






AI计算是一种计算机器学习算法的数学密集型流程,通过加速系统和软件,从大量数据集中提取新的见解并在此过程中学习新能力。
AI计算的三个主要过程包括:
1)提取/转换/加载数据(ETL):数据科学家需要整理和准备数据集。
2)选择或设计AI模型:数据科学家选择或设计最适合其应用的AI模型,一些公司会从一开始就设计并训练自己的模型,另一些公司可能采用预训练模型并根据需求进行自定义。
3)AI推理:企业通过模型对数据进行筛选,AI在此过程中提供可行的洞察与见解。
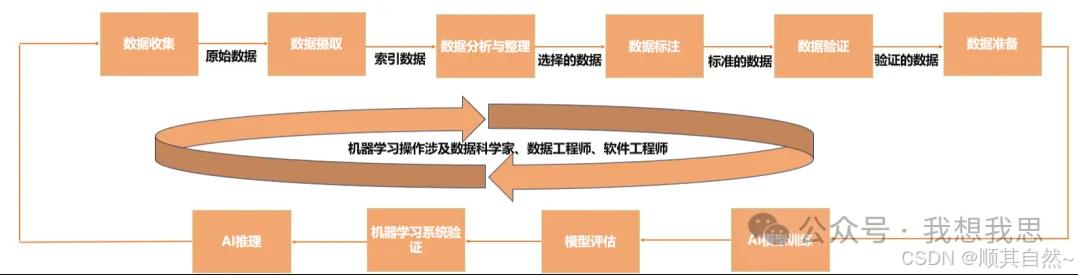
图1 AI计算的生命周期
算力及AI算力主要芯片的分类
算力通常是指计算机处理信息的能力,特别是在进行数学运算、数据处理和执行程序时的速度和效率。根据使用设备和提供算力强度的不同,算力可分为:基础算力、智能算力、超算算力。智能算力即AI算力,是面向AI应用,提供AI算法模型训练与模型运行服务的计算机系统能力,其算力芯片通常包括GPU、ASIC、FPGA、NPU等各类专用芯片。
基础算力:由基于CPU芯片的服务器所提供的算力,主要用于基础通用计算,如移动计算和物联网等。日常提到的云计算、边缘计算等均属于基础算力。
智能算力:基于GPU(图像处理器)、FPGA(现场可编程逻辑门阵列)、ASIC(专用集成电路)等AI芯片的加速计算平台提供的算力,主要用于AI的训练和推理计算,比如语音、图像和视频的处理。
超算算力:由超级计算机等高性能计算集群所提供的算力,主要用于尖端科学领域的计算,比如行星模拟、药物分子设计、基因分析等。
