






接入大模型
Dify 是基于大语言模型的 AI 应用开发平台,初次使用时你需要先在 Dify 的 设置 -- 模型供应商 页面内添加并配置所需要的模型。
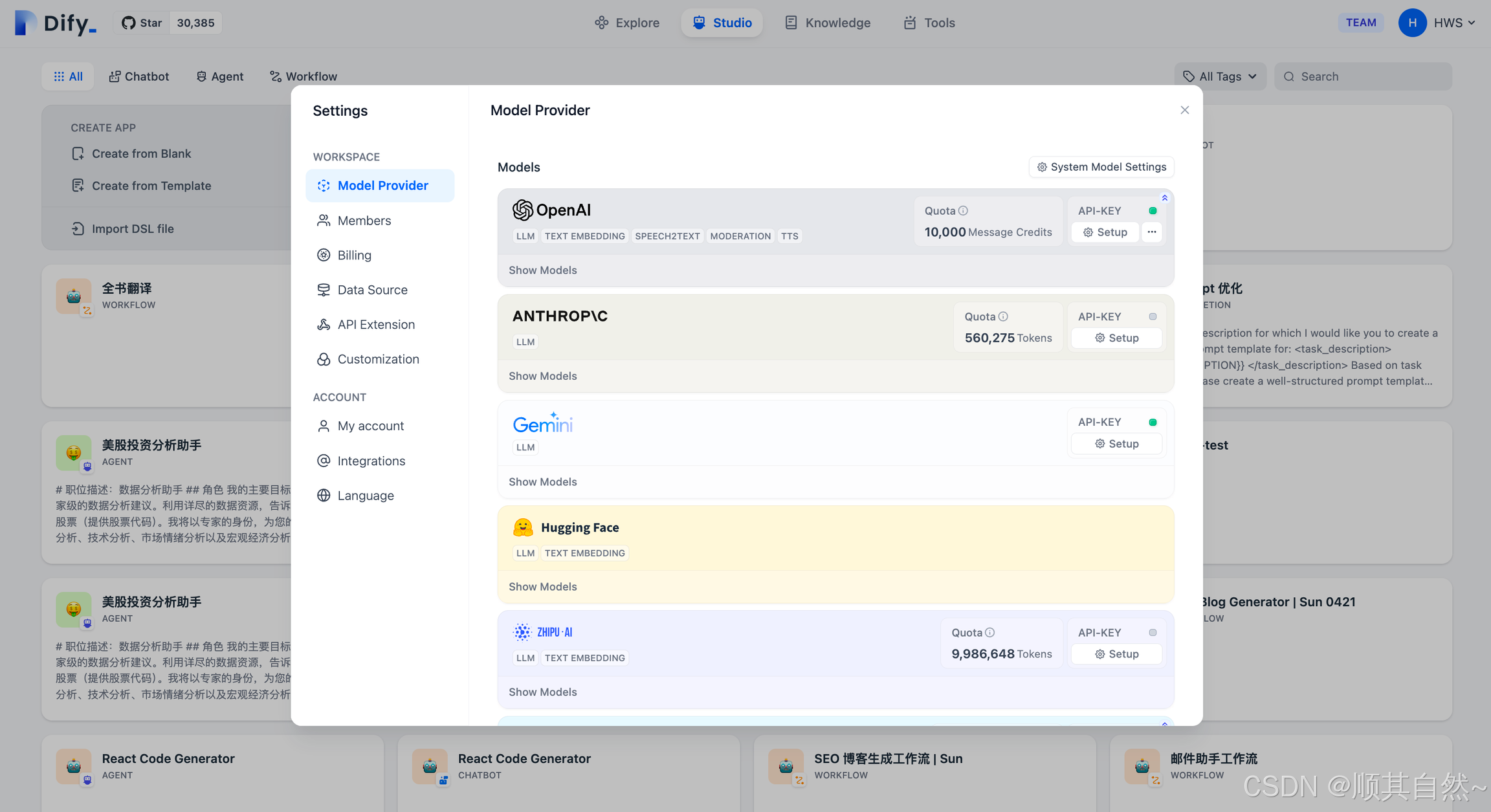
设置-模型供应商
Dify 目前已支持主流的模型供应商,例如 OpenAI 的 GPT 系列、Anthropic 的 Claude 系列等。不同模型的能力表现、参数类型会不一样,你可以根据不同情景的应用需求选择你喜欢的模型供应商。你在 Dify 应用以下模型能力前,应该前往不同的模型厂商官方网站获得他们的 API key 。
模型类型
在 Dify 中,我们按模型的使用场景将模型分为以下 4 类:
1、系统推理模型。 在创建的应用中,用的是该类型的模型。智聊、对话名称生成、下一步问题建议用的也是推理模型。
已支持的系统推理模型供应商:OpenAI、Azure OpenAI Service、Anthropic、Hugging Face Hub、Replicate、Xinference、OpenLLM、讯飞星火、文心一言、通义千问、Minimax、ZHIPU(ChatGLM)
2、Embedding 模型。在知识库中,将分段过的文档做 Embedding 用的是该类型的模型。在使用了知识库的应用中,将用户的提问做 Embedding 处理也是用的该类型的模型。
已支持的 Embedding 模型供应商:OpenAI、ZHIPU(ChatGLM)、Jina AI(Jina Embeddings)
3、Rerank 模型。Rerank 模型用于增强检索能力,改善 LLM 的搜索结果。
已支持的 Rerank 模型供应商:Cohere、Jina AI(Jina Reranker)
4、语音转文字模型。将对话型应用中,将语音转文字用的是该类型的模型。
已支持的语音转文字模型供应商:OpenAI
根据技术变化和用户需求,我们将陆续支持更多 LLM 供应商。
托管模型试用服务
我们为 Dify 云服务的用户提供了不同模型的试用额度,请在该额度耗尽前设置你自己的模型供应商,否则将会影响应用的正常使用。
OpenAI 托管模型试用: 我们提供 200 次调用次数供你试用体验,可用于 GPT3.5-turbo、GPT3.5-turbo-16k、text-davinci-003 模型。
设置默认模型
Dify 在需要模型时,会根据使用场景来选择设置过的默认模型。在 设置 > 模型供应商 中设置默认模型。
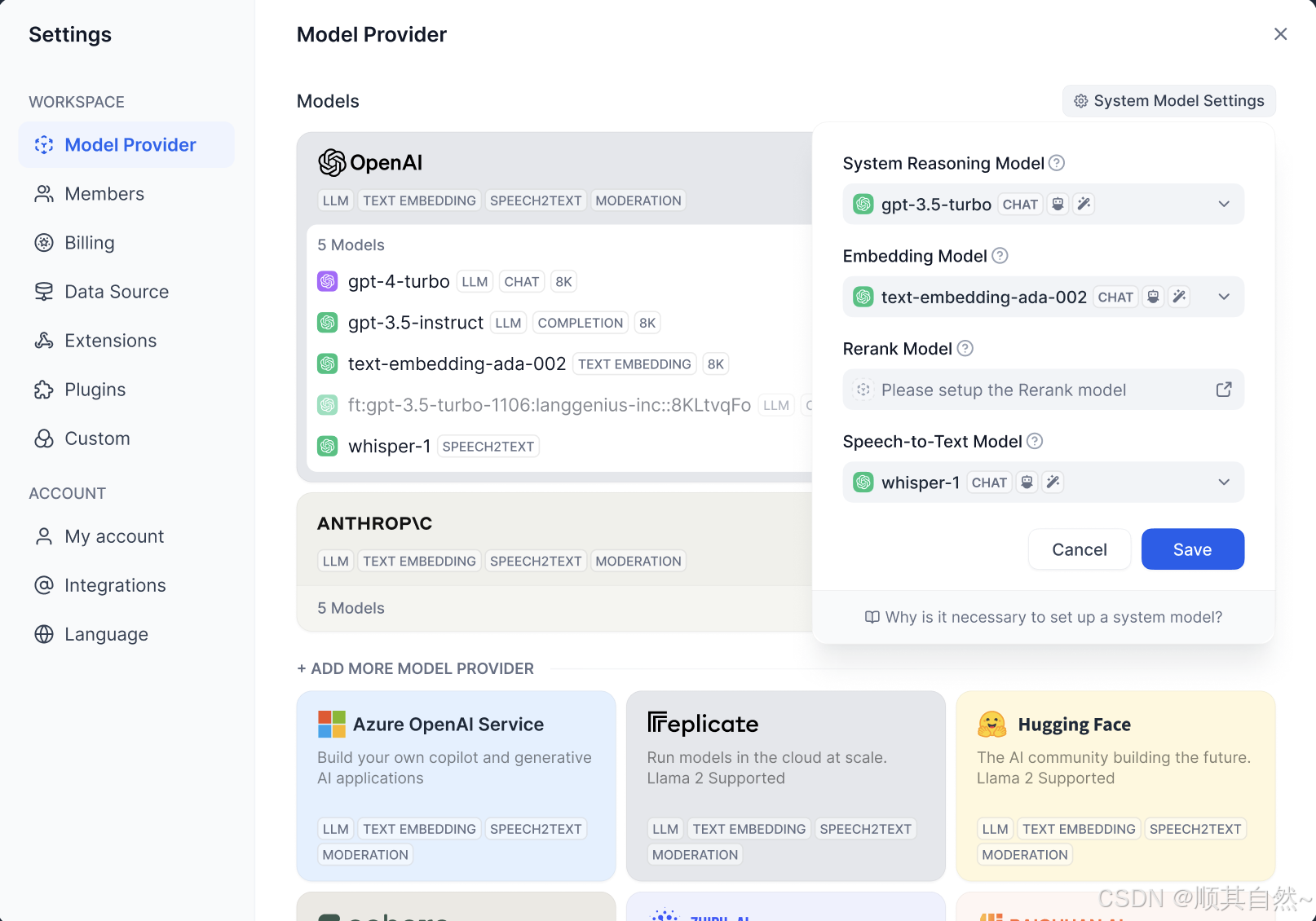
系统默认推理模型(System Reasoning Model):设置创建应用使用的默认推理模型,以及对话名称生成、下一步问题建议等功能也会使用该默认推理模型。
接入模型设置
在 Dify 的 设置 > 模型供应商 中设置要接入的模型。

模型供应商分为两种:
1)自有模型。该类型的模型供应商提供的是自己开发的模型。如 OpenAI,Anthropic 等。
2)托管模型。该类型的模型供应商提供的是第三方模型。如 Hugging Face,Replicate 等。
在 Dify 中接入不同类型的模型供应商的方式稍有不同。
接入自有模型的模型供应商
接入自有模型的供应商后,Dify 会自动接入该供应商下的所有模型。
在 Dify 中设置对应模型供应商的 API key,即可接入该模型供应商。
Dify 使用了 PKCS1_OAEP 来加密存储用户托管的 API 密钥,每个租户均使用了独立的密钥对进行加密,确保你的 API 密钥不被泄漏。
接入托管模型的模型供应商
托管类型的供应商上面有很多第三方模型。接入模型需要一个个的添加。具体接入方式如下:
使用模型
配置完模型后,就可以在应用中使用这些模型了:
增加新供应商
供应商配置方式
供应商支持三种模型配置方式:
预定义模型(predefined-model)
表示用户只需要配置统一的供应商凭据即可使用供应商下的预定义模型。
自定义模型(customizable-model)
用户需要新增每个模型的凭据配置,如 Xinference,它同时支持 LLM 和 Text Embedding,但是每个模型都有唯一的 model_uid,如果想要将两者同时接入,就需要为每个模型配置一个 model_uid。
从远程获取(fetch-from-remote)
与 predefined-model配置方式一致,只需要配置统一的供应商凭据即可,模型通过凭据信息从供应商获取。
如OpenAI,我们可以基于 gpt-turbo-3.5 来 Fine Tune 多个模型,而他们都位于同一个 api_key 下,当配置为fetch-from-remote时,开发者只需要配置统一的 api_key 即可让 Dify Runtime 获取到开发者所有的微调模型并接入 Dify。
这三种配置方式支持共存,即存在供应商支持predefined-model + customizable-model 或 predefined-model + fetch-from-remote等,也就是配置了供应商统一凭据可以使用预定义模型和从远程获取的模型,若新增了模型,则可以在此基础上额外使用自定义的模型。
配置说明
名词解释
module: 一个module即为一个 Python Package,或者通俗一点,称为一个文件夹,里面包含了一个__init__.py文件,以及其他的.py文件。
步骤
新增一个供应商主要分为几步,这里简单列出,帮助大家有一个大概的认识,具体的步骤会在下面详细介绍。
-
创建供应商 yaml 文件,根据 Provider Schema 编写。
