







from_pretrained
├── from_pretrained (类方法)
├── 解析输入参数
│ ├── 处理已弃用的参数(如 use_auth_token)
│ ├── 处理 `torch_dtype` 参数(可能调用 `cls._set_default_torch_dtype(torch_dtype)`)
│ ├── 处理量化配置(如果提供了 `quantization_config`,调用 `AutoHfQuantizer.from_config`)
├── 加载配置(调用 `cls.config_class.from_pretrained`)
├── 解析存档文件
│ ├── 确定模型是本地还是远程的
│ ├── 确定存档文件路径
│ ├── 如果是本地模型,检查本地文件路径
│ ├── 如果是远程模型,调用 `cached_file` 下载并缓存模型文件
├── 加载状态字典(如果从 PyTorch 权重加载)
│ ├── 调用 load_state_dict() 从文件中加载状态字典到内存
│ ├── 调用 cls._load_pretrained_model() 将状态字典应用到模型
│ ├── 如果 low_cpu_mem_usage 为 True,使用低内存占用方式加载
│ ├── 否则,调用 _load_state_dict_into_model()
│ ├── 调用 model.load_state_dict() 将参数加载到模型中
│ ├── 处理 missing_keys、unexpected_keys、error_msgs 等
├── 设置默认的 Torch 数据类型(可能再次调用 `cls._set_default_torch_dtype(torch_dtype)`)
├── 实例化模型(调用 `cls(config, *model_args, **model_kwargs)`)
│ ├── 使用上下文管理器控制权重初始化
│ ├── 使用 `no_init_weights` 防止权重初始化
│ ├── 如果 `low_cpu_mem_usage=True`,使用 `init_empty_weights`
├── 加载预训练权重(调用 `cls._load_pretrained_model`)
│ ├── 如果模型是分片的,调用 `load_sharded_checkpoint`
│ ├── 将权重加载到模型中
│ ├── 调用 `_load_state_dict_into_model` 或 `_load_state_dict_into_meta_model`
│ ├── 处理加载过程中的缺失键、意外键、尺寸不匹配等信息
├── 权重共享(调用 `model.tie_weights`)
├── 设置模型为评估模式(调用 `model.eval()`)
├── 加载生成配置(如果模型支持生成,调用 `GenerationConfig.from_pretrained`)
├── 分配模型到设备(如果提供了 `device_map`,调用 `dispatch_model`)
│ ├── 使用 `device_map`、`offload_folder`、`offload_state_dict` 等参数
└── 返回加载后的模型
简明流程
在使用 Hugging Face Transformers 库加载预训练模型时,核心方法是 from_pretrained。该方法负责从预训练模型的检查点加载模型配置和权重。
说明:
- 调整了 步骤 B,更新为 解析配置文件路径并提取提交哈希,更准确地反映了代码的实际作用。
- 节点 A 到 R 表示从调用
from_pretrained方法到完成模型加载的各个步骤。 - 箭头表示步骤之间的顺序和依赖关系。
1. 解析模型配置文件路径并提取提交哈希
代码:
resolved_config_file = cached_file(
pretrained_model_name_or_path,
CONFIG_NAME, # 一般为 'config.json'
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
_raise_exceptions_for_gated_repo=False,
_raise_exceptions_for_missing_entries=False,
_raise_exceptions_for_connection_errors=False,
)
commit_hash = extract_commit_hash(resolved_config_file, commit_hash)
结果:
resolved_config_file = '/data/model/models--Qwen--Qwen2.5-VL-3B-Instruct/snapshots/...(截取部分路径).../config.json'
commit_hash = '1b989f2c63999d7344135894d3cfa8f494116743' # 假设提取的提交哈希值
说明:
-
cached_file函数:- 用于解析模型配置文件的路径,确定要加载的配置文件的位置。
- 如果本地缓存中已有该文件,则直接使用缓存的文件路径
resolved_config_file。 - 如果本地没有缓存,则从远程仓库下载配置文件并缓存下来。
-
extract_commit_hash函数:- 从
resolved_config_file中提取提交哈希值(commit hash),用于版本控制和日志记录。 - 这在加载特定的模型版本或调试时非常有用。
- 从
-
这里并不是直接加载配置对象,而是获取配置文件的路径和相关的元数据信息,例如提交哈希值。
2. 检查并加载适配器配置(Adapter Config)
代码:
_adapter_model_path = find_adapter_config_file(
pretrained_model_name_or_path,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
_commit_hash=commit_hash,
**adapter_kwargs,
)
结果:
_adapter_model_path = None
说明:
- 检查是否存在适配器配置文件,用于参数高效微调(PEFT)等。
- 在本例中,未找到适配器配置。
3. 实例化配置对象
代码:
config, model_kwargs = cls.config_class.from_pretrained(
config_path,
cache_dir=cache_dir,
return_unused_kwargs=True,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
_from_auto=from_auto_class,
_from_pipeline=from_pipeline,
**kwargs,
)
结果:
config = Qwen2_5_VLConfig
说明:
- 使用配置类的
from_pretrained方法加载配置对象。 - 此时真正读取配置文件的内容,解析成配置对象
config。
4. 检查模型权重是否分片
代码:
is_sharded = False
sharded_metadata = None
说明:
- 初始化变量,默认为非分片模型。
- 后续将根据模型权重文件是否分片来更新这些变量。
5. 准备加载模型权重
代码:
cached_file_kwargs = {
"cache_dir": cache_dir,
"force_download": force_download,
"proxies": proxies,
"resume_download": resume_download,
"local_files_only": local_files_only,
"token": token,
"user_agent": user_agent,
"revision": revision,
"subfolder": subfolder,
"_raise_exceptions_for_gated_repo": False,
"_raise_exceptions_for_missing_entries": False,
"_commit_hash": commit_hash,
}
resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs)
说明:
- 准备参数
cached_file_kwargs,用于调用cached_file函数。 - 使用
cached_file获取模型权重文件的本地路径。
6. 处理分片权重文件
代码:
resolved_archive_file = cached_file(
pretrained_model_name_or_path,
_add_variant(SAFE_WEIGHTS_INDEX_NAME, variant),
**cached_file_kwargs,
)
结果:
resolved_archive_file = '/data/model/.../model.safetensors.index.json'
处理分片文件:
if is_sharded:
resolved_archive_file, sharded_metadata = get_checkpoint_shard_files(
pretrained_model_name_or_path,
resolved_archive_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
token=token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_commit_hash=commit_hash,
)
结果:
- 加载分片的权重文件:
resolved_archive_file = [ '/data/model/.../model-00001-of-00002.safetensors', '/data/model/.../model-00002-of-00002.safetensors' ] len(resolved_archive_file) = 2