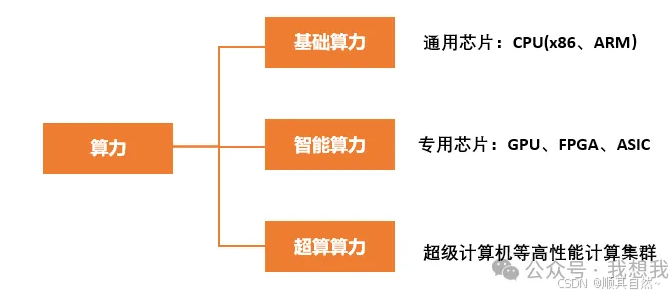
图2 算力的主要分类

图3 AI算力芯片的主要分类
算力的常见单位
在计算机领域,常用算力的衡量指标包括FLOPS (每秒浮点运算次数)、OPS (每秒运算次数)。FLOPS特别适用于评估超级计算机、高性能计算服务器和GPU等设备的计算性能。
在计算性能的度量中,常见单位包括Kilo/Mega/Giga/Tera/Peta/Exa,算力通常以 PetaFlOPS(每秒千万亿次浮点运算)单位来衡量。
AI 算力常见单位分为TOPS和TFLOPS。推理算力,即通常用设备处理实时任务的能力,通常以TOPS(每秒万亿次操作)为单位来衡量。而训练算力,即设备的学习能力和数据处理能力,常用TFLOPS(每秒万亿次浮点操作)来衡量。TFLOPS数值越高,反映了模型在训练时的效率越高。

图4 算力的通常计量单位
不同场景对应算力精度表示不同
算力精度作为可以衡量算力水平的一种方式,可分为浮点计算和整型计算。其中浮点计算可细分为半精度(2Bytes,FP16)、单精度(4Bytes,FP32)和双精度(8Bytes,FP64)浮点计算,加上整型精度(1Byte,INT8)。
不同场景对应算力精度表示不同。FP64主要用于对精度要求很高的科学计算,如制造产品设计、机械模拟和Ansys应用中的流体动力学,AI训练场景下支持FP32和FP16,模型推理阶段支持FP16和INT8。

表5 常见浮点/整型规格及定义
