






Graph
基本概念
- Tensorflow里的Graph类似于数据流图,节点为计算单位(通常为tf.Operation),边通常为用于计算的数据(如tf.Variable)。指向运算节点的边表示输入,向外的边则表示输出。
- 在建立计算图的时候,通常包括建立tf.Operation (node)和tf.Tensor (edge)对象,然后加入到tf.Graph当中。未声明特定的Graph时则加入到默认图中。
- Example
tf.matmul(x,y)创建了一个tf.Operation对象,对tf.Tensor x, tf.Tensor y进行乘法运算,并加入到default graph中,返回tf.Tensor表示结果。
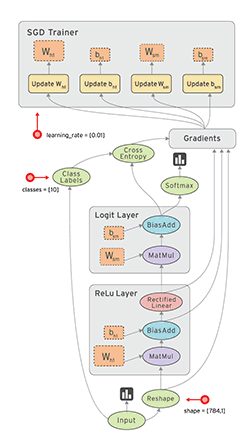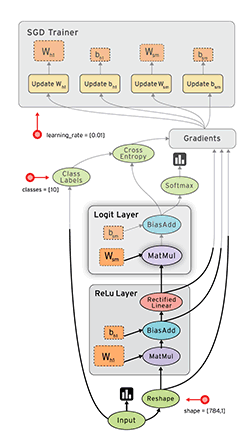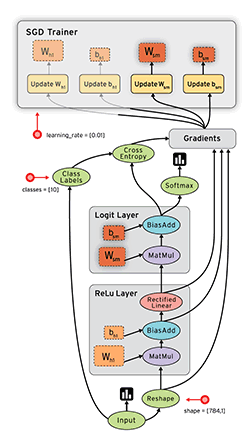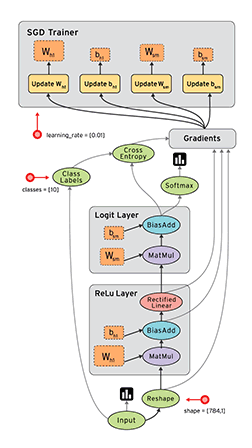
命名空间
- tf.Graph会给其图内的tf.Operation定义一个namespace。TF为给图中的Operation一个唯一的name,也可以手动给其赋一个name覆盖默认的命名。覆盖的方法有两种
- 通过自带API函数的可选参数: tf.constant(42.0, name = “answer”),创建的tf.Operation命名为answer返回的tf.Tensor命名为answer:0。若改图中已经有叫answer的Operation了,则命名为answer_1来保证唯一性。
- 使用tf.name_scope关键字。
- Example:
- 通过Operation的参数
c_0 = tf.constant(0, name="c") # => operation named "c"
# Already-used names will be "uniquified".
c_1 = tf.constant(2, name="c") # => operation named "c_1"- 通过name_scope
# Name scopes add a prefix to all operations created in the same context.
with tf.name_scope("outer"):
c_2 = tf.constant(2, name="c") # => operation named "outer/c"
# Name scopes nest like paths in a hierarchical file system.
with tf.name_scope("inner"):
c_3 = tf.constant(3, name="c") # => operation named "outer/inner/c"
# Exiting a name scope context will return to the previous prefix.
c_4 = tf.constant(4, name="c") # => operation named "outer/c_1"PS: 返回的Tensor的名字为OP_NAME:i
OP_NAME:产生改Tensor的Operation的名字
i:Operation的第i个输出
多设备计算
- tf.device 可以让同一context下的operation在多设备或者某一设备上计算。声明使用特定的device的格式:/job:/task:/device:: 其中(不需要全部填满):
- 工作名
- 工作的某个任务的任务编号
- 载入的CPU或者GPU
- CPU或者GPU的编号
- Example:
- 仅声明使用特定设备
with tf.device("/device:CPU:0"):
# Operations created in this context will be pinned to the CPU.
img = tf.decode_jpeg(tf.read_file("img.jpg"))
with tf.device("/device:GPU:0"):