-
创建供应商代码,实现一个
class。 -
根据模型类型,在供应商
module下创建对应的模型类型module,如llm或text_embedding。 -
根据模型类型,在对应的模型
module下创建同名的代码文件,如llm.py,并实现一个class。 -
如果有预定义模型,根据模型名称创建同名的yaml文件在模型
module下,如claude-2.1.yaml,根据 AI Model Entity 编写。 -
编写测试代码,确保功能可用。
开始吧
增加一个新的供应商需要先确定供应商的英文标识,如 anthropic,使用该标识在 model_providers 创建以此为名称的 module。
在此 module 下,我们需要先准备供应商的 YAML 配置。
准备供应商 YAML
此处以 Anthropic 为例,预设了供应商基础信息、支持的模型类型、配置方式、凭据规则。
provider: anthropic # 供应商标识
label: # 供应商展示名称,可设置 en_US 英文、zh_Hans 中文两种语言,zh_Hans 不设置将默认使用 en_US。
en_US: Anthropic
icon_small: # 供应商小图标,存储在对应供应商实现目录下的 _assets 目录,中英文策略同 label
en_US: icon_s_en.png
icon_large: # 供应商大图标,存储在对应供应商实现目录下的 _assets 目录,中英文策略同 label
en_US: icon_l_en.png
supported_model_types: # 支持的模型类型,Anthropic 仅支持 LLM
- llm
configurate_methods: # 支持的配置方式,Anthropic 仅支持预定义模型
- predefined-model
provider_credential_schema: # 供应商凭据规则,由于 Anthropic 仅支持预定义模型,则需要定义统一供应商凭据规则
credential_form_schemas: # 凭据表单项列表
- variable: anthropic_api_key # 凭据参数变量名
label: # 展示名称
en_US: API Key
type: secret-input # 表单类型,此处 secret-input 代表加密信息输入框,编辑时只展示屏蔽后的信息。
required: true # 是否必填
placeholder: # PlaceHolder 信息
zh_Hans: 在此输入你的 API Key
en_US: Enter your API Key
- variable: anthropic_api_url
label:
en_US: API URL
type: text-input # 表单类型,此处 text-input 代表文本输入框
required: false
placeholder:
zh_Hans: 在此输入你的 API URL
en_US: Enter your API URL如果接入的供应商提供自定义模型,比如OpenAI提供微调模型,那么我们就需要添加model_credential_schema,以OpenAI为例:
model_credential_schema:
model: # 微调模型名称
label:
en_US: Model Name
zh_Hans: 模型名称
placeholder:
en_US: Enter your model name
zh_Hans: 输入模型名称
credential_form_schemas:
- variable: openai_api_key
label:
en_US: API Key
type: secret-input
required: true
placeholder:
zh_Hans: 在此输入你的 API Key
en_US: Enter your API Key
- variable: openai_organization
label:
zh_Hans: 组织 ID
en_US: Organization
type: text-input
required: false
placeholder:
zh_Hans: 在此输入你的组织 ID
en_US: Enter your Organization ID
- variable: openai_api_base
label:
zh_Hans: API Base
en_US: API Base
type: text-input
required: false
placeholder:
zh_Hans: 在此输入你的 API Base
en_US: Enter your API Base也可以参考model_providers目录下其他供应商目录下的 YAML 配置信息。
实现供应商代码
我们需要在model_providers下创建一个同名的python文件,如anthropic.py,并实现一个class,继承__base.provider.Provider基类,如AnthropicProvider。
自定义模型供应商
当供应商为 Xinference 等自定义模型供应商时,可跳过该步骤,仅创建一个空的XinferenceProvider类即可,并实现一个空的validate_provider_credentials方法,该方法并不会被实际使用,仅用作避免抽象类无法实例化。
class XinferenceProvider(Provider):