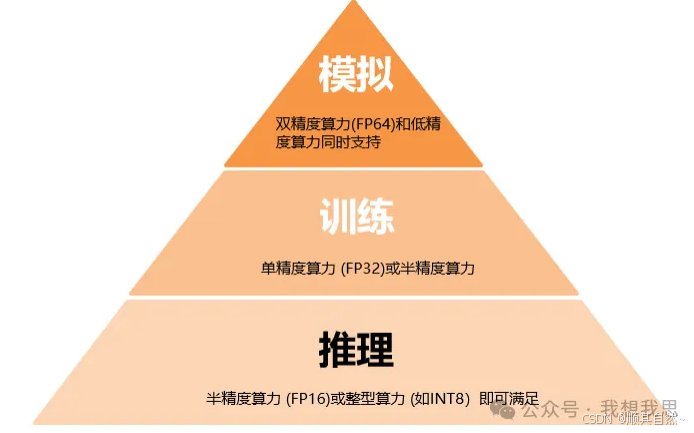
图6 不同精度可执行任务对比
稀疏算力和稠密算力
稀疏算力和稠密算力用于描述计算资源的利用程度。在实际场景中,稀疏算力和稠密算力存在互补关系与转换关系。
稠密算力:指的是在计算过程中,数据点之间的管理都较高,需要处理大量连续的数据。通常用于需要密集型计算的任务,如图像处理、视频编码、大规模数值模拟等
稀疏算力:指在计算过程中,数据点之间的关联度较低,数据分布稀疏。这种算力常用于处理稀疏矩阵或者稀疏数据集,如社交网络分析、推荐系统、基因序列分析等。
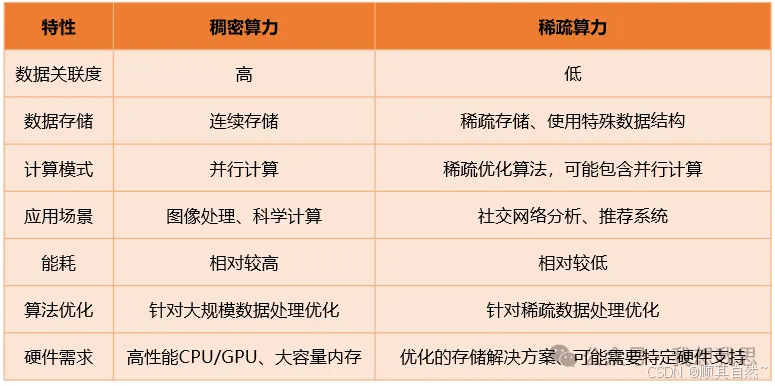
表1 稠密算力与稀疏算力特性对比
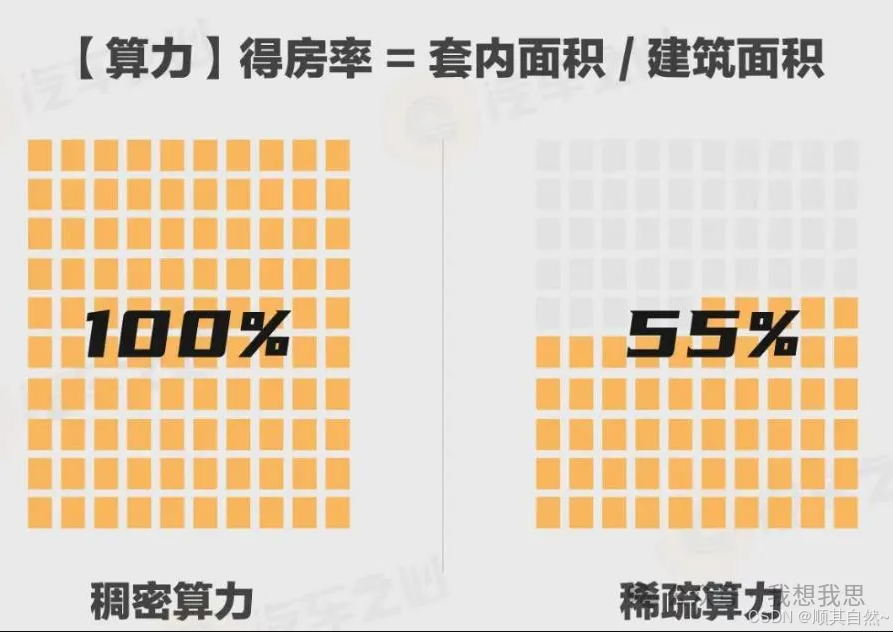
图7 稠密算力与稀疏算力结构对比
AI芯片架构与参数
AI芯片通常采用GPU与ASIC架构
目前通用的CPU、GPU、FPGA等都能执行AI算法,只是执行效率差异较大。但狭义上讲一般将AI芯片定义为“专门针对AI算法做了特殊加速设计的芯片”。AI芯片可以分为GPU、FPGA和ASIC架构,根据场景可以分为云端和端侧。和其他芯片相比,AI芯片重点增强了运行AI算法的能力。
目前主流AI芯片为GPU和ASIC。国际上,Nvidia的H200 Tensor Core GPU以其卓越的计算性能和能效比领先市场,而Google的第六代TPU Trillium ASIC芯片则以其专为机器学习优化的设计提供高速数据处理。