# Operations created in this context will be pinned to the GPU.
result = tf.matmul(weights, img)
- 在分布式计算中,常把计算资源分成两个部分,参数服务器(Parameter Server)和工作节点(Worker):参数服务器节点用来存储参数,工作节点部分用来做算法的训练。对应的也罢机器学习算法分成两个部分,参数和训练,参数部分即模型本身,有一致性的要求,参数服务器也可以是一个集群,训练部分自然是并行的,不然无法体现分布式机器学习的优势。因为参数服务器的存在,每个计算节点在拿到新的batch数据之后,都要从参数服务器上取下最新的参数,然后计算梯度,再将梯度更新回参数服务器。具体会再写一篇来讲。
- 在分布式集群下的任务分配例子
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(tf.truncated_normal([784, 100]))
biases_1 = tf.Variable(tf.zeroes([100]))
with tf.device("/job:ps/task:1"):
weights_2 = tf.Variable(tf.truncated_normal([100, 10]))
biases_2 = tf.Variable(tf.zeroes([10]))
with tf.device("/job:worker"):
layer_1 = tf.matmul(train_batch, weights_1) + biases_1
layer_2 = tf.matmul(train_batch, weights_2) + biases_2PS: tf.train.replica_device_setter API可以自动为算子(Operation)分配计算资源,即哪些运算分给PS,哪些运算分给Worker:
with tf.device(tf.train.replica_device_setter(ps_tasks=3)):
#PS用来存参数
w_0 = tf.Variable(...) # placed on "/job:ps/task:0"
b_0 = tf.Variable(...) # placed on "/job:ps/task:1"
w_1 = tf.Variable(...) # placed on "/job:ps/task:2"
b_1 = tf.Variable(...) # placed on "/job:ps/task:0"
# 其他operation给worker进行计算
input_data = tf.placeholder(tf.float32) # placed on "/job:worker"
layer_0 = tf.matmul(input_data, w_0) + b_0 # placed on "/job:worker"
layer_1 = tf.matmul(layer_0, w_1) + b_1 # placed on "/job:worker"Session
- 由于tensorflow底层是使用C++/写的,所以Tensorflow使用tf.Session类来代表客户端程序(python脚本)和底层C++运行状态的桥梁。
- Session是Graph和执行者之间的媒介,Session.run()实际上将graph、fetches、feed_dict序列化到字节数组中,并调用tf_session.TF_Run
- 创建Session,通常一个session有自己的物理资源(包括GPU,网络连接等等):
#使用default Session
with tf.Session() as sess:
# ...
# 创建远程Session
with tf.Session("grpc://example.org:2222"):
# ...- 创建Session对象的具体用法,tf.Session接手以下几个参数:
- target:若为空,则Session只能使用本机的device,若为grpc://URL,则可以使用改TF Server控制下的所有devices。
- graph:默认用来运行default graph中的Operations。除非特别声明特定Graph。
- config:一些基础设置
- allow_soft_placement:True,则会忽略tf.device的特定device的声明,例如将CPU-only的运算给GPU
- tf.Session.run
前面创建的计算图实际上并不会进行计算,若要进行计算,一般将需要的传入一串fetches,所谓fetches是指能够用来表示output计算子图(subgraph)的返回值,可以是tf.Operation,tf.Variable,tf.Tensor等等,例如:
x = tf.constant([[37.0, -23.0], [1.0, 4.0]])
w = tf.Variable(tf.random_uniform([2, 2]))
y = tf.matmul(x, w)
output = tf.nn.softmax(y)
init_op = w.initializer
with tf.Session() as sess:
# 传入一个Operation,对涉及该Operation的子图进行计算
sess.run(init_op)
# 传入一个Tensor,对涉及该Tensor的子图进行计算
print(sess.run(output))
# 此时y只会被计算一次
y_val, output_val = sess.run([y, output])当然,tf.Session.run()也可以接受一个dict of feeds对涉及占位符(placeholder)的子图进行计算:
x = tf.placeholder(tf.float32, shape=[3])
y = tf.square(x)
with tf.Session() as sess:
# Feeding a value changes the result that is returned when you evaluate `y`.
print(sess.run(y, {x: [1.0, 2.0, 3.0]}) # => "[1.0, 4.0, 9.0]"
print(sess.run(y, {x: [0.0, 0.0, 5.0]}) # => "[0.0, 0.0, 25.0]"














 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