def validate_provider_credentials(self, credentials: dict) -> None:
pass预定义模型供应商
供应商需要继承 __base.model_provider.ModelProvider 基类,实现 validate_provider_credentials 供应商统一凭据校验方法即可,可参考 AnthropicProvider。
def validate_provider_credentials(self, credentials: dict) -> None:
"""
Validate provider credentials
You can choose any validate_credentials method of model type or implement validate method by yourself,
such as: get model list api
if validate failed, raise exception
:param credentials: provider credentials, credentials form defined in `provider_credential_schema`.
"""当然也可以先预留 validate_provider_credentials 实现,在模型凭据校验方法实现后直接复用。
增加模型
增加预定义模型 👈🏻
对于预定义模型,我们可以通过简单定义一个 yaml,并通过实现调用代码来接入。
增加自定义模型 👈🏻
对于自定义模型,我们只需要实现调用代码即可接入,但是它需要处理的参数可能会更加复杂。
测试
为了保证接入供应商/模型的可用性,编写后的每个方法均需要在 tests 目录中编写对应的集成测试代码。
依旧以 Anthropic 为例。
在编写测试代码前,需要先在 .env.example 新增测试供应商所需要的凭据环境变量,如:ANTHROPIC_API_KEY。
在执行前需要将 .env.example 复制为 .env 再执行。
编写测试代码
在 tests 目录下创建供应商同名的 module: anthropic,继续在此模块中创建 test_provider.py 以及对应模型类型的 test py 文件,如下所示:
.
├── __init__.py
├── anthropic
│ ├── __init__.py
│ ├── test_llm.py # LLM 测试
│ └── test_provider.py # 供应商测试针对上面实现的代码的各种情况进行测试代码编写,并测试通过后提交代码。
预定义模型接入
供应商集成完成后,接下来为供应商下模型的接入。
我们首先需要确定接入模型的类型,并在对应供应商的目录下创建对应模型类型的 module。
当前支持模型类型如下:
-
llm文本生成模型 -
text_embedding文本 Embedding 模型 -
rerankRerank 模型 -
speech2text语音转文字 -
tts文字转语音 -
moderation审查
依旧以 Anthropic 为例,Anthropic 仅支持 LLM,因此在 model_providers.anthropic 创建一个 llm 为名称的 module。
对于预定义的模型,我们首先需要在 llm module 下创建以模型名为文件名称的 YAML 文件,如:claude-2.1.yaml。
准备模型 YAML
model: claude-2.1 # 模型标识
# 模型展示名称,可设置 en_US 英文、zh_Hans 中文两种语言,zh_Hans 不设置将默认使用 en_US。
# 也可不设置 label,则使用 model 标识内容。
label:
en_US: claude-2.1
model_type: llm # 模型类型,claude-2.1 为 LLM
features: # 支持功能,agent-thought 为支持 Agent 推理,vision 为支持图片理解
- agent-thought
model_properties: # 模型属性
mode: chat # LLM 模式,complete 文本补全模型,chat 对话模型
context_size: 200000 # 支持最大上下文大小
parameter_rules: # 模型调用参数规则,仅 LLM 需要提供
- name: temperature # 调用参数变量名
# 默认预置了 5 种变量内容配置模板,temperature/top_p/max_tokens/presence_penalty/frequency_penalty
# 可在 use_template 中直接设置模板变量名,将会使用 entities.defaults.PARAMETER_RULE_TEMPLATE 中的默认配置
# 若设置了额外的配置参数,将覆盖默认配置
use_template: temperature
- name: top_p
use_template: top_p
- name: top_k
label: # 调用参数展示名称
zh_Hans: 取样数量
en_US: Top k
type: int # 参数类型,支持 float/int/string/boolean
help: # 帮助信息,描述参数作用
zh_Hans: 仅从每个后续标记的前 K 个选项中采样。
en_US: Only sample from the top K options for each subsequent token.