在国内,寒武纪的思元370芯片(ASIC)凭借其先进的计算处理能力在智能计算领域占据重要地位,已与主流互联网厂商开展深入适配;海光信息的DCU系列基于GPGPU架构,以其类“CUDA”通用并行计算架构较好地适配、适应国际主流商业计算软件和AI软件。
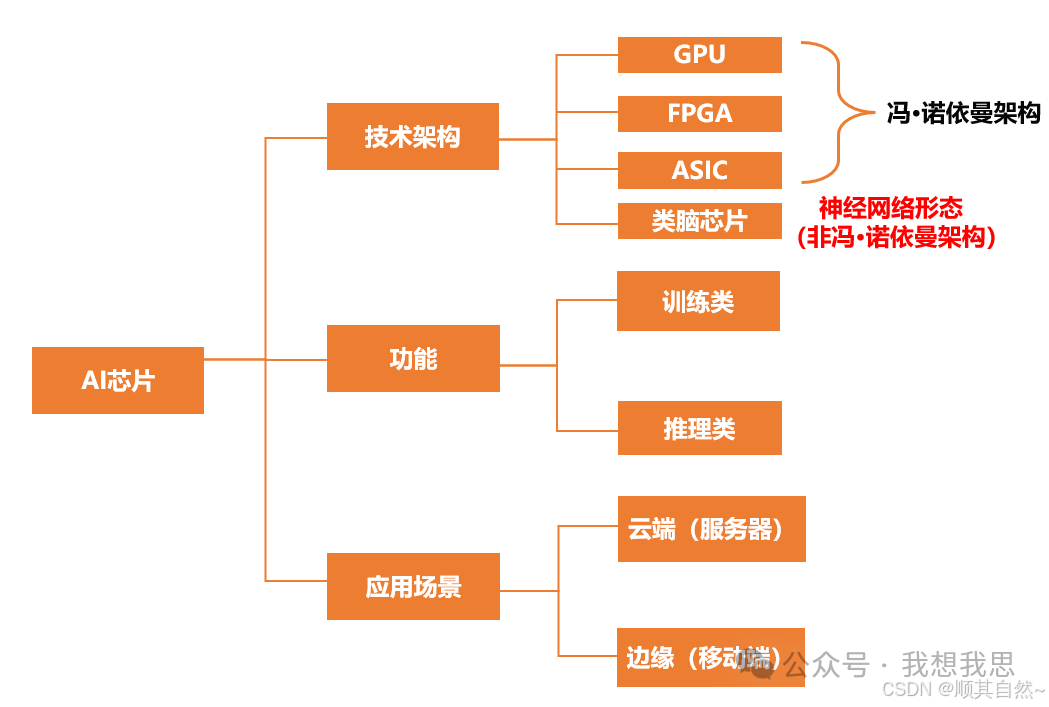
图8 AI芯片的分类
Tensor Core是增强AI计算的核心,能更好的处理矩阵乘运算
Tensor Core是用于加速深度学习计算的关键技术,其主要功能是执行深度神经网络中的矩阵乘法和卷积计算。
与传统CUDA Core相比,Tensor Core在每个时钟周期能执行多达4x4x4的GEMM运算,相当于同时进行64个浮点乘法累加(FMA)运算。
其计算原理是采用半精度(FP16)作为输入和输出(矩阵Ax矩阵B),并利用全精度(矩阵C)进行存储中间结果计算,以确保计算精度的同时最大限度地提高计算效率。
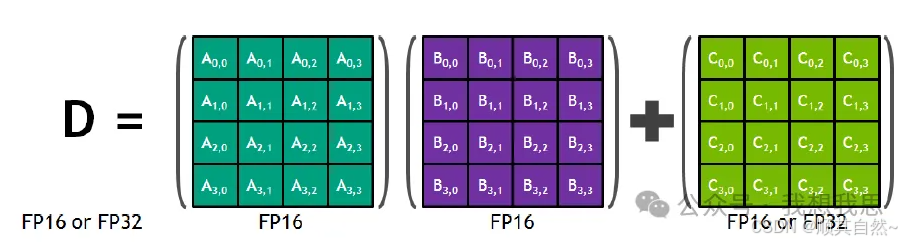
图9 Tensor Core计算原理
AI芯片的硬件重点性能指标

GPU在运算及并行任务处理能力上具有显著优势
图片处理器GPU又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像运算工作的微处理器,是显卡或GPU卡的“心脏”。
