum, maxNum);
destNewMax = -INFINITY;//初始化为负无穷
__nram__ float *read;
__nram__ float *write;
write = src0;
__memcpy(write, source1, NRAM_MAX_SIZE, GDRAM2NRAM);
for(int i = 0; i < repeat - 1; i++){
if(i%2 == 0){
read = src0;
write = src1;
}
else{
read = src1;
write = src0;
}
__memcpy_async(write, source1 + (i + 1) * maxNum, NRAM_MAX_SIZE, GDRAM2NRAM);
__bang_argmax(srcMax, read, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(read, read, destNewMax, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(read, read, maxNum);//src1 = exp(src1 - 最大值)
if(i > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);//destSum = destSum * exp(destOldMax - destNewMax)
}
__bang_add(destSum, destSum, read, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
__sync_all_ipu();//必须同步
}
//------------特殊处理最后一部分
__bang_argmax(srcMax, write, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(write, write, destNewMax, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(write, write, maxNum);//src1 = exp(src1 - 最大值)
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
__bang_add(destSum, destSum, write, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
//-------------特殊处理结束
if(remainNram){
__bang_write_value(src1, maxNum, -INFINITY);//必须要初始化src1全部元素为负无穷
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src1中
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src1, maxNum, destNewMax);//必须重新初始化为destNewMax
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);//必须再次读取
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//后面maxNum-remainNram部分为0
__bang_active_exp_less_0(src1, src1, maxNum);//相当于多加了maxNum-remainNram
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
__bang_add(destSum, destSum, src1, maxNum);
destOldMax = destNewMax;
}//结束以后向量destNewMax保存了source1[indSart:indStart+step]这部分数据的全局最大值,destSum保存数值和
//----------
__bang_write_zero(destSumFinal, warpSize);//初始化destSumFinal全部元素为0
int segNum = maxNum / warpSize;//将destSum分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - remainNram);//把上面多加的(maxNum - remainNram)减掉
//----------
globalMax[0] = -INFINITY;
globalSum[0] = 0.0;
__sync_all();
__bang_atomic_max(&destNewMax, globalMax, &destNewMax, 1);//globalMax[0]必须初始化为负无穷
destSumFinal[0] = destSumFinal[0] * exp(destOldMax - globalMax[0]);
//__bang_printf("taskId:%d, step:%d, sum:%.6f\n", taskId, step, destSumFinal[0]);
__sync_all();
__bang_atomic_add(destSumFinal, globalSum, destSumFinal, 1);//globalSum[0]必须初始化为0
dst = dst + indStart;//设定起始偏移量
float globalSumInv = 1.0/globalSum[0];
write = src0;
__memcpy(write, source1, NRAM_MAX_SIZE, GDRAM2NRAM);
for(int i = 0; i < repeat - 1; i++){
if(i%2 == 0){
read = src0;
write = src1;
}
else{
read = src1;
write = src0;
}
__memcpy_async(write, source1 + (i + 1) * maxNum, NRAM_MAX_SIZE, GDRAM2NRAM);
__bang_sub_scalar(read, read, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(read, read, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(read, read, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + i * maxNum, read, NRAM_MAX_SIZE, NRAM2GDRAM);
}
//-----------特殊处理最后一部分
__bang_sub_scalar(write, write, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(write, write, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(write, write, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + (repeat - 1) * maxNum, write, NRAM_MAX_SIZE, NRAM2GDRAM);
if(remainNram){
__bang_write_value(src1, maxNum, globalMax[0]);
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src1, src1, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + repeat * maxNum, src1, remainNram * sizeof(float), NRAM2GDRAM);
}
__bang_printf("taskId:%d,repeat:%d,max:%.6f, sum:%.6f\n",taskId, repeat, globalMax[0], globalSum[0]);
}
int main(void)
{
int num = 1024 * 1024 * 1024;
//int num = 11;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
}
float* mlu_dst;
float* mlu_src1;
float* globalMax;
float* globalSum;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalMax, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalSum, sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, globalMax, globalSum, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 10; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(globalMax);
cnrtFree(globalSum);
free(host_dst);
free(host_src1);
return 0;
}
指数变换也使用流水
但是如果我们把数据从NRAM写回GDRAM也加入流水,那么就需要同步,我们以两个表格来展示流水模型
计算全局最大值和数值和,对于一个长度为4maxNum的向量来说,循环总数是4+1,其中数据拷贝只存在于i<4的循环,数据计算只存在于i>0的循环,我们以i=1为例,当i=1时,此时数据拷贝的是[maxNum:2maxNum]这部分数据,但是计算的却是[0:maxNum]这部分数据,因此这两个完美避开。
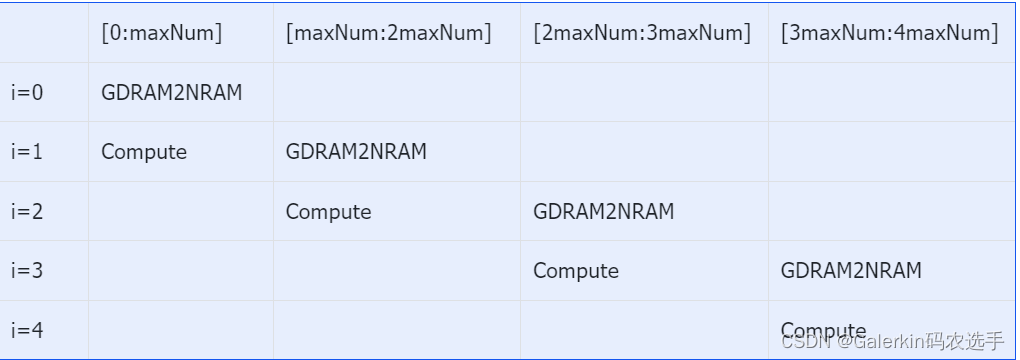
指数变换,这个过程和上面类似,不过循环总数变成了4+2,GDRAM2NRAM这个过程只存在于i<4,Compute这个过程只存在于0<i<5,NRAM2GDRAM这个过程只存在于i>1.