required: false # 是否必填,可不设置
- name: max_tokens_to_sample
use_template: max_tokens
default: 4096 # 参数默认值
min: 1 # 参数最小值,仅 float/int 可用
max: 4096 # 参数最大值,仅 float/int 可用
pricing: # 价格信息
input: '8.00' # 输入单价,即 Prompt 单价
output: '24.00' # 输出单价,即返回内容单价
unit: '0.000001' # 价格单位,即上述价格为每 100K 的单价
currency: USD # 价格货币建议将所有模型配置都准备完毕后再开始模型代码的实现。
同样,也可以参考 model_providers 目录下其他供应商对应模型类型目录下的 YAML 配置信息,完整的 YAML 规则见:Schema。
实现模型调用代码
接下来需要在 llm module 下创建一个同名的 python 文件 llm.py 来编写代码实现。
在 llm.py 中创建一个 Anthropic LLM 类,我们取名为 AnthropicLargeLanguageModel(随意),继承 __base.large_language_model.LargeLanguageModel 基类,实现以下几个方法:
1)LLM 调用
实现 LLM 调用的核心方法,可同时支持流式和同步返回。
def _invoke(self, model: str, credentials: dict,
prompt_messages: list[PromptMessage], model_parameters: dict,
tools: Optional[list[PromptMessageTool]] = None, stop: Optional[List[str]] = None,
stream: bool = True, user: Optional[str] = None) \
-> Union[LLMResult, Generator]:
"""
Invoke large language model
:param model: model name
:param credentials: model credentials
:param prompt_messages: prompt messages
:param model_parameters: model parameters
:param tools: tools for tool calling
:param stop: stop words
:param stream: is stream response
:param user: unique user id
:return: full response or stream response chunk generator result
"""在实现时,需要注意使用两个函数来返回数据,分别用于处理同步返回和流式返回,因为Python会将函数中包含 yield 关键字的函数识别为生成器函数,返回的数据类型固定为 Generator,因此同步和流式返回需要分别实现,就像下面这样(注意下面例子使用了简化参数,实际实现时需要按照上面的参数列表进行实现):
def _invoke(self, stream: bool, **kwargs) \
-> Union[LLMResult, Generator]:
if stream:
return self._handle_stream_response(**kwargs)
return self._handle_sync_response(**kwargs)
def _handle_stream_response(self, **kwargs) -> Generator:
for chunk in response:
yield chunk
def _handle_sync_response(self, **kwargs) -> LLMResult:
return LLMResult(**response)2)预计算输入 tokens
若模型未提供预计算 tokens 接口,可直接返回 0。
def get_num_tokens(self, model: str, credentials: dict, prompt_messages: list[PromptMessage],
tools: Optional[list[PromptMessageTool]] = None) -> int:
"""
Get number of tokens for given prompt messages
:param model: model name
:param credentials: model credentials
:param prompt_messages: prompt messages
:param tools: tools for tool calling
:return:
"""3)模型凭据校验
与供应商凭据校验类似,这里针对单个模型进行校验。
def validate_credentials(self, model: str, credentials: dict) -> None:
"""
Validate model credentials
:param model: model name
:param credentials: model credentials
:return:
"""4)调用异常错误映射表
当模型调用异常时需要映射到 Runtime 指定的 InvokeError 类型,方便 Dify 针对不同错误做不同后续处理。
Runtime Errors:
@property
def _invoke_error_mapping(self) -> dict[type[InvokeError], list[type[Exception]]]:
"""
Map model invoke error to unified error
The key is the error type thrown to the caller
The value is the error type thrown by the model,
which needs to be converted into a unified error type for the caller.
:return: Invoke error mapping
"""-
InvokeConnectionError调用连接错误 -
InvokeServerUnavailableError调用服务方不可用 -
InvokeRateLimitError调用达到限额 -
InvokeAuthorizationError调用鉴权失败 -
InvokeBadRequestError调用传参有误
接口方法说明见:Interfaces,具体实现可参考:llm.py。
自定义模型接入
介绍
供应商集成完成后,接下来为供应商下模型的接入,为了帮助理解整个接入过程,我们以Xinference为例,逐步完成一个完整的供应商接入。
需要注意的是,对于自定义模型,每一个模型的接入都需要填写一个完整的供应商凭据。
而不同于预定义模型,自定义供应商接入时永远会拥有如下两个参数,不需要在供应商 yaml 中定义。
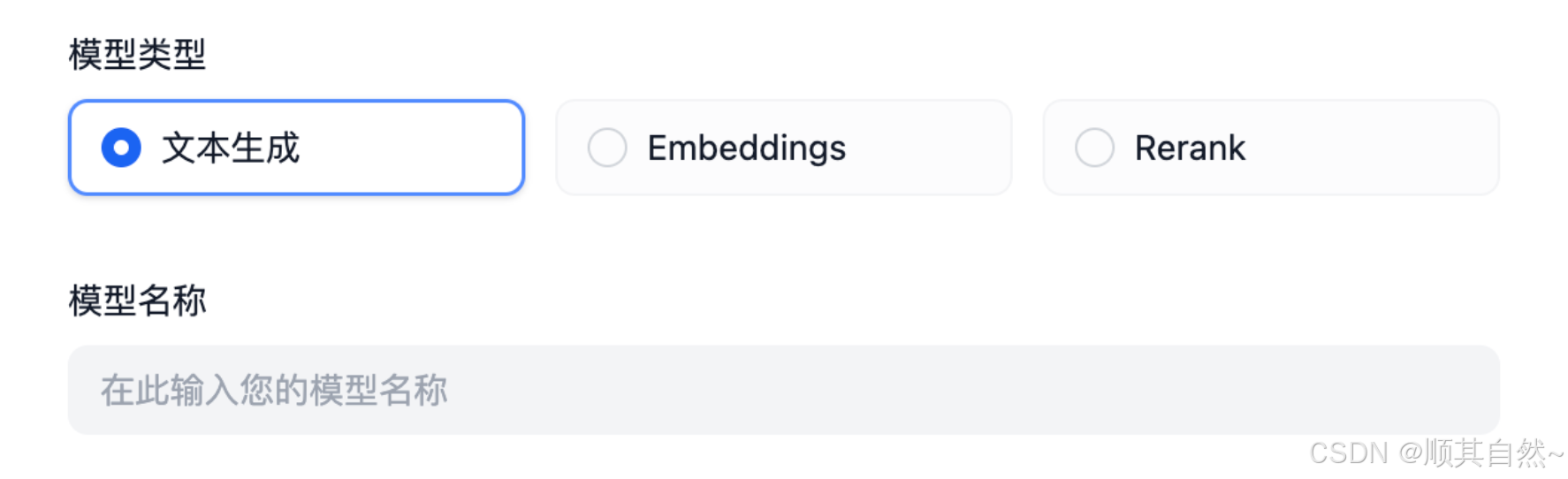
在前文中,我们已经知道了供应商无需实现validate_provider_credential,Runtime会自行根据用户在此选择的模型类型和模型名称调用对应的模型层的validate_credentials来进行验证。
编写供应商 yaml
我们首先要确定,接入的这个供应商支持哪些类型的模型。
当前支持模型类型如下:
-
llm文本生成模型 -
text_embedding文本 Embedding 模型 -
rerankRerank 模型 -
speech2text语音转文字 -
tts文字转语音 -
moderation审查
Xinference支持LLM、Text Embedding和Rerank,那么我们开始编写xinference.yaml。
provider: xinference #确定供应商标识
label: # 供应商展示名称,可设置 en_US 英文、zh_Hans 中文两种语言,zh_Hans 不设置将默认使用 en_US。
en_US: Xorbits Inference
icon_small: # 小图标,可以参考其他供应商的图标,存储在对应供应商实现目录下的 _assets 目录,中英文策略同 label
en_US: icon_s_en.svg
icon_large: # 大图标
en_US: icon_l_en.svg
help: # 帮助
title:
en_US: How to deploy Xinference
zh_Hans: 如何部署 Xinference
url:
en_US: https://github.com/xorbitsai/inference
supported_model_types: # 支持的模型类型,Xinference同时支持LLM/Text Embedding/Rerank
- llm
- text-embedding
- rerank
configurate_methods: # 因为Xinference为本地部署的供应商,并且没有预定义模型,需要用什么模型需要根据Xinference的文档自己部署,所以这里只支持自定义模型
- customizable-model
provider_credential_schema:
credential_form_schemas:随后,我们需要思考在 Xinference 中定义一个模型需要哪些凭据
-
它支持三种不同的模型,因此,我们需要有
model_type来指定这个模型的类型,它有三种类型,所以我们这么编写
provider_credential_schema:
credential_form_schemas:
- variable: model_type
type: select
label:
en_US: Model type
zh_Hans: 模型类型
required: true
options:
- value: text-generation
label:
en_US: Language Model
zh_Hans: 语言模型
- value: embeddings
label:
en_US: Text Embedding
- value: reranking
label:
en_US: Rerank-
每一个模型都有自己的名称
model_name,因此需要在这里定义
- variable: model_name
type: text-input
label:
en_US: Model name
zh_Hans: 模型名称
required: true
placeholder:
zh_Hans: 填写模型名称
en_US: Input model name-
填写 Xinference 本地部署的地址
- variable: server_url
label:
zh_Hans: 服务器URL
en_US: Server url
type: text-input
required: true
placeholder:
zh_Hans: 在此输入Xinference的服务器地址,如 https://example.com/xxx
en_US: Enter the url of your Xinference, for example https://example.com/xxx-
每个模型都有唯一的 model_uid,因此需要在这里定义
- variable: model_uid
label:
zh_Hans: 模型 UID
en_US: Model uid
type: text-input
required: true
placeholder:
zh_Hans: 在此输入你的 Model UID
en_US: Enter the model uid现在,我们就完成了供应商的基础定义。
编写模型代码
然后我们以llm类型为例,编写xinference.llm.llm.py
在 llm.py 中创建一个 Xinference LLM 类,我们取名为 XinferenceAILargeLanguageModel(随意),继承 __base.large_language_model.LargeLanguageModel 基类,实现以下几个方法:
1)LLM 调用
实现 LLM 调用的核心方法,可同时支持流式和同步返回。
def _invoke(self, model: str, credentials: dict,
prompt_messages: list[PromptMessage], model_parameters: dict,
tools: Optional[list[PromptMessageTool]] = None, stop: Optional[list[str]] = None,
stream: bool = True, user: Optional[str] = None) \
-> Union[LLMResult, Generator]:
"""
Invoke large language model
:param model: model name
:param credentials: model credentials
:param prompt_messages: prompt messages
:param model_parameters: model parameters
:param tools: tools for tool calling
:param stop: stop words
:param stream: is stream response
:param user: unique user id
:return: full response or stream response chunk generator result
"""在实现时,需要注意使用两个函数来返回数据,分别用于处理同步返回和流式返回,因为Python会将函数中包含 yield 关键字的函数识别为生成器函数,返回的数据类型固定为 Generator,因此同步和流式返回需要分别实现,就像下面这样(注意下面例子使用了简化参数,实际实现时需要按照上面的参数列表进行实现):
def _invoke(self, stream: bool, **kwargs) \
-> Union[LLMResult, Generator]:
if stream:
return self._handle_stream_response(**kwargs)
return self._handle_sync_response(**kwargs)
def _handle_stream_response(self, **kwargs) -> Generator:
for chunk in response:
yield chunk
def _handle_sync_response(self, **kwargs) -> LLMResult:
return LLMResult(**response)2)预计算输入 tokens
若模型未提供预计算 tokens 接口,可直接返回 0。
def get_num_tokens(self, model: str, credentials: dict, prompt_messages: list[PromptMessage],
tools: Optional[list[PromptMessageTool]] = None) -> int:
"""
Get number of tokens for given prompt messages
:param model: model name
:param credentials: model credentials
:param prompt_messages: prompt messages
:param tools: tools for tool calling
:return:
"""有时候,也许你不需要直接返回0,所以你可以使用self._get_num_tokens_by_gpt2(text: str)来获取预计算的tokens,这个方法位于AIModel基类中,它会使用GPT2的Tokenizer进行计算,但是只能作为替代方法,并不完全准确。
3)模型凭据校验
与供应商凭据校验类似,这里针对单个模型进行校验。
def validate_credentials(self, model: str, credentials: dict) -> None:
"""
Validate model credentials
:param model: model name
:param credentials: model credentials
:return:
"""4)模型参数 Schema
与自定义类型不同,由于没有在 yaml 文件中定义一个模型支持哪些参数,因此,我们需要动态实现模型参数的Schema。
如Xinference支持max_tokens temperature top_p 这三个模型参数。
但是有的供应商根据不同的模型支持不同的参数,如供应商OpenLLM支持top_k,但是并不是这个供应商提供的所有模型都支持top_k,我们这里举例 A 模型支持top_k,B模型不支持top_k,那么我们需要在这里动态生成模型参数的 Schema,如下所示:
def get_customizable_model_schema(self, model: str, credentials: dict) -> AIModelEntity | None:
"""
used to define customizable model schema
"""
rules = [
ParameterRule(
name='temperature', type=ParameterType.FLOAT,
use_template='temperature',
label=I18nObject(
zh_Hans='温度', en_US='Temperature'
)
),
ParameterRule(
name='top_p', type=ParameterType.FLOAT,
use_template='top_p',
label=I18nObject(
zh_Hans='Top P', en_US='Top P'
)
),
ParameterRule(
name='max_tokens', type=ParameterType.INT,
use_template='max_tokens',
min=1,
default=512,
label=I18nObject(
zh_Hans='最大生成长度', en_US='Max Tokens'
)
)
]
# if model is A, add top_k to rules
if model == 'A':
rules.append(
ParameterRule(
name='top_k', type=ParameterType.INT,
use_template='top_k',
min=1,
default=50,
label=I18nObject(
zh_Hans='Top K', en_US='Top K'
)
)
)
"""
some NOT IMPORTANT code here
"""
entity = AIModelEntity(
model=model,
label=I18nObject(
en_US=model
),
fetch_from=FetchFrom.CUSTOMIZABLE_MODEL,
model_type=model_type,
model_properties={
ModelPropertyKey.MODE: ModelType.LLM,
},
parameter_rules=rules
)
return entity5)调用异常错误映射表
当模型调用异常时需要映射到 Runtime 指定的 InvokeError 类型,方便 Dify 针对不同错误做不同后续处理。
Runtime Errors:
@property
def _invoke_error_mapping(self) -> dict[type[InvokeError], list[type[Exception]]]:
"""
Map model invoke error to unified error
The key is the error type thrown to the caller
The value is the error type thrown by the model,
which needs to be converted into a unified error type for the caller.
