






目录
2. 支持向量机(Support Vector Machine, SVM)
5. 梯度提升树(Gradient Boosting Trees, GBT)
6. 长短期记忆网络(Long Short-Term Memory, LSTM)
7. 卷积神经网络(Convolutional Neural Network, CNN)
研究目的:
随着全球气候变化的加剧,极端天气事件频发,对农业、水利、交通等多个领域产生重要影响。传统的降雨量预测方法依赖于气象观测站等固定的监测点数据,难以获取全面的降雨信息。而机器学习算法具有强大的非线性特征表达能力,能够从大量历史数据中提取出复杂的关系,实现降雨量的准确预测。本研究旨在基于机器学习技术,构建一个高效、准确的降雨量预测系统,旨在提升降雨量预测的精度和时效性,为相关领域的决策提供数据支持,减少极端天气事件可能带来的负面影响。
研究意义:
提高农业生产的稳定性:降雨量的准确预测对于农业灌溉决策至关重要,有助于农民合理安排种植和灌溉,提高农业生产的稳定性和可持续性。
优化水资源管理:可以为水资源的调度和分配提供科学依据,减少洪涝灾害和干旱缺水的情况,提高水资源的利用效率。
减少交通拥堵和事故:高质量的降雨预测可以为交通管理部门提供预警信息,提前做好交通疏导和应急准备,降低极端天气导致的交通拥堵和事故。
环境保护与防灾减灾:准确的降雨预测能够在恶劣天气到来之前采取措施,减少环境破坏和灾害损失,提高社会应对极端天气的能力。
研究内容:
本研究的主要内容包括:
- 数据收集与预处理:收集历史降雨数据、气象数据及相关环境因素,并对其进行清洗、规范化等预处理。
- 特征选择与提取:分析对降雨量预测有重要影响的特征,并采用特征提取技术简化数据,提高预测精度。
- 机器学习模型构建:根据数据特点选择合适的机器学习算法(如SVM、BP神经网络、随机森林、LSTM等)构建降雨量预测模型。
- 模型训练与评估:利用历史数据对模型进行训练,并通过交叉验证等方式评估模型的性能。
- 系统集成与应用:将训练好的模型集成到降雨量预测系统中,实现实时预测,并通过实际应用不断优化系统。
需求分析:
- 用户需求:气象部门、水利部门、交通管理部门、农业种植户等不同用户群体,他们需要准确及时的降雨量预测信息,以做出科学合理的规划和决策。
- 功能需求:
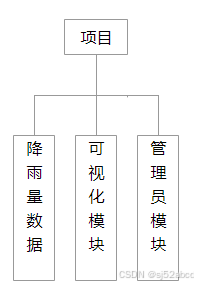
- 数据收集与管理:系统应能够收集多源数据,并进行高效的管理和处理。
- 实时预测:基于实时或最近的观测数据,系统能够快速给出降雨量的预测结果。
- 可视化展示:提供直观的数据展示,包括降雨量预测图、历史降雨数据对比图等。
- 预警机制:一旦预测到可能的极端降雨事件,系统会自动发出预警,提醒相关部门做好准备。
- 用户操作界面:设计简洁、易于操作的用户界面,方便用户快速获取所需信息。
可行性分析:
- 经济可行性:虽然机器学习算法的开发需要一定的经济投入,但随着技术的成熟和应用的推广,成本将逐渐降低。同时,准确降雨量的预测能够减少灾害损失和对经济的负面影响,具有良好的经济效益。
- 社会可行性:社会对天气预报的需求日益增长,对于降雨量预测的需求也随之增加。本系统能够提供高效、准确的降雨量预测信息,有助于提升社会应对极端天气的能力。
- 技术可行性:机器学习算法在降雨量预测方面的应用已经取得了一定的研究成果,证明技术上具有可行性。快速发展的计算能力和大数据技术将进一步促进系统的优化和实时性预测。
功能分析:
- 用户管理与权限控制:系统应提供用户注册、登录、权限分配等功能。
- 数据收集与处理模块:能够自动收集来自不同气象站点的降雨量数据,并进行数据清洗、规范化等预处理。
- 特征提取模块:根据用户设定或者系统自动识别,提取对降雨量预测有重要影响的特征。
- 机器学习模型训练与预测模块:利用训练数据对模型进行训练,实时或定时输出降雨量的预测结果。
- 数据展示与预警模块:提供直观的降雨量预测图、历史数据对比图等,能够根据预测结果自动预警。
- 用户交互模块:提供用户操作界面,方便用户查询、导出数据和反馈意见。
降雨量预测系统的核心在于数据的处理和预测模型的构建。机器学习算法作为一种强大的工具,能够从历史数据中学习并进行降雨量预测。以下是一些常用的机器学习算法及其在降雨量预测中的应用:
1. 线性回归(Linear Regression)
线性回归是一种基础的回归分析方法,用于预测连续值。其核心思想是通过拟合一条线性关系来预测目标变量。在线性回归中,降雨量预测可以通过历史气象数据(如温度、湿度、风速等)建立线性模型。然而,由于降雨量预测中可能存在复杂的非线性关系,线性回归的应用可能受到限制。
2. 支持向量机(Support Vector Machine, SVM)
支持向量机是一种用于分类和回归分析的监督学习模型。SVM通过寻找最佳的超平面来最大化样本点与超平面的间隔。对于降雨量预测,SVM可以通过核函数将数据映射到高维空间,捕捉数据中的非线性特征。SVM具有较好的鲁棒性,但在大规模数据集上可能会面临计算挑战。
3. 决策树(Decision Tree)
决策树是一种基于树结构的分类和回归模型。通过构建一棵树,决策树模型可以对输入特征进行递归划分,最终预测目标变量。对于降雨量预测,决策树能够处理复杂的特征交互关系,易于理解和解释。然而,单棵决策树可能存在过拟合问题,因此通常与集成方法结合使用。
4. 随机森林(Random Forest)
随机森林是由多棵决策树组成的集成学习方法,通过集成多棵决策树的预测结果来提高预测性能。随机森林在降雨量预测中表现出较好的性能,因为它能够通过随机选择特征和样本来减少过拟合,并提高模型的泛化能力。
5. 梯度提升树(Gradient Boosting Trees, GBT)
梯度提升树是一种提升模型性能的集成学习方法,通过逐步训练决策树来纠正前一棵树的错误。常见的实现包括梯度提升回归树(GBRT)和XGBoost。GBT在处理非线性关系和特征交互方面表现优异,能够有效提高降雨量预测的准确性。
6. 长短期记忆网络(Long Short-Term Memory, LSTM)
长短期记忆网络是一种特殊的递归神经网络(RNN),适合处理时间序列数据。LSTM能够捕捉时间序列中的长短期依赖关系,对于降雨量预测中的时间序列数据尤其有效。通过对历史降雨数据及其他气象因素的学习,LSTM能够提供较为准确的预测结果。
7. 卷积神经网络(Convolutional Neural Network, CNN)
卷积神经网络主要用于图像处理,但在降雨量预测中也可以应用。通过将气象数据转化为图像形式,CNN能够利用其强大的特征提取能力捕捉数据中的空间和局部特征,从而提高预测准确性。
8. 混合模型
混合模型结合了多种机器学习算法的优点。比如,可以将SVM与决策树、LSTM与随机森林等组合起来,通过集成不同模型的预测结果,进一步提高降雨量预测的精度和稳定性。
算法选择的考虑因素
- 数据特性:选择合适的算法需要考虑数据的类型和特征,例如时间序列数据适合LSTM,复杂的非线性关系可以选择GBT或SVM。
- 计算资源:不同算法对计算资源的需求不同,深度学习模型(如LSTM、CNN)通常需要较高的计算资源。
- 预测精度:通过交叉验证和模型评估选择预测精度较高的算法。
- 模型解释性:对于需要解释预测结果的应用场景,选择决策树或随机森林等解释性较强的模型。
随机森林算法:
实践中的应用
在实际应用中,降雨量预测系统通常会结合多种算法,并通过实验和优化选择最合适的模型。例如,可以使用数据预处理技术(如特征选择、归一化)和模型优化技术(如超参数调整、交叉验证)来提升预测效果。同时,模型的训练和测试也需要进行不断的调整和验证,以适应不同区域和时间段的降雨量变化。
输入:
- 历史降雨量数据集 DD,其中每个样本 xixi 包含多个气象特征(如温度、湿度、风速等)和对应的降雨量 yiyi。
- 预测时间点 tt 的气象特征数据 xtxt。
输出:
- 预测时间点 tt 的降雨量预测值 y^ty^t。
步骤:
-
数据预处理:
- 对历史数据集 DD 进行清洗,去除缺失或异常值。
- 对数据进行归一化或标准化处理,确保每个特征具有相似的尺度。
-
特征选择:
- 分析气象特征与降雨量之间的相关性。
- 选择与降雨量高度相关的特征子集。
-
划分训练集和测试集:
- 将历史数据集 DD 随机划分为训练集 DtrainDtrain 和测试集 DtestDtest,通常使用70%-80%的数据作为训练集,其余作为测试集。