CPU和GPU在架构组成上都包括3个部分:运算单元(ALU)、控制单元(Control)、缓存单元(Cache)。从结构上看,在CPU中,缓存单元占50%,控制单元占25%,运算单元占25%;然而在GPU中,运算单元占90%比重,缓存、控制各占5%;由此可见,CPU运算能力更加均衡,GPU更适合做大量运算。
GPU通过将复杂的数学任务拆解成简单的小任务,并利用其多流处理器来并行处理,从而高效地执行图形渲染、数值分析和AI推理。
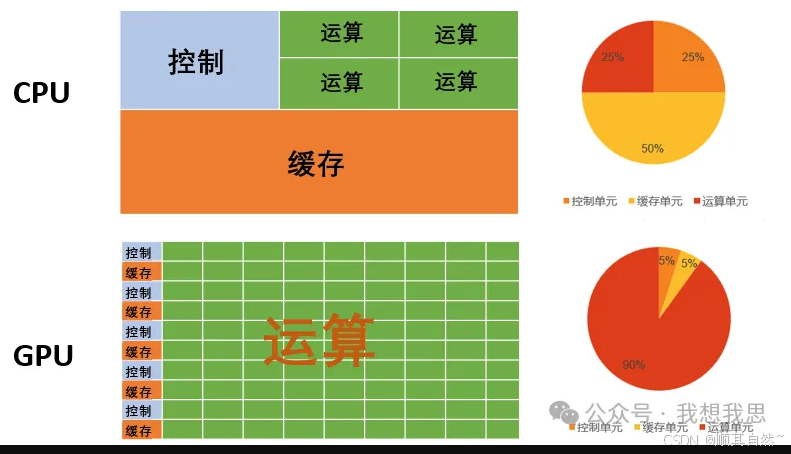
图10 CPU与GPU基本组成单元对比
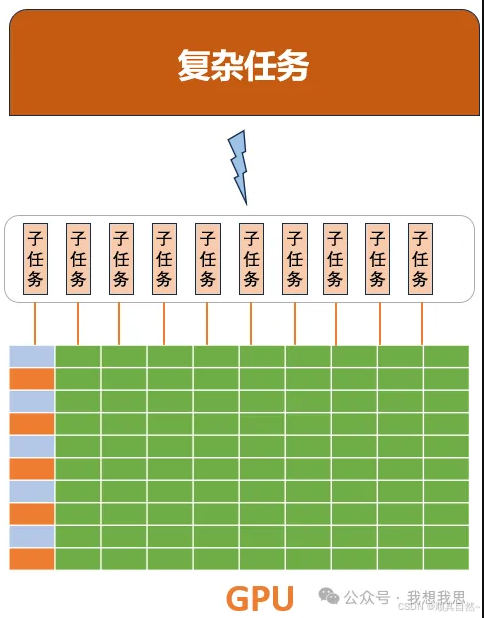
图11 GPU将极为复杂的任务进行拆解并行处理
GPU核心分类及CUDA Core结构特点
通常GPU核心可分为三种:CUDA Core、Tensor Core、RT Core。
每个CUDA核心含有一个ALU(整数单元)和一个浮点单元,并且提供了对于单精度和双精度浮点数的FMA指令。
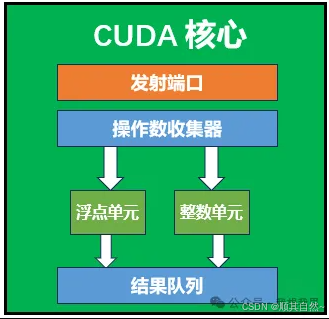
图12 Cuda核心结构

表2 通用GPU核心类型
如果将GPU处理器比作玩具工厂,CUDA核心就是其中的流水线。流水线越多,生产的玩具就越多,虽然“玩具工厂”的性能可能会越好,但也受限于每个流水线的生产效率、生产设备的架构、生产存储资源能力等。反应在GPU上,还需考虑显卡架构、时钟速度、内存带宽、内存速度、VRAM等因素。
GPU的架构及流式多处理器的结构组成
以Nvidia Volta架构的GV100为例,其主要组成部分可分为:
1)6个GPC(图像处理集群):每个包含7个纹理处理集群(TPCs),每个TPC包括两个SM,共14个SM;
2)84个Volta SM(流式多处理器):每个包含8个Tensor Core、 64个FP32核心、64个INT32核心、32个FP64核心、4个纹理单元;
3)8个512位内存控制器(总共4096位)。
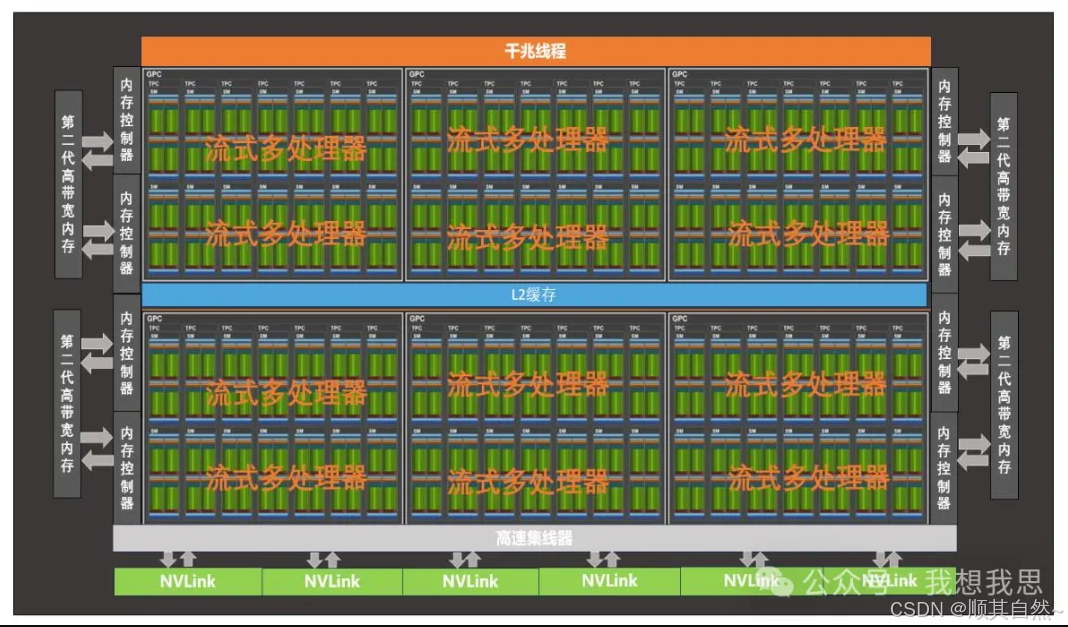
图13 GPU架构组成
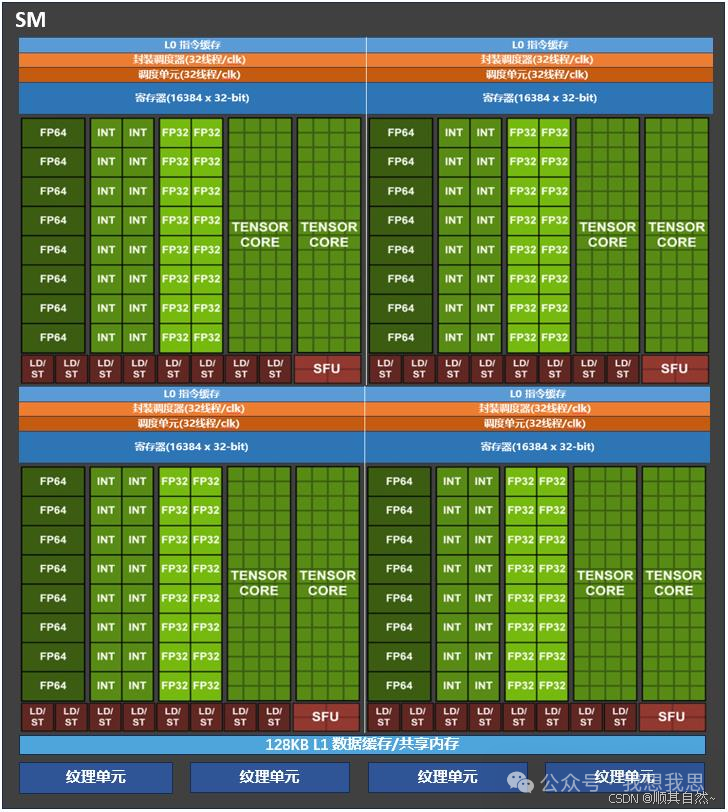
图14 GPU的流式多处理器结构
ASIC-AI芯片TPU架构基础
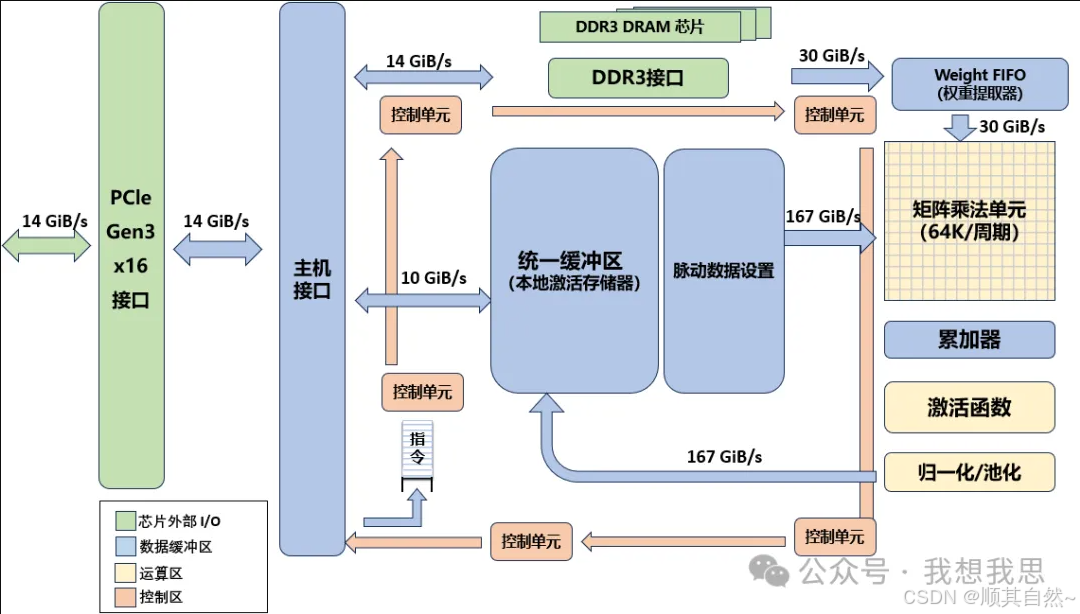
图15 TPU架构
TPU的运算资源包括
-
矩阵乘法单元(MXU):65536个8位乘法和加法单元,运行矩阵计算。
-
统一缓冲(UB):作为寄存器工作的24MB容量 SRAM。
-
激活单元(AU):硬件连接的激活函数。
TPU(张量处理单元)属于ASIC的一种,是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,为机器学习领域而定制。
TPUv1依赖于通过PCle(高速串行总线)接口与主机进行通信;它还可以直接访问自己的DDR3存储。
矩阵乘法单元:256 x 256大小的矩阵乘法单元,顶部输入256个权重值,左侧是256个input值。