说明:
- 检测到模型的权重是分片存储的,使用
get_checkpoint_shard_files获取所有分片文件的路径。 - 更新
is_sharded为True,并得到sharded_metadata。
7. 设置默认数据类型(dtype)
代码:
dtype_orig = cls._set_default_torch_dtype(torch_dtype)
说明:
- 根据
torch_dtype参数设置 PyTorch 的默认数据类型,并保存原始的 dtype,以便后续恢复。 - 这一步是确保模型和权重在加载时使用合适的数据类型。
8. 加载状态字典键(State Dict Keys)
代码:
loaded_state_dict_keys = sharded_metadata["all_checkpoint_keys"]
说明:
- 从分片元数据中获取所有的状态字典键,用于后续加载权重时的验证和匹配。
9. 准备模型初始化上下文
代码:
init_contexts = [no_init_weights(_enable=_fast_init)]
init_contexts.append(init_empty_weights())
config = copy.deepcopy(config) # 防止在 from_pretrained 中修改原始配置
config = cls._autoset_attn_implementation(
config, use_flash_attention_2=use_flash_attention_2, torch_dtype=torch_dtype, device_map=device_map
)
说明:
- 使用
no_init_weights和init_empty_weights上下文,避免在模型实例化时分配实际的权重内存,实现延迟加载。 - 复制配置对象,防止原始配置被修改。
- 自动设置注意力机制的实现方式,根据配置和环境进行调整。
10. 在上下文管理器中实例化模型
代码:
with ContextManagers(init_contexts):
# 确保不运行缓冲模块的初始化函数
model = cls(config, *model_args, **model_kwargs)
说明:
- 在上下文管理器中实例化模型,此时模型的权重未被实际初始化,节省内存。
cls是模型的类,例如Qwen2_5_VLModel。
11. 计算设备映射(Device Map)
代码:
no_split_modules = model._get_no_split_modules(device_map)
device_map_kwargs = {"no_split_module_classes": no_split_modules}
max_memory = get_balanced_memory(
model,
dtype=target_dtype,
low_zero=(device_map == "balanced_low_0"),
max_memory=max_memory,
**device_map_kwargs,
)
device_map_kwargs.update({
'max_memory': max_memory,
'special_dtypes': {},
})
model.tie_weights()
device_map = infer_auto_device_map(model, dtype=target_dtype, **device_map_kwargs)
结果:
max_memory = {0: 14153003827.2, 'cpu': 12468932608}
device_map = OrderedDict([('', 0)])
说明:
- 获取模型中不应拆分的模块列表,防止这些模块被分配到不同的设备上。
- 计算每个设备上的最大内存,平衡内存使用。
- 调用
infer_auto_device_map自动推断设备映射,将模型的不同部分分配到适当的设备(如 GPU 0)。 - 在推断设备映射前,调用
model.tie_weights()确保共享参数正确绑定。
12. 恢复默认数据类型
代码:
if dtype_orig is not None:
torch.set_default_dtype(dtype_orig)
说明:
- 恢复 PyTorch 的默认数据类型,防止影响后续操作。
13. 加载预训练模型权重
代码:
(model,
missing_keys,
unexpected_keys,
mismatched_keys,
offload_index,
error_msgs,
) = cls._load_pretrained_model(
model,
state_dict,
loaded_state_dict_keys,
resolved_archive_file,
pretrained_model_name_or_path,
ignore_mismatched_sizes=ignore_mismatched_sizes,
sharded_metadata=sharded_metadata,
_fast_init=_fast_init,
low_cpu_mem_usage=low_cpu_mem_usage,
device_map=device_map,
offload_folder=offload_folder,
offload_state_dict=offload_state_dict,
dtype=torch_dtype,
hf_quantizer=hf_quantizer,
keep_in_fp32_modules=keep_in_fp32_modules,
gguf_path=gguf_path,
weights_only=weights_only,
)
说明:
- 使用
_load_pretrained_model方法加载模型的权重,包括处理分片权重。 - 返回加载后的模型和相关的信息,如缺失键、意外键和错误消息。
14. 绑定权重并设置模型为评估模式
代码:
model.tie_weights()
model.eval()
说明:
- 再次调用
tie_weights确保共享的权重被正确绑定,防止在加载权重后出现不一致。 - 将模型设置为评估模式,禁用 dropout 等训练时特定的操作。
15. 加载生成配置(Generation Config)
代码:
if model.can_generate():
model.generation_config = GenerationConfig.from_pretrained(
pretrained_model_name_or_path,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
_from_auto=from_auto_class,
_from_pipeline=from_pipeline,
**kwargs,
)
说明:
- 如果模型支持生成(如语言模型),加载生成配置
GenerationConfig。 - 这一步有助于在使用模型生成文本时,提供默认的生成参数。
16. 将模型分发到设备上
代码:
device_map_kwargs = {
'device_map': device_map,
'offload_dir': offload_folder,
'offload_index': offload_index,
'offload_buffers': offload_buffers,
'skip_keys': 'past_key_values'
}
dispatch_model(model, **device_map_kwargs)
说明:
- 准备参数,将模型的不同部分分配到指定的设备上。
- 调用
dispatch_model方法,根据设备映射,将模型的各个模块移动到相应的设备。
详细流程
1 参数说明
@classmethod
@restore_default_torch_dtype
def from_pretrained(
cls: Type[SpecificPreTrainedModelType],
pretrained_model_name_or_path: Optional[Union[str, os.PathLike]],
*model_args,
config: Optional[Union[PretrainedConfig, str, os.PathLike]] = None,
cache_dir: Optional[Union[str, os.PathLike]] = None,
ignore_mismatched_sizes: bool = False,
force_download: bool = False,
local_files_only: bool = False,
token: Optional[Union[str, bool]] = None,
revision: str = "main",
use_safetensors: Optional[bool] = None,
weights_only: bool = True,
**kwargs,
) -> SpecificPreTrainedModelType:
# 从 kwargs 中提取参数
state_dict = kwargs.pop("state_dict", None)
from_tf = kwargs.pop("from_tf", False)
from_flax = kwargs.pop("from_flax", False)
resume_download = kwargs.pop("resume_download", None)
proxies = kwargs.pop("proxies", None)
output_loading_info = kwargs.pop("output_loading_info", False)
use_auth_token = kwargs.pop("use_auth_token", None) # 处理已弃用的参数
trust_remote_code = kwargs.pop("trust_remote_code", None)