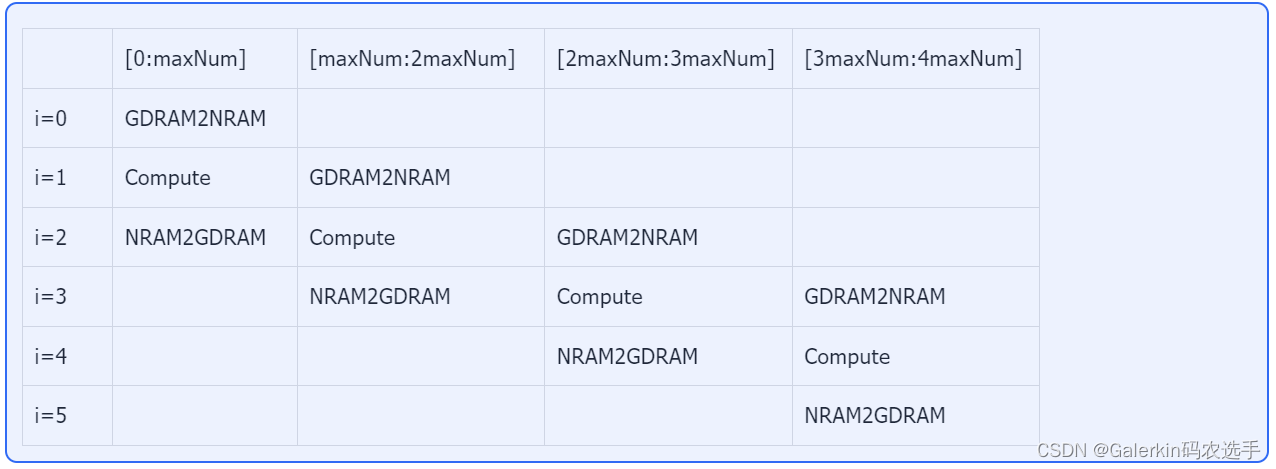
因此,我们定义一个长度为3maxNum的NRAM向量src,一开始的计算全局最大值和数值和过程只使用前面2maxNum的空间,后面指数变换的时候才使用全部空间。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src[3 * maxNum];//后面GDRAM2NRAM,计算,NRAM2GDRAM三份数据
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
__mlu_entry__ void softmaxKernel(float* dst, float* source, float* globalMax, float* globalSum, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分taskId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source = source + indStart;//设定起始偏移量
//------------------------------------下面开始计算max
__nram__ float destOldMax;
__nram__ float destNewMax;
__bang_write_zero(destSum, maxNum);
destNewMax = -INFINITY;//初始化为负无穷
for(int i = 0; i < repeat + 1; i++){
if(i < repeat){
__memcpy_async(src + i%2 * maxNum, source + i * maxNum, NRAM_MAX_SIZE, GDRAM2NRAM);
}
if(i > 0){
__bang_argmax(srcMax, src + (i - 1)%2 * maxNum, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(src + (i - 1)%2 * maxNum, src + (i - 1)%2 * maxNum, destNewMax, maxNum);//src = src - 最大值
__bang_active_exp_less_0(src + (i - 1)%2 * maxNum, src + (i - 1)%2 * maxNum, maxNum);//src = exp(src - 最大值)
if(i > 1){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src + (i - 1)%2 * maxNum, maxNum);//destSum = destSum + exp(src - destNewMax)
destOldMax = destNewMax;
}
__sync_all_ipu();
}
if(remainNram){
__bang_write_value(src, 3 * maxNum, -INFINITY);//必须要初始化src全部元素为负无穷
__memcpy(src, source + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, src, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量src中
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src, 3 * maxNum, destNewMax);//必须重新初始化为destNewMax
__memcpy(src, source + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);//必须再次读取
__bang_sub_scalar(src, src, destNewMax, maxNum);//后面maxNum-remainNram部分为0
__bang_active_exp_less_0(src, src, maxNum);//相当于多加了maxNum-remainNram
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src, maxNum);
destOldMax = destNewMax;
}//结束以后向量destNewMax保存了source[indSart:indStart+step]这部分数据的全局最大值,destSum保存数值和
//----------
__bang_write_zero(destSumFinal, warpSize);//初始化destSumFinal全部元素为0
int segNum = maxNum / warpSize;//将destSum分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - remainNram);//把上面多加的(maxNum - remainNram)减掉
//----------
globalMax[0] = -INFINITY;
globalSum[0] = 0.0;
__sync_all();
__bang_atomic_max(&destNewMax, globalMax, &destNewMax, 1);//globalMax[0]必须初始化为负无穷
destSumFinal[0] = destSumFinal[0] * exp(destOldMax - globalMax[0]);
//__bang_printf("taskId:%d, step:%d, sum:%.6f\n", taskId, step, destSumFinal[0]);
__sync_all();
__bang_atomic_add(destSumFinal, globalSum, destSumFinal, 1);//globalSum[0]必须初始化为0
dst = dst + indStart;//设定起始偏移量
float globalSumInv = 1.0/globalSum[0];
for(int i = 0; i < repeat + 2; i++){
if(i < repeat){
__memcpy_async(src + i%3 * maxNum, source + i * maxNum, NRAM_MAX_SIZE, GDRAM2NRAM);
}
if(i > 0 && i < repeat + 1){
__bang_sub_scalar(src + (i - 1)%3 * maxNum, src + (i - 1)%3 * maxNum, globalMax[0], maxNum);//src = src - globalMax[0]
__bang_active_exp_less_0(src + (i - 1)%3 * maxNum, src + (i - 1)%3 * maxNum, maxNum);//src = exp(src - globalMax[0])
__bang_mul_scalar(src + (i - 1)%3 * maxNum, src + (i - 1)%3 * maxNum, globalSumInv, maxNum);
}
if(i > 1){
__memcpy_async(dst + (i - 2) * maxNum, src + (i - 2)%3 * maxNum, NRAM_MAX_SIZE, NRAM2GDRAM);
}
__sync_all_ipu();
}
if(remainNram){
__bang_write_value(src, 3 * maxNum, globalMax[0]);
__memcpy(src, source + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src, src, globalMax[0], maxNum);//src = src - globalMax[0]
__bang_active_exp_less_0(src, src, maxNum);//src = exp(src - globalMax[0])
__bang_mul_scalar(src, src, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + repeat * maxNum, src, remainNram * sizeof(float), NRAM2GDRAM);
}
__bang_printf("taskId:%d,repeat:%d,max:%.6f, sum:%.6f\n",taskId, repeat, globalMax[0], globalSum[0]);
}
int main(void)
{
int num = 1024 * 1024 * 1024;
//int num = 11;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src[i] = i%4;
}
float* mlu_dst;
float* mlu_src;
float* globalMax;
float* globalSum;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalMax, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalSum, sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src, host_src, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src, globalMax, globalSum, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 10; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src);
cnrtFree(globalMax);
cnrtFree(globalSum);
free(host_dst);
free(host_src);
return 0;
}
NRAM合并访存+三级流水