-
模型训练:
- 使用训练集 DtrainDtrain 训练随机森林模型。
- 调整随机森林模型的参数,如树的数量(n_estimators)、最大深度(max_depth)等,以优化模型性能。
-
模型评估:
- 使用测试集 DtestDtest 评估模型的性能。
- 计算评估指标,如均方误差(MSE)、均方根误差(RMSE)或决定系数(R2R2 分数)等。
-
降雨量预测:
- 将预测时间点 tt 的气象特征数据 xtxt 输入到训练好的随机森林模型中。
- 模型输出预测时间点 tt 的降雨量预测值 y^ty^t。
-
结果后处理:
- 根据需要对预测结果进行反归一化或反标准化处理。
- 可视化预测结果,与实际降雨量进行对比分析。
1. 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
2. 数据预处理
# 读取数据
data = pd.read_csv('rainfall_data.csv') # 请根据实际情况修改文件路径
# 查看数据前几行
print(data.head())
# 假设数据中包含 'Temperature', 'Humidity', 'WindSpeed' 等特征和 'Rainfall' 作为目标值
features = ['Temperature', 'Humidity', 'WindSpeed'] # 选择特征列
target = 'Rainfall' # 目标列
# 提取特征和目标值
X = data[features]
y = data[target]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
3. 构建并训练随机森林模型
# 初始化随机森林回归模型
model = RandomForestRegressor(n_estimators=100, max_depth=10, random_state=42)
# 训练模型
model.fit(X_train, y_train)
4. 模型评估
# 使用测试集进行预测
y_pred = model.predict(X_test)
# 计算模型性能指标
mse = mean_squared_error(y_test, y_pred)
rmse = mse ** 0.5
r2 = r2_score(y_test, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"均方根误差 (RMSE): {rmse}")
print(f"决定系数 (R^2): {r2}")
5. 可视化预测结果(可选)
# 可视化预测结果与实际值的对比
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, alpha=0.7)
plt.xlabel('实际降雨量')
plt.ylabel('预测降雨量')
plt.title('实际降雨量 vs 预测降雨量')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--')
plt.grid(True)
plt.show()
6. 保存模型(可选)
import joblib
# 保存训练好的模型到文件
joblib.dump(model, 'rainfall_model.pkl')
7. 加载和使用模型(可选)
# 加载保存的模型
loaded_model = joblib.load('rainfall_model.pkl')
# 使用加载的模型进行预测
new_data = pd.DataFrame({
'Temperature': [20],
'Humidity': [80],
'WindSpeed': [5]
})
prediction = loaded_model.predict(new_data)
print(f"预测的降雨量: {prediction[0]}")

















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