DDR3 DRAM/Weight FIFO:权重存储通过DDR3-2133接口连接到TPUv1的DDR3 RAM芯片中,权重通过PCle从主机的内存预加载,然后传输到权重FIFO存储器中,供矩阵乘法单元使用。
统一缓存区/脉动数据设置:应用激活函数的结果存储在统一缓冲区存储器中,然后作为输入反馈矩阵乘法单元,以计算下一层所需的值。
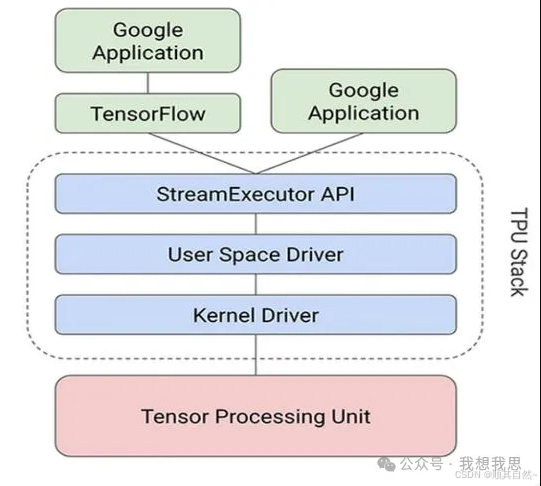
图16 从TensorFlow到TPU软件堆栈
TPU的设计封装了神经网络计算的本质,可以针对各种神经网络模型进行编程。此外,Google创建了编译器和软件栈,可以将来自TensorFlow的图像的API调用转换成TPU指令。
TPU布局及性能对比
与传统CPU、GPU架构不同,TPU的MXU设计采用了脉动阵列(systolic array)架构,数据流动呈现出周期性的脉冲模式,类似于心脏跳动的供血方式。
CPU与GPU在每次运算中需要从多个寄存器中进行存取;而TPU的脉动阵列将多个运算逻辑单元(ALU)串联在一起,复用从一个寄存器中读取的结果。
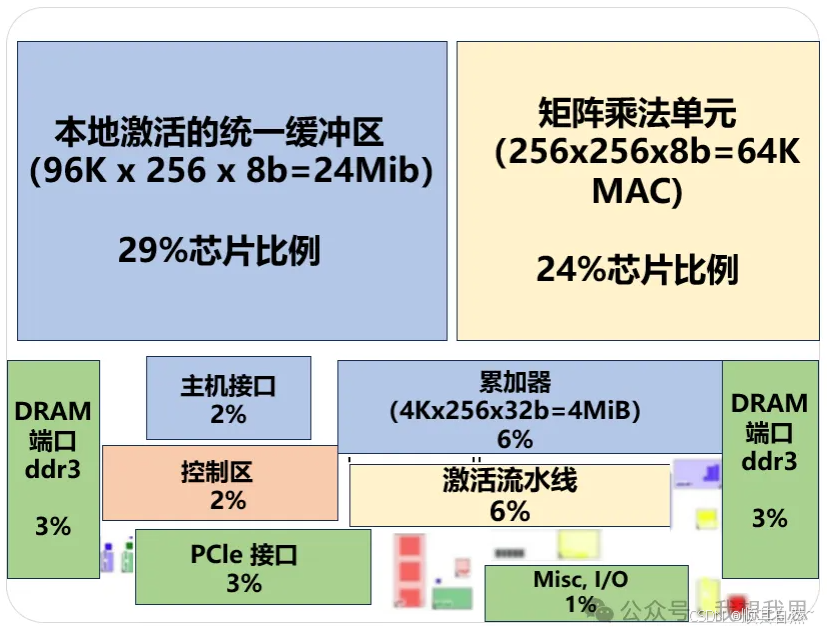
图17 TPU芯片布局
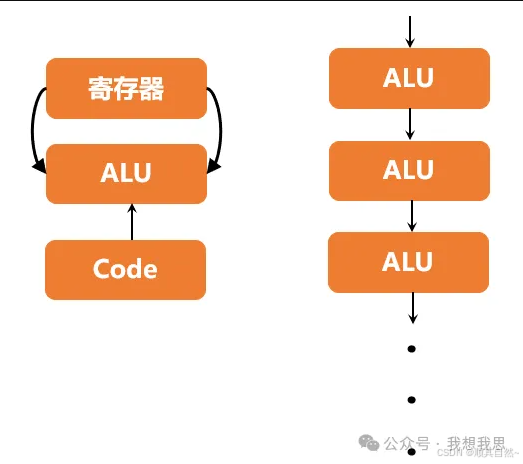
图18 TPU与CPU/GPU运算方式对比
转自:AI芯片算力基础知识

















 1794
1794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