这个代码的流水性能最好,并且这里专门针对不能整除的部分做了处理,在计算全局最大值和数值和的过程中,src已经保存这部分的数据信息,因此指数变换的时候,完全可以先针对这部分数据做指数变换,这样就可以直接利用上一步的数据信息。
这个代码如果使用UNION4,16个任务,那么计算时间只需要73ms左右,从理论上来看,计算这个softmax需要两次读取数据(计算max,sum有一次读取,计算结束以后指数变换还需要一次读取)和一次写回,一共需要3×4=12GB数据移动,205机器的理论带宽是307GB/s,理论上需要39ms,实际计算时间为73ms,IO效率大于50%
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[3 * maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
__mlu_entry__ void softmaxKernel(float* dst, float* source1, float* globalMax, float* globalSum, int num) {
int size = taskDim * maxNum;
int remain = num%size;//如果不能整除,则让前部分taskId多处理一个元素
int repeat = (num - remain)/size;
int remainTask = remain%taskDim;
int stepEasy = (remain - remainTask)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remainTask ? stepHard : stepEasy);//前部分taskId多处理一个元素
int indStart = (taskId < remainTask ? taskId * stepHard : remainTask * stepHard + (taskId - remainTask) * stepEasy);
__nram__ float destOldMax;
__nram__ float destNewMax;
__bang_write_zero(destSum, maxNum);
destNewMax = -INFINITY;//初始化为负无穷
for(int i = 0; i < repeat + 1; i++){
if(i < repeat){
__memcpy_async(src1 + i%2 * maxNum, source1 + i * size + taskId * maxNum, NRAM_MAX_SIZE, GDRAM2NRAM);
}
if(i > 0){
__bang_argmax(srcMax, src1 + (i - 1)%2 * maxNum, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(src1 + (i - 1)%2 * maxNum, src1 + (i - 1)%2 * maxNum, destNewMax, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(src1 + (i - 1)%2 * maxNum, src1 + (i - 1)%2 * maxNum, maxNum);//src1 = exp(src1 - 最大值)
if(i > 1){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1 + (i - 1)%2 * maxNum, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
}
__sync_all_ipu();
}
if(remain){
__bang_write_value(src1, maxNum, -INFINITY);//必须要初始化src1全部元素为负无穷
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, src1, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src1, maxNum, destNewMax);//必须重新初始化为destNewMax
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);//必须再次读取
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//后面maxNum-step部分为0
__bang_active_exp_less_0(src1, src1, maxNum);//相当于多加了maxNum-step
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);
destOldMax = destNewMax;
}
//----------
__bang_write_zero(destSumFinal, warpSize);//初始化destSumFinal全部元素为0
int segNum = maxNum / warpSize;//将destSum分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
if(remain){
destSumFinal[0] = destSumFinal[0] - (maxNum - step);//把上面多加的(maxNum - step)减掉
}
//----------
globalMax[0] = -INFINITY;
globalSum[0] = 0.0;
__sync_all();
__bang_atomic_max(&destNewMax, globalMax, &destNewMax, 1);//globalMax[0]必须初始化为负无穷
destSumFinal[0] = destSumFinal[0] * exp(destOldMax - globalMax[0]);
//__bang_printf("taskId:%d, step:%d, sum:%.6f\n", taskId, step, destSumFinal[0]);
__sync_all();
__bang_atomic_add(destSumFinal, globalSum, destSumFinal, 1);//globalSum[0]必须初始化为0
float globalSumInv = 1.0/globalSum[0];
if(remain){
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + repeat * size + indStart, src1, step * sizeof(float), NRAM2GDRAM);
}
for(int i = 0; i < repeat + 2; i++){
if(i < repeat){
__memcpy_async(src1 + i%3 * maxNum, source1 + i * size + taskId * maxNum, NRAM_MAX_SIZE, GDRAM2NRAM);
}
if(i > 0 && i < repeat + 1){
__bang_sub_scalar(src1 + (i - 1)%3 * maxNum, src1 + (i - 1)%3 * maxNum, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1 + (i - 1)%3 * maxNum, src1 + (i - 1)%3 * maxNum, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(src1 + (i - 1)%3 * maxNum, src1 + (i - 1)%3 * maxNum, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
}
if(i > 1){
__memcpy_async(dst + (i - 2) * size + taskId * maxNum, src1 + (i - 2)%3 * maxNum, NRAM_MAX_SIZE, NRAM2GDRAM);
}
__sync_all_ipu();
}
//__bang_printf("taskId:%d,repeat:%d,max:%.6f, sum:%.6f\n",taskId, repeat, globalMax[0], globalSum[0]);
}
int main(void)
{
int num = 1024 * 1024 * 1024;
//int num = 11;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
}
float* mlu_dst;
float* mlu_src1;
float* globalMax;
float* globalSum;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalMax, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalSum, sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, globalMax, globalSum, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = num - 10; i < num; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(globalMax);
cnrtFree(globalSum);
free(host_dst);
free(host_src1);
return 0;
}
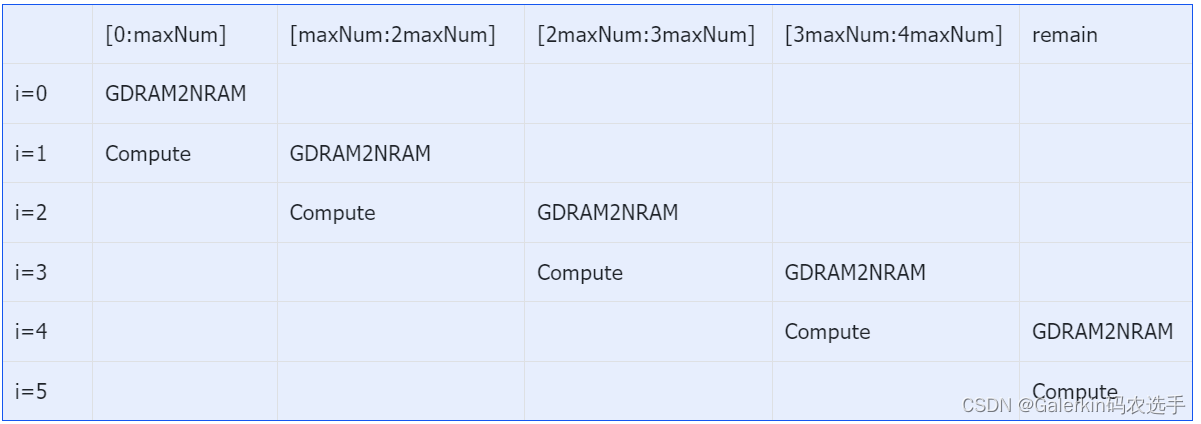
不能整除部分加入流水
我们在上面的基础上继续针对计算全局最大值,数值和以及指数变换建模,此时我们需要判断一下数组的长度是否整除,如果remain不等于0,那么计算模型的循环总数就设置为repeat+2
下面是指数变换的表格模型,如果remain不等于0,那么计算模型的循环总数就设置为repeat+3
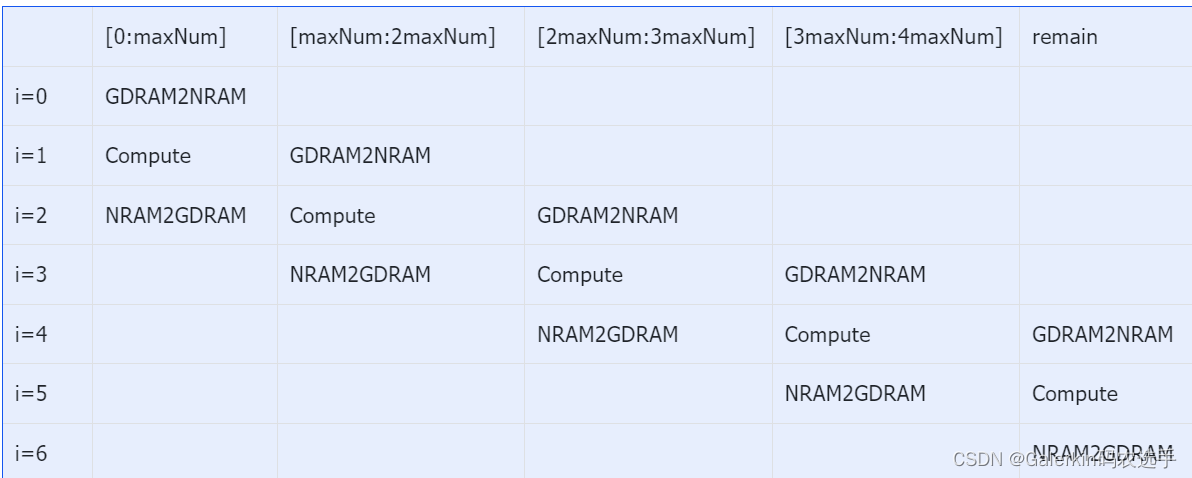
这种做法代码实现相对复杂,这里就不提供代码了。
SRAM应用