:return: Invoke error mapping
"""-
InvokeConnectionError调用连接错误 -
InvokeServerUnavailableError调用服务方不可用 -
InvokeRateLimitError调用达到限额 -
InvokeAuthorizationError调用鉴权失败 -
InvokeBadRequestError调用传参有误
接口方法说明见:Interfaces,具体实现可参考:llm.py。
负载均衡
模型速率限制(Rate limits)是模型厂商对用户或客户在指定时间内访问 API 服务次数所添加的限制。它有助于防止 API 的滥用或误用,有助于确保每个用户都能公平地访问 API,控制基础设施的总体负载。
在企业级大规模调用模型 API 时,高并发请求会导致超过请求速率限制并影响用户访问。负载均衡可以通过在多个 API 端点之间分配 API 请求,确保所有用户都能获得最快的响应和最高的模型调用吞吐量,保障业务稳定运行。
你可以在 模型供应商 -- 模型列表 -- 设置模型负载均衡 打开该功能,并在同一个模型上添加多个凭据 (API key)。
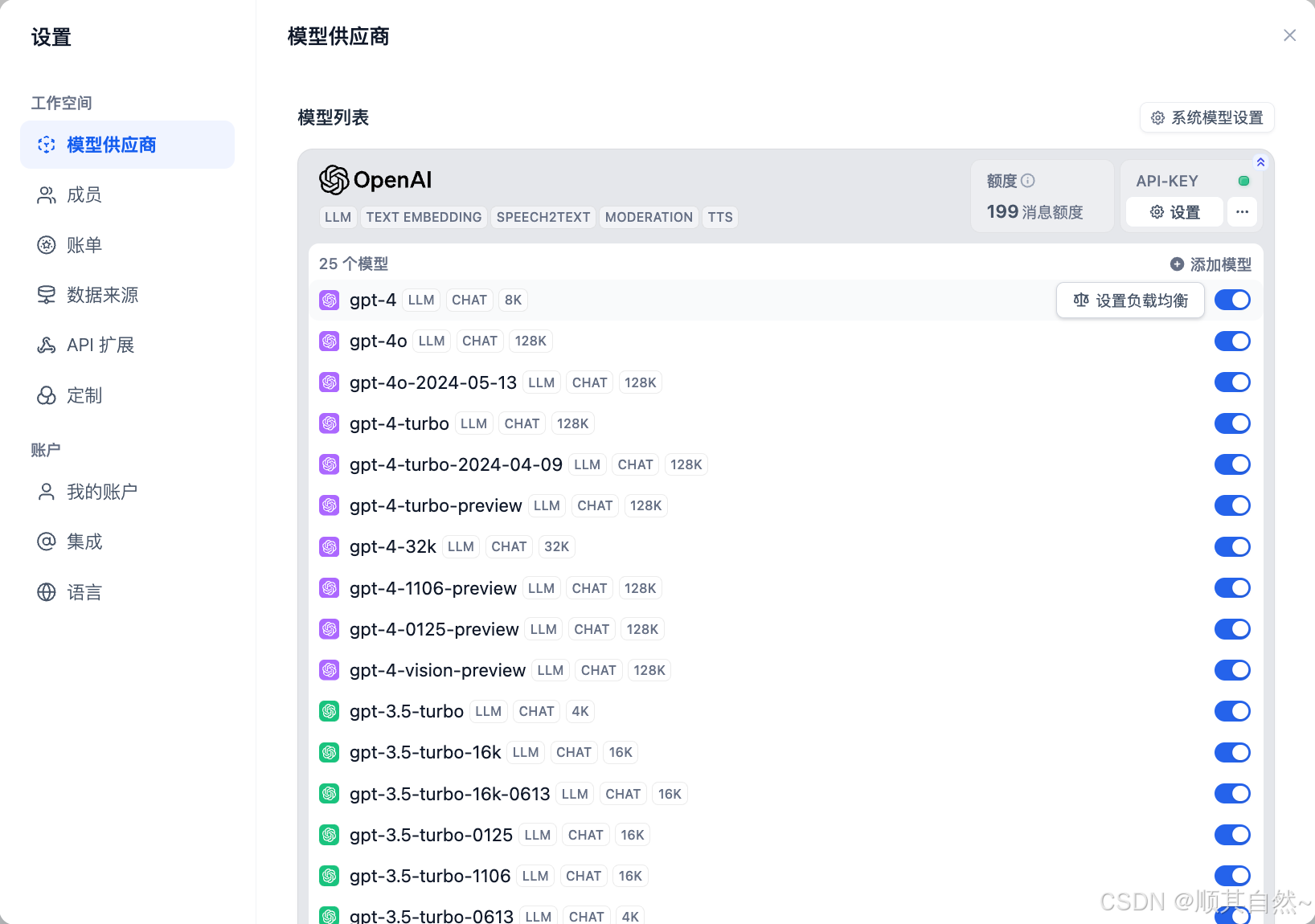
模型负载均衡
模型负载均衡为付费特性,你可以通过订阅 SaaS 付费服务或者购买企业版来开启该功能。
默认配置中的 API Key 为初次配置模型供应商时添加的凭据,你需要点击 增加配置 添加同一模型的不同 API Key 来正常使用负载均衡功能。
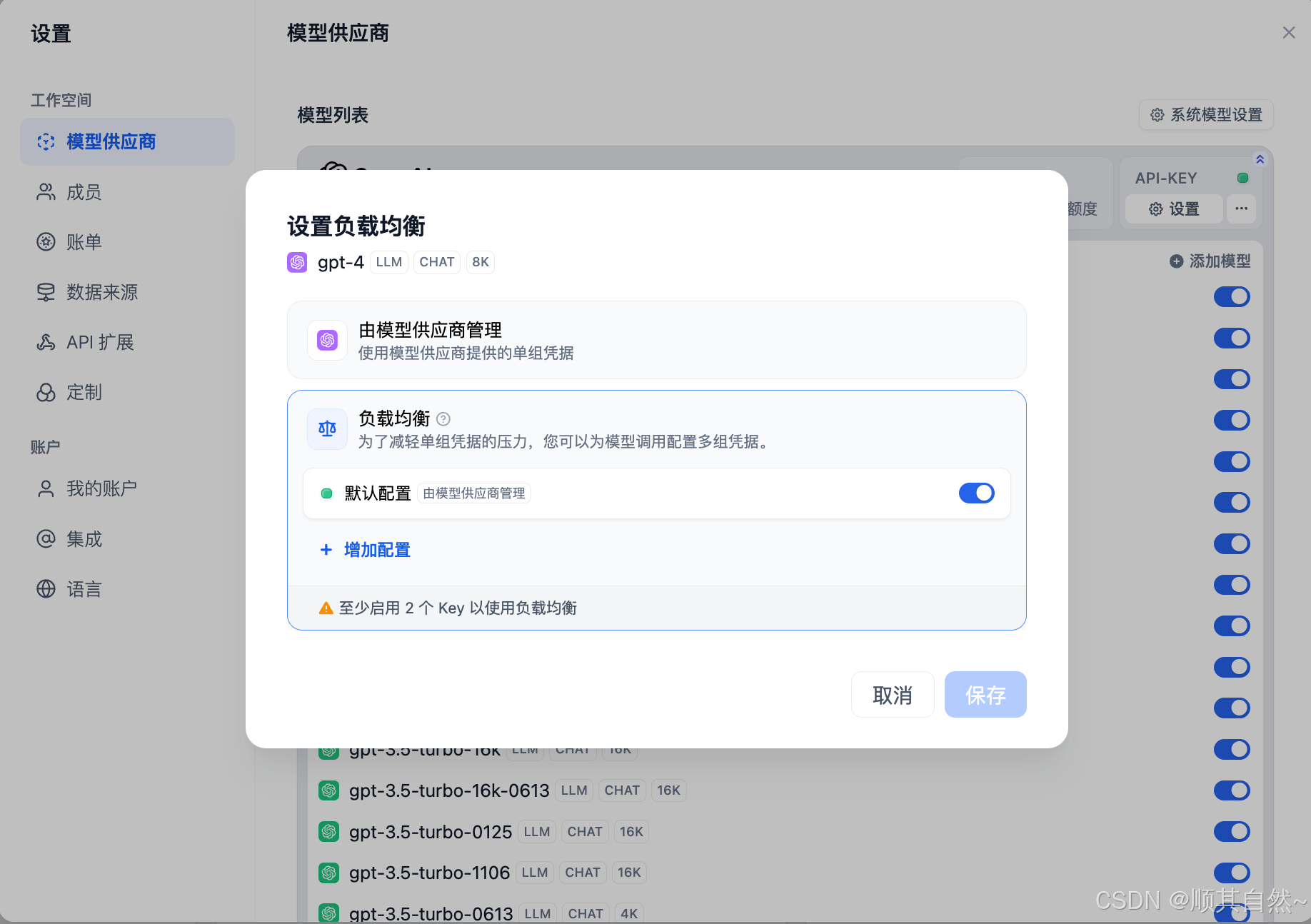
配置负载均衡
需要额外添加至少 1 个模型凭据即可保存并开启负载均衡。