_ = kwargs.pop("mirror", None)
from_pipeline = kwargs.pop("_from_pipeline", None)
from_auto_class = kwargs.pop("_from_auto", False)
_fast_init = kwargs.pop("_fast_init", True)
torch_dtype = kwargs.pop("torch_dtype", None) # 处理 `torch_dtype` 参数
low_cpu_mem_usage = kwargs.pop("low_cpu_mem_usage", None)
device_map = kwargs.pop("device_map", None)
max_memory = kwargs.pop("max_memory", None)
offload_folder = kwargs.pop("offload_folder", None)
offload_state_dict = kwargs.pop("offload_state_dict", False)
offload_buffers = kwargs.pop("offload_buffers", False)
load_in_8bit = kwargs.pop("load_in_8bit", False)
load_in_4bit = kwargs.pop("load_in_4bit", False)
quantization_config = kwargs.pop("quantization_config", None) # 处理量化配置
subfolder = kwargs.pop("subfolder", "")
commit_hash = kwargs.pop("_commit_hash", None)
variant = kwargs.pop("variant", None)
adapter_kwargs = kwargs.pop("adapter_kwargs", {})
adapter_name = kwargs.pop("adapter_name", "default")
use_flash_attention_2 = kwargs.pop("use_flash_attention_2", False)
generation_config = kwargs.pop("generation_config", None)
gguf_file = kwargs.pop("gguf_file", None)
tp_plan = kwargs.pop("tp_plan", None)
| 参数 | 描述 | 类型 | 默认值 |
|---|---|---|---|
cls | 类本身,表示要实例化的模型类。该参数是类方法的第一个参数,由 Python 自动传递,用户在调用时无需指定。 | Type[SpecificPreTrainedModelType] | |
pretrained_model_name_or_path | 模型的名称或路径,可以是 Hugging Face 上的模型标识符、本地保存的模型目录路径,或 TensorFlow/Flax 模型的路径。详情请参阅参数说明。 | str 或 os.PathLike,可选 | |
*model_args | 传递给模型的其他位置参数,直接传递给模型的 __init__ 方法。 | tuple,可选 | |
config | 模型的配置对象,可以是配置类的实例、配置文件路径或配置名称。如果未提供,将自动加载配置。 | PretrainedConfig 或 str 或 os.PathLike,可选 | None |
state_dict | 用于替换从保存的权重文件加载的状态字典。此选项可用于从预训练配置创建模型,但加载您自己的权重。 | Dict[str, torch.Tensor],可选 | None |
cache_dir | 指定缓存目录,用于保存下载的模型文件,如果不想使用默认缓存目录,可以指定此参数。 | str 或 os.PathLike,可选 | None |
from_tf | 是否从 TensorFlow 检查点文件加载模型权重。 | bool,可选 | False |
from_flax | 是否从 Flax 检查点文件加载模型权重。 | bool,可选 | False |
ignore_mismatched_sizes | 当检查点的一些权重尺寸与模型权重尺寸不匹配时,是否忽略错误。例如,从具有 3 个标签的检查点实例化具有 10 个标签的模型时可能会发生此情况。 | bool,可选 | False |
force_download | 是否强制重新下载模型权重和配置文件,覆盖已缓存的版本。 | bool,可选 | False |
resume_download | 已废弃并忽略,所有下载现在默认会在可能的情况下自动恢复。将在 Transformers v5 中移除。 | bool,可选,已废弃 | None |
proxies | 用于协议或端点的代理服务器字典,例如 {'http': 'foo.bar:3128', 'https': 'foo.bar:4012'}。请求时将使用这些代理。 | Dict[str, str],可选 | None |
output_loading_info | 是否返回一个包含缺失键、意外键和错误消息的字典。 | bool,可选 | False |
local_files_only | 是否仅查找本地文件(即,不尝试下载模型)。 | bool,可选 | False |
token | 用于远程文件的 HTTP Bearer 授权的令牌。如果为 True 或未指定,将使用运行 huggingface-cli login 时生成的令牌。 | str 或 bool,可选 | None |
use_auth_token | 已废弃,请使用 token 参数代替。将在 Transformers v5 中移除。 | str 或 bool,可选,已废弃 | None |
revision | 要使用的特定模型版本。可以是分支名、标签名或提交 ID,因为我们使用基于 Git 的系统来存储模型和其他资源。因此,revision 可以是 Git 允许的任何标识符。 | str,可选 | "main" |
trust_remote_code | 是否信任远程代码。这在加载自定义模型时很有用,允许执行来自远程仓库的代码。 | bool,可选 | None |
mirror | 已废弃。请使用其他方式解决下载加速问题。 | str,可选,已废弃 | None |
_fast_init | 是否禁用快速初始化。一般情况下不需要修改此参数。 | bool,可选 | True |
attn_implementation | 模型中使用的注意力实现方式。可以是 "classic"(手动实现的注意力)、"torch"(使用 torch.nn.functional.scaled_dot_product_attention)、或 "flash"(使用 Flash Attention)。默认情况下,如果可用,对于 torch>=2.0.0 将使用 torch,否则默认为手动实现的 "classic"。 | str,可选 | None |
low_cpu_mem_usage | 尝试在加载模型时不使用超过 1 倍模型大小的 CPU 内存(包括峰值内存)。一般来说,为获得最佳效果,应与 device_map(如 "auto")一起使用。此功能是实验性的,可能随时更改。 | bool,可选 | None |
torch_dtype | 覆盖默认的 torch.dtype,在指定的数据类型下加载模型。可选值包括 torch.float16、torch.bfloat16、torch.float 等,或字符串形式的 "float32"、"float16" 等。设置为 "auto" 时,将尝试从模型配置或检查点中自动推断数据类型。 | str 或 torch.dtype,可选 | None |
device_map | 指定每个子模块应当放置的设备映射。如果只传递设备(例如,"cpu"、"cuda:1"、"mps",或 GPU 序号如 1),模型的整个模型将被映射到该设备。传递 device_map=0 表示将整个模型放在 GPU 0 上。要让 Accelerate 自动计算最优化的 device_map,请设置 device_map="auto"。 | str 或 Dict[str, Union[int, str, torch.device]] 或 int 或 torch.device,可选 | None |
max_memory | 设备标识符到最大内存的字典。如果未设置,将默认为每个 GPU 可用的最大内存和可用的 CPU 内存。 | Dict,可选 | None |
offload_folder | 如果 device_map 包含任何值为 "disk",则指定我们将卸载权重的文件夹。 | str 或 os.PathLike,可选 | None |
offload_state_dict | 如果为 True,将在加载模型时临时将 CPU 的 state_dict 卸载到硬盘,以避免在 CPU RAM 中出现内存不足的情况。默认情况下,当有磁盘卸载时,此值为 True。 | bool,可选 | False |
offload_buffers | 是否与模型参数一起卸载缓冲区。 | bool,可选 | None |
load_in_8bit | 已废弃。请使用 quantization_config 参数代替,将在未来版本中移除。 | bool,可选,已废弃 | False |
load_in_4bit | 已废弃。请使用 quantization_config 参数代替,将在未来版本中移除。 | bool,可选,已废弃 | False |
quantization_config | 用于量化的配置参数字典或 QuantizationConfigMixin 对象(例如 bitsandbytes、GPTQ)。建议将所有量化相关参数插入 quantization_config 中。 | QuantizationConfigMixin 或 Dict,可选 | None |