上面这几个版本的softmax都有一个共同点,即不同taskId处理的那step数据是相互隔离的,类似于taskId=0的时候处理[0:step],taskId = j的时候处理[j×step:(j + 1)×step]这部分数据,对于taskId来说再对这部分数据不断分成maxNum段来处理。这里我们换一种思路,我们把数据分成以长度为taskDim×maxNum的多个小单元,然后针对小单元让不同taskId来处理对应的这部分数据,比如说对于第一个小单元,taskId=j的时候就处理[j×maxNum:(j + 1)×maxNum]这部分数据,对于第N个小单元,taskId=j的时候就处理[(N - 1)×taskDim×maxNum + j×maxNum: N×taskDim×maxNum + (j + 1)×maxNum]这部分数据,在一定程度上可以起到合并访存的效果,最重要的是,此时不同taskId处理的数据是连续的,我们可以使用共享内存SRAM来加速,参考链接添加链接描述
我们开辟一个长度为taskDim×maxNum的共享内存src2SRAM,每次先从source1当中读取一个小单元,把数据先存储到共享内存中,然后做一个cluster上的同步,之后再将这部分数据从共享内存中读取到NRAM上,经过代码测试,这样做可以有效提高速度,完整代码如下所示:
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 256;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
template<int taskNum>
__mlu_entry__ void softmaxKernel(float* dst, float* source1, float* globalMax, float* globalSum, int num) {
__mlu_shared__ float src2SRAM[taskNum * maxNum];
int size = taskDim * maxNum;
int remain = num%size;//如果不能整除,则让前部分taskId多处理一个元素
int repeat = (num - remain)/size;
int remainTask = remain%taskDim;
int stepEasy = (remain - remainTask)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remainTask ? stepHard : stepEasy);//前部分taskId多处理一个元素
int indStart = (taskId < remainTask ? taskId * stepHard : remainTask * stepHard + (taskId - remainTask) * stepEasy);
__nram__ float destOldMax;
__nram__ float destNewMax;
__bang_write_zero(destSum, maxNum);
destNewMax = -INFINITY;//初始化为负无穷
for(int i = 0; i < repeat; i++){
__memcpy(src2SRAM, source1 + i * size, taskDim * NRAM_MAX_SIZE, GDRAM2SRAM);
__sync_cluster(); //设置sync barrier
__memcpy(src1, src2SRAM + taskId * maxNum, NRAM_MAX_SIZE, SRAM2NRAM);
__bang_argmax(srcMax, src1, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - 最大值)
if(i > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
}
if(remain){
__bang_write_value(src1, maxNum, -INFINITY);//必须要初始化src1全部元素为负无穷
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, src1, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src1, maxNum, destNewMax);//必须重新初始化为destNewMax
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);//必须再次读取
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//后面maxNum-step部分为0
__bang_active_exp_less_0(src1, src1, maxNum);//相当于多加了maxNum-step
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);
destOldMax = destNewMax;
}
//----------
__bang_write_zero(destSumFinal, warpSize);//初始化destSumFinal全部元素为0
int segNum = maxNum / warpSize;//将destSum分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - step);//把上面多加的(maxNum - step)减掉
//----------
globalMax[0] = -INFINITY;
globalSum[0] = 0.0;
__sync_all();
__bang_atomic_max(&destNewMax, globalMax, &destNewMax, 1);//globalMax[0]必须初始化为负无穷
destSumFinal[0] = destSumFinal[0] * exp(destOldMax - globalMax[0]);
//__bang_printf("taskId:%d, step:%d, sum:%.6f\n", taskId, step, destSumFinal[0]);
__sync_all();
__bang_atomic_add(destSumFinal, globalSum, destSumFinal, 1);//globalSum[0]必须初始化为0
float globalSumInv = 1.0/globalSum[0];
for(int i = 0; i < repeat; i++){
__memcpy(src2SRAM, source1 + i * size, taskDim * NRAM_MAX_SIZE, GDRAM2SRAM);
__sync_cluster(); //设置sync barrier
__memcpy(src1, src2SRAM + taskId * maxNum, NRAM_MAX_SIZE, SRAM2NRAM);
__bang_sub_scalar(src1, src1, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + i * size + taskId * maxNum, src1, NRAM_MAX_SIZE, NRAM2GDRAM);
}
if(remain){
__bang_write_value(src1, maxNum, globalMax[0]);
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src1, src1, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + repeat * size + indStart, src1, step * sizeof(float), NRAM2GDRAM);
}
__bang_printf("taskId:%d,repeat:%d,max:%.6f, sum:%.6f\n",taskId, repeat, globalMax[0], globalSum[0]);
}
int main(void)
{
int num = 1024 * 1024 * 1024;
//int num = 11;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
}
float* mlu_dst;
float* mlu_src1;
float* globalMax;
float* globalSum;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalMax, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalSum, sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<4><<<dim, ktype, queue>>>(mlu_dst, mlu_src1, globalMax, globalSum, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 10; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(globalMax);
cnrtFree(globalSum);
free(host_dst);
free(host_src1);
return 0;
}
四级流水
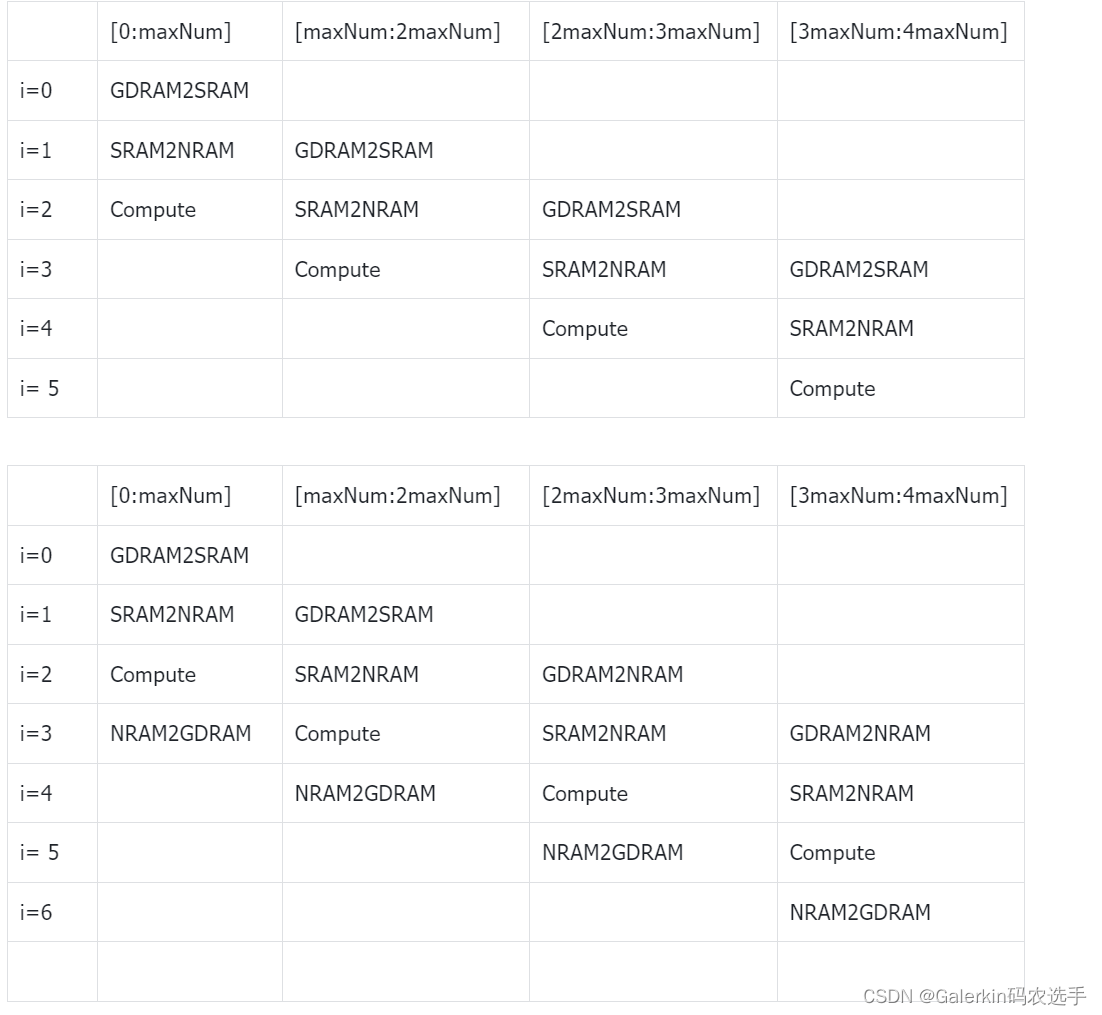
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[4 * maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
template<int taskNum>
__mlu_entry__ void softmaxKernel(float* dst, float* source1, float* globalMax, float* globalSum, int num) {
__mlu_shared__ float src2SRAM[4 * taskNum * maxNum];
int size = taskDim * maxNum;