你也可以将已配置的凭据临时停用或者删除。
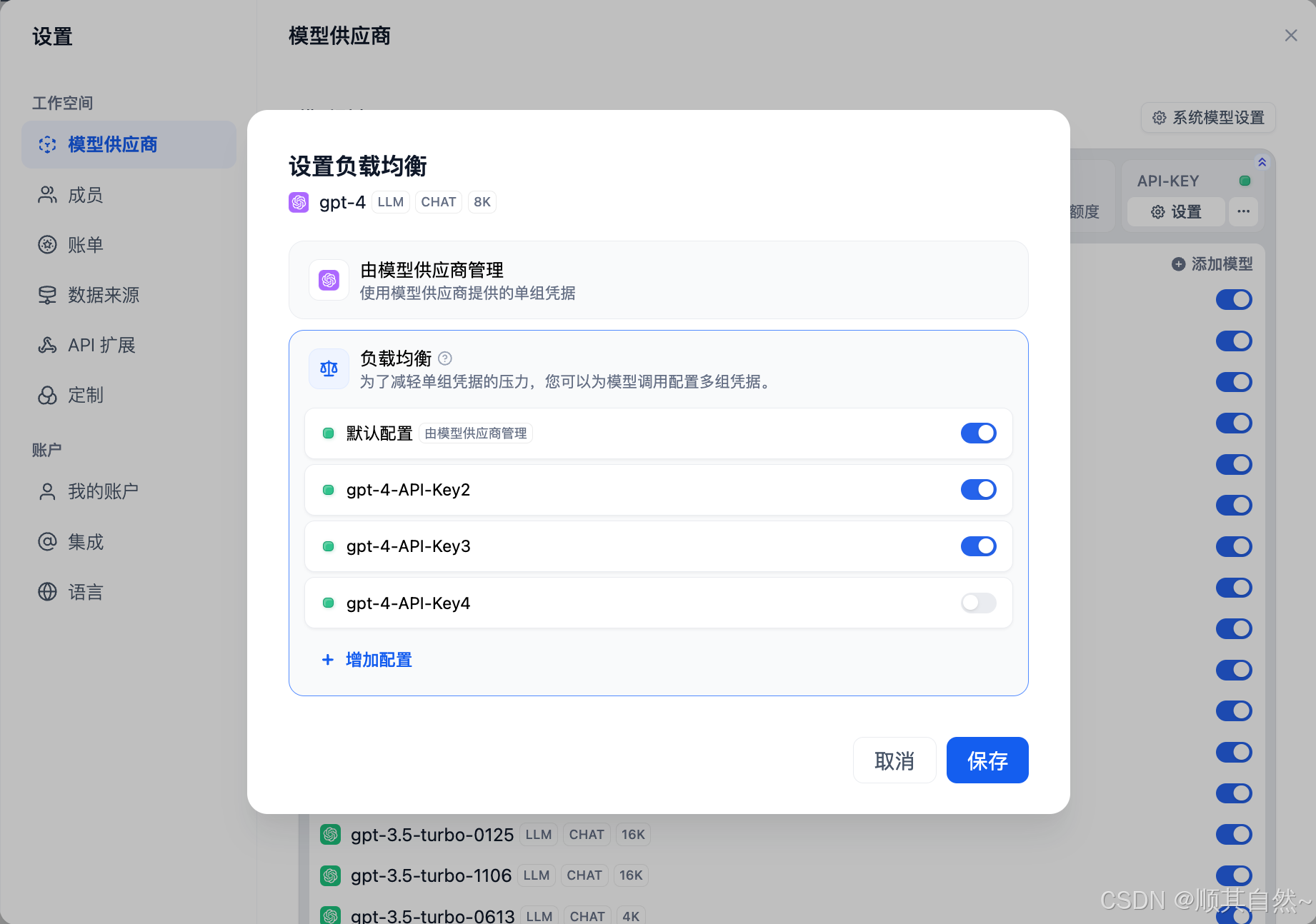
配置完成后再模型列表内会显示所有已开启负载均衡的模型。
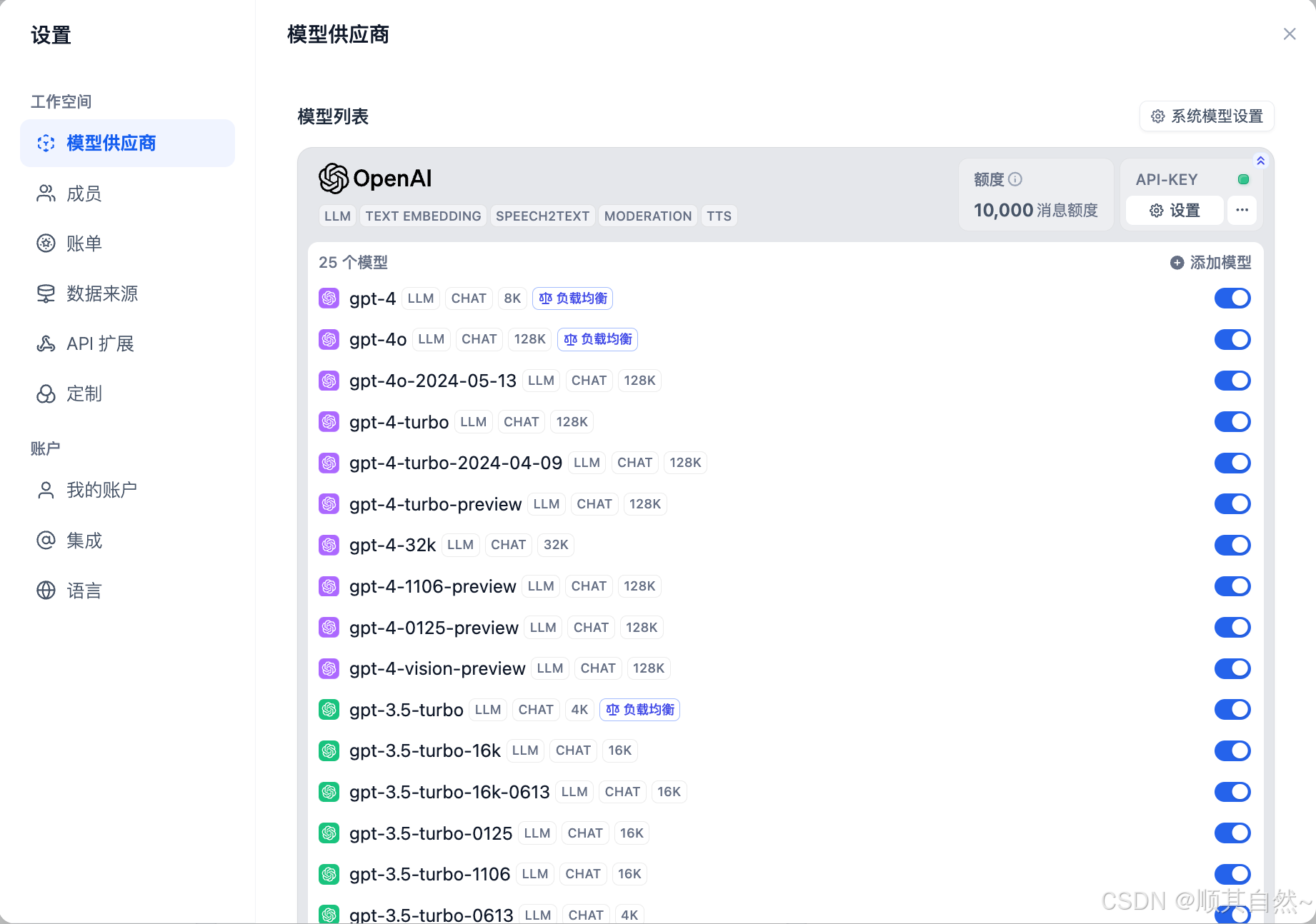
开启负载均衡
默认情况下,负载均衡使用 Round-robin 策略。如果触发速率限制,将应用 1 分钟的冷却时间。
你也可以从 添加模型 配置负载均衡,配置流程与上面一致。
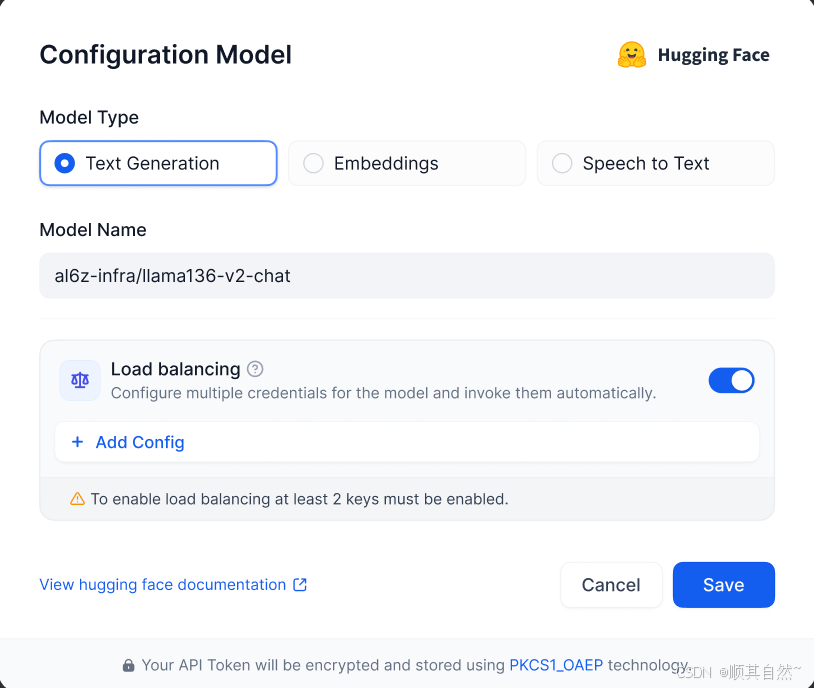
从添加模型配置负载均衡
转自:负载均衡 | Dify

















 2324
2324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