subfolder | 如果相关文件位于 Hugging Face 上模型仓库的子文件夹中,可以在此指定文件夹名称。 | str,可选 | "" |
variant | 如果指定,则从带有 variant 文件名的权重加载,例如 pytorch_model.<variant>.bin。使用 from_tf 或 from_flax 时,将忽略 variant。 | str,可选 | None |
use_safetensors | 是否使用 safetensors 格式的检查点。默认为 None。如果未指定且未安装 safetensors,将设置为 False。 | bool,可选 | None |
weights_only | 指示 unpickler 是否应限制为仅加载张量、原始类型、字典和通过 torch.serialization.add_safe_globals() 添加的任何类型。当设置为 False 时,可以加载包装的张量子类权重。 | bool,可选 | True |
adapter_name | 当前激活的适配器名称(如果使用了适配器),用于管理多任务学习或微调策略。用于处理 PEFT(参数高效微调)相关的适配器(adapter)。 | str,可选 | "default" |
adapter_kwargs | 传递给适配器的关键字参数字典,用于初始化和配置适配器。 | Dict,可选 | {} |
use_flash_attention_2 | 是否使用 Flash Attention 2 实现。这可能影响模型的注意力机制性能。 | bool,可选 | False |
generation_config | 文本生成的配置对象,如果模型支持生成功能,可以通过此参数提供生成配置。 | GenerationConfig,可选 | None |
gguf_file | 指定 GGUF 格式的文件路径,用于加载模型权重。 | str,可选 | None |
tp_plan | 张量并行计划,指定模型在张量并行化时的分布方式。目前仅支持 "auto" 值,用于自动计算张量并行计划。任何其他值将导致抛出 ValueError。如果指定了 tp_plan,则模型将自动应用张量并行化。需要注意的是,此功能可能依赖于特定的硬件和软件环境。 | str,可选 | None |
kwargs | 可用于更新配置对象(在其加载后)并初始化模型的剩余关键字参数字典(例如,output_attentions=True)。其行为取决于是否提供了 config:- 如果提供了 config 配置对象,**kwargs 将直接传递给底层模型的 __init__ 方法(我们假设所有相关的配置更新都已完成)。- 如果未提供配置对象, kwargs 将首先传递给配置类的初始化函数(PretrainedConfig.from_pretrained)。kwargs 中每个对应于配置属性的键都将用于使用提供的值覆盖该属性。不对应任何配置属性的其余键将传递给底层模型的 __init__ 方法。 | 剩余的关键字参数字典,可选 |
2 张量并行(Tensor Parallelism)
代码涉及到模型在张量并行(Tensor Parallelism)环境下的初始化,特别是在加载预训练模型时,如何正确地将模型的不同部分分配到正确的设备上,以支持分布式训练。
逐行解释如下:
-
检查
tp_plan和device_map是否同时被设置:if tp_plan is not None and tp_plan != "auto": # TODO: we can relax this check when we support taking tp_plan from a json file, for example. raise ValueError(f"tp_plan supports 'auto' only for now but got {tp_plan}.") if tp_plan is not None and device_map is not None: raise ValueError( "`tp_plan` and `device_map` are mutually exclusive. Choose either one for parallelization." )- 解释:
tp_plan目前只能设置为atuo,且tp_plan(张量并行计划)和device_map(设备映射)是用于模型并行化的两种不同方式。在同一时间,只能选择其中一种进行并行化配置,不能同时使用它们。 - 作用: 如果用户在调用
from_pretrained方法时,同时提供了tp_plan和device_map参数,就会引发ValueError,提示不能同时使用这两个参数。
- 解释:
-
初始化变量和注释:
tp_device = None- 解释: 初始化变量
tp_device,用于稍后存储当前张量并行进程应使用的设备。
- 解释: 初始化变量
-
如果使用
tp_plan,则设置设备映射:if tp_plan is not None: if not torch.distributed.is_initialized(): raise ValueError("Tensor Parallel requires torch.distributed to be initialized first.") # Detect the accelerator on the machine. If no accelerator is available, it returns CPU. device_type = torch._C._get_accelerator().type device_module = torch.get_device_module(device_type) # Get device with index assuming equal number of devices per host tp_device = torch.device(device_type, torch.distributed.get_rank() % device_module.device_count()) # This is the easiest way to dispatch to the current process device device_map = tp_device-
解释:
-
检查
torch.distributed是否已初始化:if not torch.distributed.is_initialized(): raise ValueError("Tensor Parallel requires torch.distributed to be initialized first.")- 作用: 使用张量并行必须依赖
torch.distributed库进行多进程通信。如果未初始化torch.distributed,则无法进行张量并行,因此抛出异常。
- 作用: 使用张量并行必须依赖
-
检测当前机器上的加速器类型:
device_type = torch._C._get_accelerator().type- 作用: 获取当前可用的计算加速器类型,例如
'cuda'、'cpu'、'mps'等。如果没有可用的加速器,则默认为'cpu'。
- 作用: 获取当前可用的计算加速器类型,例如
-
获取设备模块:
device_module = torch.get_device_module(device_type)- 作用: 根据设备类型获取对应的设备模块,例如
torch.cuda、torch.cpu等,用于进一步查询设备信息。
- 作用: 根据设备类型获取对应的设备模块,例如
-
计算当前进程应使用的设备:
tp_device = torch.device( device_type, torch.distributed.get_rank() % device_module.device_count() )-
作用:
-
torch.distributed.get_rank():获取当前进程的全局排名(rank),这是一个从0开始的整数,标识进程的编号。 -
device_module.device_count():获取当前机器上可用的设备数量,例如 GPU 数量。 -
计算
(rank % 设备数量),用于在多设备之间分配进程,使得每个进程对应一个设备。 -
创建一个
torch.device对象,指定设备类型和设备索引,表示当前进程应使用的设备。
-
-
假设: 每个主机(机器)上具有相同数量的设备,且进程总数为设备数量的倍数。
-
-
设置设备映射:
device_map = tp_device- 作用: 将计算得到的
tp_device赋值给device_map,用于在模型加载时,将模型的参数正确地分配到当前进程对应的设备上。
- 作用: 将计算得到的
-
-
3 FSDP(Fully Sharded Data Parallel)
FSDP(Fully Sharded Data Parallel)
1. 什么是 FSDP?
-
全称:Fully Sharded Data Parallel(完全切片的数据并行)。
-
简介:
-
FSDP 是 PyTorch 提供的一种分布式训练策略,旨在训练 超大规模 的神经网络模型。
-
通过对模型的参数和优化器状态进行 完全切片,实现跨多个 GPU 和节点的高效训练。
-
与传统的数据并行(DP)和模型并行(MP)相比,FSDP 在通信和内存占用方面具有优势。
-
def is_fsdp_enabled():
return (
torch.distributed.is_available()
and torch.distributed.is_initialized()
and strtobool(os.environ.get("ACCELERATE_USE_FSDP", "False")) )== 1
and strtobool(os.environ.get("FSDP_CPU_RAM_EFFICIENT_LOADING", "False")) == 1
)
if is_fsdp_enabled():
low_cpu_mem_usage = True
-
这段代码的主要功能:
-
定义了一个函数
is_fsdp_enabled(),用于检查 FSDP 是否启用。 -