int remain = num%size;//如果不能整除,则让前部分taskId多处理一个元素
int repeat = (num - remain)/size;
int remainTask = remain%taskDim;
int stepEasy = (remain - remainTask)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remainTask ? stepHard : stepEasy);//前部分taskId多处理一个元素
int indStart = (taskId < remainTask ? taskId * stepHard : remainTask * stepHard + (taskId - remainTask) * stepEasy);
__nram__ float destOldMax;
__nram__ float destNewMax;
__bang_write_zero(destSum, maxNum);
destNewMax = -INFINITY;//初始化为负无穷
for(int i = 0; i < repeat + 2; i++){
if(i < repeat){
__memcpy_async(src2SRAM + i%4 * size, source1 + i * size, taskDim * NRAM_MAX_SIZE, GDRAM2SRAM);
__sync_cluster(); //i=0才需要设置sync barrier
}
if(i > 0 && i < repeat + 1){
__memcpy_async(src1 + (i - 1)%4 * maxNum, src2SRAM + (i - 1)%4 * size + taskId * maxNum, NRAM_MAX_SIZE, SRAM2NRAM);
}
if(i > 1){
__bang_argmax(srcMax, src1 + (i - 2)%4 * maxNum, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(src1 + + (i - 2)%4 * maxNum, src1 + + (i - 2)%4 * maxNum, destNewMax, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(src1 + + (i - 2)%4 * maxNum, src1 + (i - 2)%4 * maxNum, maxNum);//src1 = exp(src1 - 最大值)
if(i > 2){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1 + (i - 2)%4 * maxNum, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
}
__sync_all_ipu();
}
if(remain){
__bang_write_value(src1, 3 * maxNum, -INFINITY);//必须要初始化src1全部元素为负无穷
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, src1, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src1, 3* maxNum, destNewMax);//必须重新初始化为destNewMax
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);//必须再次读取
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//后面maxNum-step部分为0
__bang_active_exp_less_0(src1, src1, maxNum);//相当于多加了maxNum-step
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);
destOldMax = destNewMax;
}
//----------
__bang_write_zero(destSumFinal, warpSize);//初始化destSumFinal全部元素为0
int segNum = maxNum / warpSize;//将destSum分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - step);//把上面多加的(maxNum - step)减掉
//----------
globalMax[0] = -INFINITY;
globalSum[0] = 0.0;
__sync_all();
__bang_atomic_max(&destNewMax, globalMax, &destNewMax, 1);//globalMax[0]必须初始化为负无穷
destSumFinal[0] = destSumFinal[0] * exp(destOldMax - globalMax[0]);
//__bang_printf("taskId:%d, step:%d, sum:%.6f\n", taskId, step, destSumFinal[0]);
__sync_all();
__bang_atomic_add(destSumFinal, globalSum, destSumFinal, 1);//globalSum[0]必须初始化为0
float globalSumInv = 1.0/globalSum[0];
for(int i = 0; i < repeat + 3; i++){
if(i < repeat){
__memcpy_async(src2SRAM + i%4 * size, source1 + i * size, taskDim * NRAM_MAX_SIZE, GDRAM2SRAM);
__sync_cluster(); //i=0才需要设置sync barrier
}
if(i > 0 && i < repeat + 1){
__memcpy_async(src1 + (i - 1)%4 * maxNum, src2SRAM + (i - 1)%4 * size + taskId * maxNum, NRAM_MAX_SIZE, SRAM2NRAM);
}
if(i > 1 && i < repeat + 2){
__bang_sub_scalar(src1 + (i - 2)%4 * maxNum, src1 + (i - 2)%4 * maxNum, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1 + (i - 2)%4 * maxNum, src1 + (i - 2)%4 * maxNum, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(src1 + (i - 2)%4 * maxNum, src1 + (i - 2)%4 * maxNum, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
}
if(i > 2){
__memcpy_async(dst + (i - 3) * size + taskId * maxNum, src1 + (i - 3)%4 * maxNum, NRAM_MAX_SIZE, NRAM2GDRAM);
}
__sync_all_ipu();
}
if(remain){
__bang_write_value(src1, maxNum, globalMax[0]);
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src1, src1, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + repeat * size + indStart, src1, step * sizeof(float), NRAM2GDRAM);
}
__bang_printf("taskId:%d,repeat:%d,max:%.6f, sum:%.6f\n",taskId, repeat, globalMax[0], globalSum[0]);
}
int main(void)
{
int num = 1024 * 1024 * 1024;
//int num = 11;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
}
float* mlu_dst;
float* mlu_src1;
float* globalMax;
float* globalSum;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalMax, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalSum, sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<4><<<dim, ktype, queue>>>(mlu_dst, mlu_src1, globalMax, globalSum, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 10; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(globalMax);
cnrtFree(globalSum);
free(host_dst);
free(host_src1);
return 0;
}
五级流水
上面这个是四级流水,下面这个是五级流水,但是五级流水的运行时间相比于四级流水更长。
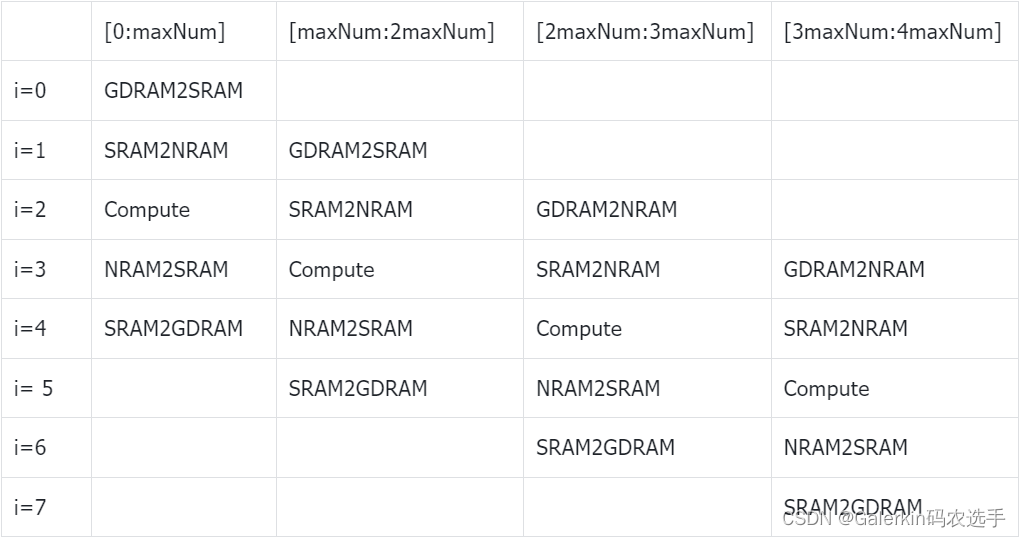
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 64;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[5 * maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
template<int taskNum>
__mlu_entry__ void softmaxKernel(float* dst, float* source1, float* globalMax, float* globalSum, int num) {
__mlu_shared__ float src2SRAM[5 * taskNum * maxNum];
int size = taskDim * maxNum;
int remain = num%size;//如果不能整除,则让前部分taskId多处理一个元素
int repeat = (num - remain)/size;
int remainTask = remain%taskDim;
int stepEasy = (remain - remainTask)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remainTask ? stepHard : stepEasy);//前部分taskId多处理一个元素
int indStart = (taskId < remainTask ? taskId * stepHard : remainTask * stepHard + (taskId - remainTask) * stepEasy);
__nram__ float destOldMax;
__nram__ float destNewMax;
__bang_write_zero(destSum, maxNum);
destNewMax = -INFINITY;//初始化为负无穷
for(int i = 0; i < repeat + 2; i++){
if(i < repeat){
__memcpy_async(src2SRAM + i%5 * size, source1 + i * size, taskDim * NRAM_MAX_SIZE, GDRAM2SRAM);
__sync_cluster(); //设置sync barrier
}
if(i > 0 && i < repeat + 1){
__memcpy_async(src1 + (i - 1)%5 * maxNum, src2SRAM + (i - 1)%5 * size + taskId * maxNum, NRAM_MAX_SIZE, SRAM2NRAM);
}
if(i > 1){
__bang_argmax(srcMax, src1 + (i - 2)%5 * maxNum, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(src1 + + (i - 2)%5 * maxNum, src1 + + (i - 2)%5 * maxNum, destNewMax, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(src1 + + (i - 2)%5 * maxNum, src1 + (i - 2)%5 * maxNum, maxNum);//src1 = exp(src1 - 最大值)
if(i > 2){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1 + (i - 2)%5 * maxNum, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
}
__sync_all_ipu();
}
if(remain){
__bang_write_value(src1, 3 * maxNum, -INFINITY);//必须要初始化src1全部元素为负无穷
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMax, src1, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src1, 3* maxNum, destNewMax);//必须重新初始化为destNewMax
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);//必须再次读取
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//后面maxNum-step部分为0
__bang_active_exp_less_0(src1, src1, maxNum);//相当于多加了maxNum-step
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);
destOldMax = destNewMax;
}
//----------
__bang_write_zero(destSumFinal, warpSize);//初始化destSumFinal全部元素为0
int segNum = maxNum / warpSize;//将destSum分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - step);//把上面多加的(maxNum - step)减掉
//----------
globalMax[0] = -INFINITY;
globalSum[0] = 0.0;
__sync_all();
__bang_atomic_max(&destNewMax, globalMax, &destNewMax, 1);//globalMax[0]必须初始化为负无穷
destSumFinal[0] = destSumFinal[0] * exp(destOldMax - globalMax[0]);
//__bang_printf("taskId:%d, step:%d, sum:%.6f\n", taskId, step, destSumFinal[0]);
__sync_all();
__bang_atomic_add(destSumFinal, globalSum, destSumFinal, 1);//globalSum[0]必须初始化为0
float globalSumInv = 1.0/globalSum[0];
for(int i = 0; i < repeat + 4; i++){
if(i < repeat){
__memcpy_async(src2SRAM + i%5 * size, source1 + i * size, taskDim * NRAM_MAX_SIZE, GDRAM2SRAM);
__sync_cluster(); //设置sync barrier
}
if(i > 0 && i < repeat + 1){
__memcpy_async(src1 + (i - 1)%5 * maxNum, src2SRAM + (i - 1)%5 * size + taskId * maxNum, NRAM_MAX_SIZE, SRAM2NRAM);
}
if(i > 1 && i < repeat + 2){
__bang_sub_scalar(src1 + (i - 2)%5 * maxNum, src1 + (i - 2)%5 * maxNum, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1 + (i - 2)%5 * maxNum, src1 + (i - 2)%5 * maxNum, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(src1 + (i - 2)%5 * maxNum, src1 + (i - 2)%5 * maxNum, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
}
if(i > 2 && i < repeat + 3){
__memcpy_async(src2SRAM + (i - 3)%5 * size + taskId * maxNum, src1 + (i - 3)%5 * maxNum, NRAM_MAX_SIZE, NRAM2SRAM);
}
if(i > 3){
__memcpy_async(dst + (i - 4) * size, src2SRAM + (i - 4)%5 * size, taskDim * NRAM_MAX_SIZE, SRAM2GDRAM);
}
__sync_all_ipu();
}
if(remain){
__bang_write_value(src1, maxNum, globalMax[0]);
__memcpy(src1, source1 + repeat * size + indStart, step * sizeof(float), GDRAM2NRAM);
__bang_sub_scalar(src1, src1, globalMax[0], maxNum);//src1 = src1 - globalMax[0]
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - globalMax[0])
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst + repeat * size + indStart, src1, step * sizeof(float), NRAM2GDRAM);
}
__bang_printf("taskId:%d,repeat:%d,max:%.6f, sum:%.6f\n",taskId, repeat, globalMax[0], globalSum[0]);
}
int main(void)
{
int num = 1024 * 1024 * 1024;
//int num = 11;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
}
float* mlu_dst;
float* mlu_src1;
float* globalMax;
float* globalSum;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalMax, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&globalSum, sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<4><<<dim, ktype, queue>>>(mlu_dst, mlu_src1, globalMax, globalSum, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 10; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(globalMax);