如果 FSDP 启用,则将
low_cpu_mem_usage设置为True,以在模型加载时降低 CPU 内存占用。
-
-
使用 FSDP 的条件:
-
PyTorch 分布式功能可用且已初始化。
-
环境变量
ACCELERATE_USE_FSDP和FSDP_CPU_RAM_EFFICIENT_LOADING都设置为"True"。
-
-
FSDP 的意义:
-
允许在多 GPU 或多节点环境下,高效地训练超大规模模型。
-
降低每个设备的内存占用,提高训练效率。
-
-
设置
low_cpu_mem_usage的作用:- 进一步优化模型加载阶段的内存使用,防止 CPU 内存不足。
4 参数检查
if use_auth_token is not None:
warnings.warn(
"参数 `use_auth_token` 已被弃用,将在 Transformers v5 中移除。请使用 `token` 参数代替。",
FutureWarning,
)
if token is not None:
raise ValueError(
"`token` 和 `use_auth_token` 都被指定了。请仅设置 `token` 参数。"
)
token = use_auth_token
if token is not None and adapter_kwargs is not None and "token" not in adapter_kwargs:
adapter_kwargs["token"] = token
if use_safetensors is None and not is_safetensors_available():
use_safetensors = False
if trust_remote_code is True:
logger.warning(
"参数 `trust_remote_code` 应与 Auto 类一起使用。在这里没有效果,将被忽略。"
)
用于处理模型加载和初始化过程中的一些参数设置,特别是对 弃用参数的处理、认证令牌的管理、可选依赖的检查以及 参数的错用警告。
1. 处理已弃用的参数 use_auth_token
if use_auth_token is not None:
warnings.warn(
"参数 `use_auth_token` 已被弃用,将在 Transformers v5 中移除。请使用 `token` 参数代替。",
FutureWarning,
)
if token is not None:
raise ValueError(
"`token` 和 `use_auth_token` 都被指定了。请仅设置 `token` 参数。"
)
token = use_auth_token
-
解释:
-
if use_auth_token is not None:- 检查是否提供了参数
use_auth_token(值不为None)。 use_auth_token是一个已被弃用的参数,之前用于提供认证令牌。
- 检查是否提供了参数
-
发出弃用警告:
warnings.warn( "参数 `use_auth_token` 已被弃用,将在 Transformers v5 中移除。请使用 `token` 参数代替。", FutureWarning, )- 使用
warnings.warn函数,发出一个FutureWarning类型的警告,提示用户use_auth_token参数已被弃用,建议使用token参数代替。 - **目的:**告知用户参数即将被移除,鼓励他们更新代码以使用新的参数。
- 使用
-
检查参数冲突:
if token is not None: raise ValueError( "`token` 和 `use_auth_token` 都被指定了。请仅设置 `token` 参数。" )- 检查是否同时提供了
token和use_auth_token两个参数。 - 如果两者均被指定,抛出
ValueError异常,提示用户仅应使用token参数。
- 检查是否同时提供了
-
参数赋值:
token = use_auth_token- 如果仅提供了
use_auth_token参数,将其值赋给token,以保持后续代码的兼容性。
- 如果仅提供了
-
-
目的:
-
**处理弃用参数的过渡:**确保即使用户仍在使用旧参数,代码仍然可以运行,但同时提示他们更新代码。
-
**防止参数冲突:**确保不会同时使用新旧参数,避免产生混淆或意外行为。
-
2. 将 token 传递给适配器(Adapter)相关的参数
if token is not None and adapter_kwargs is not None and "token" not in adapter_kwargs:
adapter_kwargs["token"] = token
-
解释:
-
条件判断:
-
检查以下条件是否全部满足:
-
token不为None,即用户提供了认证令牌。 -
adapter_kwargs不为None,即存在适配器的关键字参数字典。 -
"token"不在adapter_kwargs字典中,即适配器参数中未指定token。
-
-
-
操作:
adapter_kwargs["token"] = token- 将
token添加到adapter_kwargs字典中,键为"token",值为认证令牌。
- 将
-
-
目的:
-
确保在加载 适配器(Adapter) 时,认证令牌能够被正确传递,从而能够访问需要认证的资源(例如私有的 Hugging Face 模型或数据集)。
-
适配器(Adapters) 是一种用于参数高效微调(PEFT)的技术,允许在不大幅修改预训练模型的情况下,适应特定任务。
-
3. 检查并设置 use_safetensors 参数
if use_safetensors is None and not is_safetensors_available():
use_safetensors = False
-
解释:
-
if use_safetensors is None:- 检查用户是否未指定
use_safetensors参数(值为None)。
- 检查用户是否未指定
-
not is_safetensors_available():-
调用
is_safetensors_available()函数,检查safetensors库是否可用(已安装)。 -
如果未安装
safetensors库,则返回False,not False为True。
-
-
操作:
use_safetensors = False- 将
use_safetensors设置为False,即不使用safetensors格式。
- 将
-
-
目的:
-
自动配置:在用户未指定
use_safetensors的情况下,根据环境自动决定是否使用safetensors。 -
兼容性:如果
safetensors库不可用,确保不会尝试加载或保存safetensors格式的文件,避免运行时报错。
-
-
背景知识:
-
safetensors是一种安全、高效的张量存储格式,比传统的 PyTorch.bin或.pt格式更安全、加载更快。 -
可选依赖:
safetensors是一个可选的第三方库,用户需要自行安装。
-
4. 处理 trust_remote_code 参数的警告
if trust_remote_code is True:
logger.warning(
"参数 `trust_remote_code` 应与 Auto 类一起使用。在这里没有效果,将被忽略。"
)
-
解释:
-
if trust_remote_code is True:- 检查
trust_remote_code参数是否被显式设置为True。
- 检查
-
日志警告:
logger.warning( "参数 `trust_remote_code` 应与 Auto 类一起使用。在这里没有效果,将被忽略。" )-
使用日志记录器
logger的warning方法,记录一条警告信息。 -
内容提示用户:
trust_remote_code参数应与 Auto 类一起使用,在当前上下文中无效,将被忽略。
-
-
-
目的:
-
用户提示:告知用户他们提供的
trust_remote_code参数在当前情况下无效,避免用户以为参数生效但实际未生效。 -
防止误用:提醒用户正确使用参数,避免潜在的安全风险或不必要的疑惑。
-
-
背景知识:
-
trust_remote_code参数用于指定是否信任从远程仓库加载并执行的代码。当加载自定义模型时,如果模型包含自定义的模型架构代码,可能需要设置此参数。 -
Auto 类:Hugging Face 提供了一系列的 Auto 类,如
AutoModel、AutoTokenizer等,可以根据模型名称自动加载相应的模型或分词器。在这些类中,trust_remote_code参数是有效的。 -
在特定模型类中,
trust_remote_code参数可能无效,因为这些模型类通常不涉及从远程仓库执行自定义代码。
-
5 GGUF检查
if gguf_file is not None and not is_accelerate_available():
raise ValueError("accelerate is required when loading a GGUF file `pip install accelerate`.")
-
当用户想要加载一个 GGUF 格式的模型文件时(
gguf_file is not None),程序需要确保accelerate库已安装(is_accelerate_available()返回True),以提供所需的并行化和优化功能。 -
如果
accelerate库未安装,程序无法正确加载 GGUF 文件,因此抛出ValueError异常,提示用户需要安装accelerate。
1. 什么是 GGUF 文件?
-
GGUF 格式:
-
GGUF 是一种用于存储大型语言模型以及相关数据的文件格式。这种格式旨在优化模型的加载和推理性能。
-
用途:用于模型的高效存储和加载,特别是在分布式或并行计算环境中。
-
特性:可能包含模型的参数、配置、元数据等信息,支持高效的序列化和反序列化。
-
2. 什么是 accelerate 库?
-
accelerate:-
简介:
accelerate是由 Hugging Face 开发的一个库,旨在简化和统一大型模型在不同硬件(如 GPU、TPU)和分布式环境中的训练和推理过程。 -
功能:
-
提供简单的接口来配置分布式训练环境。
-
支持模型并行、数据并行等多种并行化策略。
-
管理设备映射、内存优化、跨设备通信等复杂操作。
-
-
-
为什么需要
accelerate来加载 GGUF 文件?-
依赖性:加载 GGUF 文件可能需要涉及到分布式加载、设备映射等功能,这些功能由
accelerate库提供。 -
兼容性:确保模型在不同的硬件和环境中正确加载和运行。
-
6 commit_hash
if commit_hash is None:
if not isinstance(config, PretrainedConfig):
# We make a call to the config file first (which may be absent) to get the commit hash as soon as possible
resolved_config_file = cached_file(
pretrained_model_name_or_path,
CONFIG_NAME,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
_raise_exceptions_for_gated_repo=False,
_raise_exceptions_for_missing_entries=False,
_raise_exceptions_for_connection_errors=False,
)
commit_hash = extract_commit_hash(resolved_config_file, commit_hash)
else:
commit_hash = getattr(config, "_commit_hash", None)
-
cached_file函数:该函数用于从 Hugging Face Hub 或本地缓存中获取指定文件(如模型配置文件、权重文件)。如果文件已缓存,则直接返回缓存的文件路径;如果没有缓存且需要下载,则下载文件并缓存。 -
参数解析:
pretrained_model_name_or_path:预训练模型的名称或本地路径。CONFIG_NAME:配置文件的名称,通常为"config.json"。cache_dir、force_download、resume_download、proxies、local_files_only、token、revision、subfolder等:这些参数控制文件的下载和缓存行为,包括缓存目录、是否强制下载、代理设置、本地文件优先、访问受限仓库的令牌、指定模型的版本、子文件夹等。_raise_exceptions_for_*:这些参数设置为False,表示如果出现访问受限、文件缺失或连接错误等情况,不抛出异常,而是返回None。这样可以避免因为无法获取配置文件而中断流程。
-
目的:尝试获取模型配置文件的本地路径,以便后续提取
commit_hash。 -
可能的结果:
- 成功获取配置文件:
resolved_config_file为配置文件的本地路径。 - 未能获取配置文件:
resolved_config_file为None。
- 成功获取配置文件:
提取 commit_hash
commit_hash = extract_commit_hash(resolved_config_file, commit_hash)
-
解释:
-
extract_commit_hash函数:用于从已解析的文件路径(如配置文件路径)中提取文件对应的提交哈希值。 -
参数:
resolved_config_file:配置文件的本地路径,可能为None。commit_hash:当前的commit_hash值,开始时为None。
-
-
目的:如果成功获取了配置文件路径,从中提取
commit_hash。 -
逻辑:
- 如果
resolved_config_file不为None:尝试从文件的元数据或缓存信息中提取提交哈希值。 - 如果
resolved_config_file为None:无法提取commit_hash,保持为None。
- 如果
当 config 是 PretrainedConfig 的实例
else:
commit_hash = getattr(config, "_commit_hash", None)
-
解释:
getattr(config, "_commit_hash", None):尝试从config对象中获取属性_commit_hash,如果不存在该属性,则返回None。
-
目的:直接从配置对象中获取
commit_hash。 -
背景:
PretrainedConfig对象可能包含_commit_hash属性,记录了对应配置文件的提交哈希。
7 PEFT(Parameter-Efficient Fine-Tuning)适配器(adapter)
if is_peft_available():
_adapter_model_path = adapter_kwargs.pop("_adapter_model_path", None)
if _adapter_model_path is None:
_adapter_model_path = find_adapter_config_file(
pretrained_model_name_or_path,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
_commit_hash=commit_hash,
**adapter_kwargs,
)
if _adapter_model_path is not None and os.path.isfile(_adapter_model_path):
with open(_adapter_model_path, "r", encoding="utf-8") as f:
_adapter_model_path = pretrained_model_name_or_path
pretrained_model_name_or_path = json.load(f)["base_model_name_or_path"]
else:
_adapter_model_path = None
这段代码是在加载预训练模型时,用于处理 PEFT(Parameter-Efficient Fine-Tuning,参数高效微调) 相关的适配器(adapter)使模型能够正确地应用适配器,实现参数高效微调。PEFT 是一种通过添加适配器模块对大型预训练模型进行微调的方法,能够在保持大部分原始模型参数不变的情况下,适应新任务。
PEFT 是一个总称:包含了多种参数高效微调的方法,如 Adapter、Prefix Tuning、LoRA 等。
1. 检查 PEFT 库是否可用
if is_peft_available():
- 解释: 调用
is_peft_available()函数,检查当前环境中是否安装并可导入 PEFT 库。 - 目的: 只有在 PEFT 库可用的情况下,才进行后续的适配器处理。
2. 尝试从 adapter_kwargs 中获取 _adapter_model_path
_adapter_model_path = adapter_kwargs.pop("_adapter_model_path", None)
- 解释:
- 从
adapter_kwargs字典中取出键为"_adapter_model_path"的值,如果不存在,则返回None。 adapter_kwargs是用于适配器的额外关键字参数字典。
- 从
- 目的: 检查用户是否在参数中提供了适配器模型的路径。如果提供了,就使用该路径。
3. 如果 _adapter_model_path 为空,尝试查找适配器配置文件
- 当
_adapter_model_path为空时,调用find_adapter_config_file()函数,尝试找到适配器的配置文件(通常名为adapter_config.json)。 find_adapter_config_file()会在指定的模型路径或名称下查找适配器配置文件,使用的参数与模型加载时的参数类似。- 目的: 如果用户未明确指定适配器模型路径,程序会尝试自动查找适配器配置文件。
4. 如果找到适配器配置文件,读取并处理
- 检查
_adapter_model_path是否不为空并且指向一个实际存在的文件。 - 使用
with open打开适配器配置文件,读取其内容。 - 从配置文件的 JSON 内容中获取
"base_model_name_or_path"键的值,赋给pretrained_model_name_or_path。 - 将
_adapter_model_path设置为pretrained_model_name_or_path。 - 目的:
- 从适配器配置文件中获取原始的基础模型名称或路径。
- 确保在加载模型时,先加载正确的基础模型,然后再应用适配器。
- 注意:
- 这里将
_adapter_model_path重新设置为pretrained_model_name_or_path可能存在逻辑问题,可能是为了后续的处理。
5. 如果 PEFT 不可用,设置_adapter_model_path为None
- 这里将
- 解释: 如果 PEFT 库不可用,直接将
_adapter_model_path设置为None。 - 目的: 确保在 PEFT 不可用的情况下,不会尝试加载适配器相关的内容。
示例
假设用户想要加载一个带有适配器的模型:
from transformers import PreTrainedModel
# 适配器的参数
adapter_kwargs = {
"adapter_name": "my_adapter",
# 其他适配器相关参数
}
# 加载模型
model = PreTrainedModel.from_pretrained(
"my-pretrained-model",
adapter_kwargs=adapter_kwargs,
# 其他参数
)
在这个过程中,代码会:
- 检查 PEFT 是否可用。
- 尝试获取适配器配置文件。
- 读取适配器配置,获取基础模型名称或路径。
- 加载基础模型,然后应用适配器。
8 device_map格式标准化
# 如果传入的 device_map 是 int、str 或 torch.device 类型,将其转换为字典
if isinstance(device_map, torch.device):
device_map = {"": device_map}
elif isinstance(device_map, str) and device_map not in ["auto", "balanced", "balanced_low_0", "sequential"]:
try:
device_map = {"": torch.device(device_map)}
except RuntimeError:
raise ValueError(
"当以字符串形式传递 device_map 时,值需要是设备名称(例如 cpu、cuda:0)或 'auto'、'balanced'、'balanced_low_0'、'sequential' 之一,但找到了 {device_map}。"
)
elif isinstance(device_map, int):
if device_map < 0:
raise ValueError(
"您不能将负整数作为 device_map 传递。如果您想将模型放在 CPU 上,请传递 device_map = 'cpu'。"
)
else:
device_map = {"": device_map}
这段代码的目的是在加载预训练模型时,处理 device_map 参数,将其标准化为一个字典类型,以便于后续的设备映射操作。device_map 参数用于指定模型的各个部分应放置在哪个设备(如 CPU、GPU)上。
-
处理不同类型的 device_map 参数:
- 用户可以以多种形式传递
device_map参数,包括:torch.device对象:如torch.device('cuda:0')。- 字符串:如
"cpu"、"cuda:0"、"auto"、"balanced"等。 - 整数:表示 GPU 的索引,如
0表示第一块 GPU。
- 用户可以以多种形式传递
-
目的:
- 将这些不同形式的
device_map参数标准化为 字典类型,键为"",值为相应的设备对象或索引。 - 这样后续的处理可以统一地按照字典形式来处理设备映射。
- 将这些不同形式的
-
特殊关键字处理:
- 如果
device_map是字符串且等于"auto"、"balanced"、"balanced_low_0"、"sequential",则不进行转换,后续代码会专门处理这些关键字。 - 这些关键字通常用于自动计算最佳的设备映射方案。
- 如果
使用示例
-
将模型加载到 GPU 0 上:
device_map = 0 # 处理后变为: device_map = {"": 0} -
将模型加载到 CPU 上:
device_map = "cpu" # 处理后变为: device_map = {"": torch.device("cpu")} -
自动计算设备映射:
device_map = "auto" # 不进行转换,后续代码处理 "auto" 关键字 -
错误示例:
-
传入无效的字符串:
device_map = "invalid_device" # 会抛出 ValueError,提示无效的设备名称 -
传入负整数:
device_map = -1 # 会抛出 ValueError,提示不能使用负整数
-
9 检查device_map、low_cpu_mem_usage、DeepSpeed Zero-3 及 Accelerate 之间的关系和依赖
if device_map is not None:
if low_cpu_mem_usage is None:
low_cpu_mem_usage = True
elif not low_cpu_mem_usage:
raise ValueError("Passing along a `device_map` requires `low_cpu_mem_usage=True`")
if low_cpu_mem_usage:
if is_deepspeed_zero3_enabled():
raise ValueError(
"DeepSpeed Zero-3 is not compatible with `low_cpu_mem_usage=True` or with passing a `device_map`."