cnrtFree(globalSum);
free(host_dst);
free(host_src1);
return 0;
}

高维向量的softmax
高维向量的softmax实现更加复杂,回忆之前在英伟达平台上实现高维向量的softmax函数,比如说我们以形状为[1,2,3,4,5,6]的6维向量举例,变换维度假设axis=2,之前英伟达平台的实现,我们计算出变换维度的长度dimsize=3,其他维度的乘积othersize=1×2×4×5×6 = 240,步长stride= 1×6×5×4 = 120,使用othersize=240个线程块,其中每个线程块处理对应一份数据,计算出int tid =blockIdx.x % stride + (blockIdx.x - blockIdx.x % stride) × dimsize;全局索引为tid + threadIdx.x × stride,类似地,我们也按照这个思路来实现寒武纪显卡上的高维向量softmax:
我们利用taskId来处理othersize,但是考虑到taskDim往往是2或者4的倍数,而othersize不一定满足这个条件,因此我们使用for循环来解决,参考for(int otherIdx = taskId; otherIdx < othersize; otherIdx += taskDim)
进入上述for循环以后,我们尝试来处理dimsize,由于寒武纪的函数基本上支持向量操作,无法针对具体某个元素来处理,为此我们仍然把dimsize这份数据按照maxNum长度分成多个小单元,如果不能整除后面特殊处理,特殊处理的方式和上面一维向量一模一样。在代码24行——25行,这里使用两层for循环来加载数据,高维数组导致每次处理的数据不连续,间隔stride,为此必须要不断遍历数组把结果集中到src1数组上处理,后续的处理类似,这里不做赘述。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 4;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
__mlu_entry__ void softmaxKernel(float* dst, float* source1, int othersize, int dimsize, int stride) {
int remain = dimsize%maxNum;
int repeat = (dimsize - remain)/maxNum;
__nram__ float destOldMax;
__nram__ float destNewMax;
//下面利用taskId来处理其他维度
for(int otherIdx = taskId; otherIdx < othersize; otherIdx += taskDim){
destOldMax = -INFINITY;
destNewMax = -INFINITY;
__bang_write_zero(destSum, maxNum);
int tid = otherIdx % stride + (otherIdx - otherIdx % stride) * dimsize;
for(int i = 0; i < repeat; i++){
for(int j = 0; j < maxNum; j++){//从source1间隔stride读取数据
__memcpy(src1 + j, source1 + tid + (i * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_argmax(srcMax, src1, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(src1, src1, maxNum);//src1 = exp(src1 - 最大值)
if(i > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
}
//-------------------------------------
if(remain){
__bang_write_value(src1, maxNum, -INFINITY);//多余部分必须设置负无穷
for(int j = 0; j < remain; j++){
__memcpy(src1 + j, source1 + tid + (repeat * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_argmax(srcMax, src1, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src1, maxNum, destNewMax);//必须重新初始化为destNewMax
for(int j = 0; j < remain; j++){
__memcpy(src1 + j, source1 + tid + (repeat * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//后面maxNum-remain部分为0
__bang_active_exp_less_0(src1, src1, maxNum);//相当于多加了maxNum-remain
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);
destOldMax = destNewMax;
}
//--------------------------------
__bang_write_zero(destSumFinal, warpSize);
int segNum = maxNum / warpSize;
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - remain);
//__bang_printf("--max:%.3e,sum:%.6e,:%d\n",destNewMax,destSumFinal[0], maxNum - remain);
//------------------------------------至此全局最大值为destNewMax,全局数值和为destSumFinal[0]
float globalSumInv = 1.0/destSumFinal[0];
for(int i = 0; i < repeat; i++){
for(int j = 0; j < maxNum; j++){
__memcpy(src1 + j, source1 + tid + (i * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);
__bang_active_exp_less_0(src1, src1, maxNum);
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
for(int j = 0; j < maxNum; j++){
__memcpy(dst + tid + (i * maxNum + j) * stride, src1 + j, sizeof(float), NRAM2GDRAM);
}
}
if(remain){
__bang_write_value(src1, maxNum, destNewMax);
for(int j = 0; j < remain; j++){
__memcpy(src1 + j, source1 + tid + (repeat * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);
__bang_active_exp_less_0(src1, src1, maxNum);
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
for(int j = 0; j < remain; j++){
__memcpy(dst + tid + (repeat * maxNum + j) * stride, src1 + j, sizeof(float), NRAM2GDRAM);
}
}
}
}
int main(void)
{
int num = 32 * 16 * 64 * 128;//shape = {32, 16, 64, 128},axis = 2
int stride = 128;
int dimsize = 64;
int othersize = 32 * 16 * 128;
/***
int num = 24;//shape = {2,3,2,2}, axis = 1
int stride = 4;
int dimsize = 3;
int othersize = 8;
***/
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
//host_src1[i] = i;
}
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, othersize, dimsize, stride);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}
高维向量的pingpong流水
此时流水无法加速
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 4;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[3 * maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destSum[maxNum];//后面数值求和
__nram__ float destSumFinal[warpSize];//将destSum规约到destFinal[0]
__nram__ float srcMax[2];
__mlu_entry__ void softmaxKernel(float* dst, float* source1, int othersize, int dimsize, int stride) {
int remain = dimsize%maxNum;
int repeat = (dimsize - remain)/maxNum;
__nram__ float destOldMax;
__nram__ float destNewMax;
//下面利用taskId来处理其他维度
for(int otherIdx = taskId; otherIdx < othersize; otherIdx += taskDim){
destOldMax = -INFINITY;
destNewMax = -INFINITY;
__bang_write_zero(destSum, maxNum);
int tid = otherIdx % stride + (otherIdx - otherIdx % stride) * dimsize;
for(int i = 0; i < repeat + 1; i++){
if(i < repeat){
for(int j = 0; j < maxNum; j++){//从source1间隔stride读取数据
__memcpy_async(src1 + i%2 * maxNum + j, source1 + tid + (i * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
}
if(i > 0){
__bang_argmax(srcMax, src1 + (i - 1)%2 * maxNum, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];//更新最大值
}
__bang_sub_scalar(src1 + (i - 1)%2 * maxNum, src1 + (i - 1)%2 * maxNum, destNewMax, maxNum);//src1 = src1 - 最大值
__bang_active_exp_less_0(src1 + (i - 1)%2 * maxNum, src1 + (i - 1)%2 * maxNum, maxNum);//src1 = exp(src1 - 最大值)
if(i > 1){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1 + (i - 1)%2 * maxNum, maxNum);//destSum = destSum + exp(src1 - destNewMax)
destOldMax = destNewMax;
}
//__sync_all_ipu();
}
//-------------------------------------
if(remain){
__bang_write_value(src1, maxNum, -INFINITY);//多余部分必须设置负无穷
for(int j = 0; j < remain; j++){
__memcpy(src1 + j, source1 + tid + (repeat * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_argmax(srcMax, src1, maxNum);
if(destNewMax < srcMax[0]){
destNewMax = srcMax[0];
}
__bang_write_value(src1, maxNum, destNewMax);//必须重新初始化为destNewMax
for(int j = 0; j < remain; j++){
__memcpy(src1 + j, source1 + tid + (repeat * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);//后面maxNum-remain部分为0
__bang_active_exp_less_0(src1, src1, maxNum);//相当于多加了maxNum-remain
if(repeat > 0){
__bang_mul_scalar(destSum, destSum, exp(destOldMax - destNewMax), maxNum);
}
__bang_add(destSum, destSum, src1, maxNum);
destOldMax = destNewMax;
}
//--------------------------------
__bang_write_zero(destSumFinal, warpSize);
int segNum = maxNum / warpSize;
for(int strip = segNum/2; strip > 0; strip = strip / 2){
for(int i = 0; i < strip ; i++){
__bang_add(destSum + i * warpSize, destSum + i * warpSize, destSum + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destSumFinal, destSum, warpSize);
destSumFinal[0] = destSumFinal[0] - (maxNum - remain);
//__bang_printf("--max:%.3e,sum:%.6e,:%d\n",destNewMax,destSumFinal[0], maxNum - remain);
//------------------------------------至此全局最大值为destNewMax,全局数值和为destSumFinal[0]
float globalSumInv = 1.0/destSumFinal[0];
for(int i = 0; i < repeat + 2; i++){
if(i < repeat){
for(int j = 0; j < maxNum; j++){
__memcpy_async(src1 + i%3 * maxNum + j, source1 + tid + (i * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
}
if(i > 0){
__bang_sub_scalar(src1 + (i - 1)%3 * maxNum, src1 + (i - 1)%3 * maxNum, destNewMax, maxNum);
__bang_active_exp_less_0(src1 + (i - 1)%3 * maxNum, src1 + (i - 1)%3 * maxNum, maxNum);
__bang_mul_scalar(src1 + (i - 1)%3 * maxNum, src1 + (i - 1)%3 * maxNum, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
}
if(i > 1){
for(int j = 0; j < maxNum; j++){
__memcpy_async(dst + tid + ((i - 2) * maxNum + j) * stride, src1 + (i - 2)%3 * maxNum + j, sizeof(float), NRAM2GDRAM);
}
}
//__sync_all_ipu();
}
if(remain){
__bang_write_value(src1, maxNum, destNewMax);
for(int j = 0; j < remain; j++){
__memcpy(src1 + j, source1 + tid + (repeat * maxNum + j) * stride, sizeof(float), GDRAM2NRAM);
}
__bang_sub_scalar(src1, src1, destNewMax, maxNum);
__bang_active_exp_less_0(src1, src1, maxNum);
__bang_mul_scalar(src1, src1, globalSumInv, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
for(int j = 0; j < remain; j++){
__memcpy(dst + tid + (repeat * maxNum + j) * stride, src1 + j, sizeof(float), NRAM2GDRAM);
}
}
}
}
int main(void)
{
int num = 32 * 16 * 64 * 128;//shape = {32, 16, 64, 128},axis = 2
int stride = 128;
int dimsize = 64;
int othersize = 32 * 16 * 128;
/***
int num = 24;//shape = {2,3,2,2}, axis = 1
int stride = 4;
int dimsize = 3;
int othersize = 8;
***/
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = i%4;
//host_src1[i] = i;
}
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
//----------------------------
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
softmaxKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, othersize, dimsize, stride);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for(int i = 0; i < 24; i++){
printf("softmax[%d]:%.6e,origin:%.6f\n", i, host_dst[i], host_src1[i]);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}















 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