)
elif not is_accelerate_available():
raise ImportError(
f"Using `low_cpu_mem_usage=True` or a `device_map` requires Accelerate: `pip install 'accelerate>={ACCELERATE_MIN_VERSION}'`"
)
-
当用户提供了
device_map时,必须将low_cpu_mem_usage设置为True,以确保模型能够正确地分片加载到不同的设备上,从而节省 CPU 内存。 -
DeepSpeed Zero-3 模式负责管理内存优化,与
low_cpu_mem_usage和device_map的机制冲突,不能同时使用。 -
启用
low_cpu_mem_usage或使用device_map参数,需要依赖 Accelerate 库提供的功能。 -
关键要点:
-
使用
device_map时必须启用low_cpu_mem_usage=True。 -
low_cpu_mem_usage和device_map与 DeepSpeed Zero-3 模式不兼容,不能同时使用。 -
使用
low_cpu_mem_usage或device_map需要安装 Accelerate 库。
-
10 量化配置quantization_config
# 处理 kwargs 中的 bnb 配置,在 `load_in_{4/8}bit` 废弃后删除。
if load_in_4bit or load_in_8bit:
if quantization_config is not None:
raise ValueError(
"当传递 `quantization_config` 参数时,不能同时以关键字参数的形式传递 `load_in_4bit` 或 `load_in_8bit`。"
)
# 从 kwargs 中准备 BitsAndBytesConfig
config_dict = {k: v for k, v in kwargs.items() if k in inspect.signature(BitsAndBytesConfig).parameters}
config_dict = {**config_dict, "load_in_4bit": load_in_4bit, "load_in_8bit": load_in_8bit}
quantization_config, kwargs = BitsAndBytesConfig.from_dict(
config_dict=config_dict, return_unused_kwargs=True, **kwargs
)
logger.warning(
"参数 `load_in_4bit` 和 `load_in_8bit` 已被废弃,将在未来版本中移除。请在 `quantization_config` 参数中传递 `BitsAndBytesConfig` 对象。"
)
-
quantization_config is not None:检查用户是否也提供了新的quantization_config参数。 -
抛出
ValueError:如果用户同时提供了quantization_config和load_in_4bit/load_in_8bit,则抛出错误,提示不能同时使用。 -
inspect.signature(BitsAndBytesConfig).parameters:获取BitsAndBytesConfig类的构造函数接受的所有参数名称。 -
config_dict:- 遍历
kwargs,将其中与BitsAndBytesConfig参数匹配的项筛选出来,构成一个新的字典config_dict。从kwargs中提取与 BitsAndBytesConfig 相关的参数。
- 遍历
-
{**config_dict, ...}:更新config_dict,加入load_in_4bit和load_in_8bit参数。将废弃的参数添加到配置字典中,以便创建新的BitsAndBytesConfig对象。 -
BitsAndBytesConfig.from_dict():使用配置字典config_dict创建一个BitsAndBytesConfig实例。以兼容的方式创建BitsAndBytesConfig,并清理kwargs中的相关参数。 -
提示用户
load_in_4bit和load_in_8bit参数已被废弃,建议在quantization_config参数中传递BitsAndBytesConfig对象。
11 from_pt、user_agent、offline
from_pt = not (from_tf | from_flax)
user_agent = {"file_type": "model", "framework": "pytorch", "from_auto_class": from_auto_class}
if from_pipeline is not None:
user_agent["using_pipeline"] = from_pipeline
if is_offline_mode() and not local_files_only:
logger.info("Offline mode: forcing local_files_only=True")
local_files_only = True
- 根据用户提供的参数,确定模型是从哪个框架(PyTorch、TensorFlow、Flax)加载。
- 如果没有指定
from_tf或from_flax,则默认认为是从 PyTorch 加载。 - 在 HTTP 请求中,
User-Agent是一个头字段,用于标识请求发起的客户端应用程序类型、操作系统、软件版本等。 - 这里的
user_agent是用于与 Hugging Face Hub 交互时,传递额外的元数据,以便服务器进行统计、日志和兼容性处理。 - 这有助于统计、日志记录和兼容性管理。
- 将使用的管道信息添加到
user_agent,提供更详细的请求元数据。 - 有助于服务器端了解模型的使用场景。
- 在离线模式下,强制将
local_files_only设置为True,以防止程序尝试连接网络下载模型文件。 - 确保程序不会因为网络不可用而出错,提示用户模型只能从本地加载。
12 加载配置
# 如果未提供 config,或者 config 不是 PretrainedConfig 的实例,则加载配置
if not isinstance(config, PretrainedConfig):
config_path = config if config is not None else pretrained_model_name_or_path
config, model_kwargs = cls.config_class.from_pretrained(
config_path,
cache_dir=cache_dir,
return_unused_kwargs=True,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
_from_auto=from_auto_class,
_from_pipeline=from_pipeline,
**kwargs,
)
else:
# 如果提供了 config,则进行深拷贝,避免在 from_pretrained 中修改原始配置
config = copy.deepcopy(config)
# 处理可能的 'attn_implementation' 参数
kwarg_attn_imp = kwargs.pop("attn_implementation", None)
if kwarg_attn_imp is not None:
config._attn_implementation = kwarg_attn_imp
model_kwargs = kwargs
解释:
-
检查 config 是否为 PretrainedConfig 的实例:
if not isinstance(config, PretrainedConfig):- 如果
config不是PretrainedConfig的实例,说明需要从预训练模型的路径或名称中加载配置。
- 如果
-
确定配置加载路径:
config_path = config if config is not None else pretrained_model_name_or_path- 如果提供了
config参数(可能是一个路径或名称),则使用它作为配置的加载路径。 - 否则,使用
pretrained_model_name_or_path。
- 如果提供了
-
调用 cls.config_class.from_pretrained 加载配置:
config, model_kwargs = cls.config_class.from_pretrained( config_path, cache_dir=cache_dir, return_unused_kwargs=True, force_download=force_download, resume_download=resume_download, proxies=proxies, local_files_only=local_files_only, token=token, revision=revision, subfolder=subfolder, _from_auto=from_auto_class, _from_pipeline=from_pipeline, **kwargs, )cls.config_class是与模型类关联的配置类(例如,对于BertModel,它是BertConfig)。通过类属性config_class的类方法from_pretrained加载配置from_pretrained方法用于从指定的路径或名称加载预训练模型的配置。- 传递了一系列参数,如缓存目录、是否强制下载、代理、令牌等,以确保配置文件能够正确加载。
return_unused_kwargs=True会返回未使用的参数,这些参数可以在后续处理中传递给模型的构造函数。
-
处理已加载的配置和剩余的 kwargs:
-
如果提供了配置(即
config是PretrainedConfig的实例),则进行深拷贝以避免修改原始配置对象:else: config = copy.deepcopy(config) -
处理可能的
attn_implementation参数,如果它存在于kwargs中:kwarg_attn_imp = kwargs.pop("attn_implementation", None) if kwarg_attn_imp is not None: config._attn_implementation = kwarg_attn_imp model_kwargs = kwargs- 如果有
attn_implementation参数,将其设置到配置对象中。
- 如果有
-
13 处理量化(quantization) 配置
pre_quantized = hasattr(config, "quantization_config")
if pre_quantized and not AutoHfQuantizer.supports_quant_method(config.quantization_config):
pre_quantized = False
if pre_quantized or quantization_config is not None:
if pre_quantized:
config.quantization_config = AutoHfQuantizer.merge_quantization_configs(
config.quantization_config, quantization_config
)
else:
config.quantization_config = quantization_config
hf_quantizer = AutoHfQuantizer.from_config(
config.quantization_config,
pre_quantized=pre_quantized,
)
else:
hf_quantizer = None
if hf_quantizer is not None:
hf_quantizer.validate_environment(
torch_dtype=torch_dtype,
from_tf=from_tf,
from_flax=from_flax,
device_map=device_map,
weights_only=weights_only,
)
torch_dtype = hf_quantizer.update_torch_dtype(torch_dtype)
device_map = hf_quantizer.update_device_map(device_map)
# 为了确保支持流行的量化方法,可通过 `disable_telemetry` 禁用
user_agent["quant"] = hf_quantizer.quantization_config.quant_method.value
# 为了更有效地使用内存,将 `low_cpu_mem_usage` 强制设置为 `True`
if low_cpu_mem_usage is None:
low_cpu_mem_usage = True
logger.warning("`low_cpu_mem_usage` 为 None,现在模型已量化,默认设置为 True。")
is_quantized = hf_quantizer is not None
量化模型的配置文件: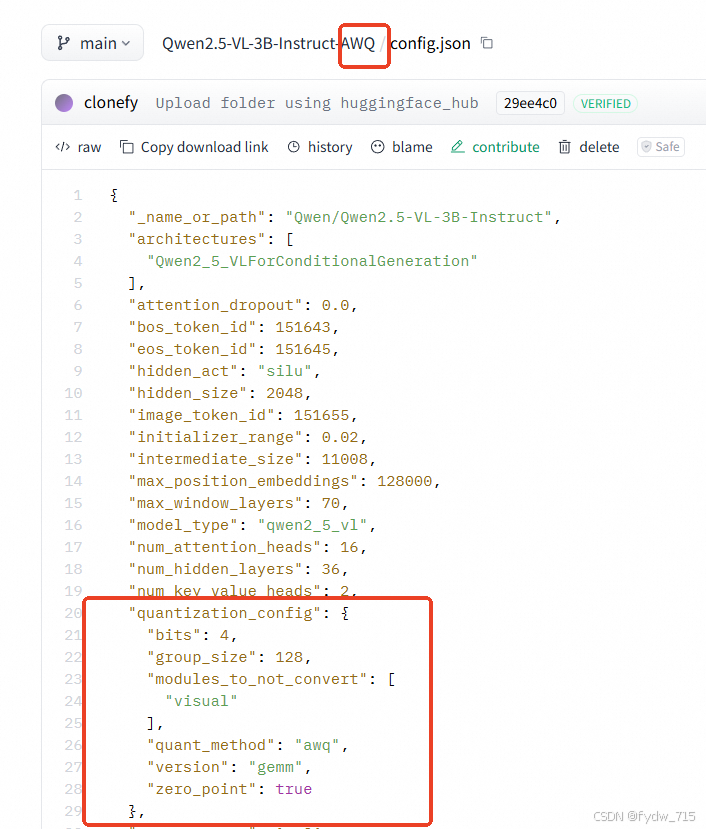
非量化模型的配置文件

1. 检查模型配置是否已有量化配置
pre_quantized = hasattr(config, "quantization_config")
- 解释:
- 使用
hasattr()函数检查config对象(模型的配置)是否具有属性quantization_config。 pre_quantized:布尔值,指示模型是否已经预先量化。
- 使用
2. 检查现有的量化方法是否受支持
if pre_quantized and not AutoHfQuantizer.supports_quant_method(config.quantization_config):
pre_quantized = False
- 解释:
- 如果模型已预先量化(
pre_quantized为True),但当前的AutoHfQuantizer不支持该量化方法,则将pre_quantized设置为False。
- 如果模型已预先量化(
- 目的:
- 确保仅在支持的量化方法下继续使用预先量化的配置。
3. 判断是否需要进行量化处理
if pre_quantized or quantization_config is not None:
- 解释:
- 如果模型已预先量化,或者用户提供了新的
quantization_config,则需要进行量化处理。
- 如果模型已预先量化,或者用户提供了新的
4. 处理量化配置
4.1 合并量化配置(如果必要)
if pre_quantized:
config.quantization_config = AutoHfQuantizer.merge_quantization_configs(
config.quantization_config, quantization_config
)
else:
config.quantization_config = quantization_config
- 解释:
- 如果模型已预先量化(
pre_quantized为True):- 使用
AutoHfQuantizer.merge_quantization_configs()方法,将现有的config.quantization_config与新的quantization_config合并。 - 目的: 合并配置以整合预先量化和用户提供的量化设置。
- 使用
- 否则:
- 将
config.quantization_config设置为用户提供的quantization_config。
- 将
- 如果模型已预先量化(
4.2 初始化量化器
hf_quantizer = AutoHfQuantizer.from_config(
config.quantization_config,
pre_quantized=pre_quantized,
)
- 解释:
- 使用
AutoHfQuantizer.from_config()方法,根据合并后的config.quantization_config初始化量化器hf_quantizer。 - 参数
pre_quantized指示模型是否已预先量化。
- 使用
5. 如果不需要量化,量化器为 None
else:
hf_quantizer = None
- 解释:
- 如果既没有预先量化,也没有提供新的量化配置,则不进行量化处理,将
hf_quantizer设置为None。
- 如果既没有预先量化,也没有提供新的量化配置,则不进行量化处理,将
6. 如果量化器已初始化,验证环境并更新参数
6.1 验证环境
if hf_quantizer is not None:
hf_quantizer.validate_environment(
torch_dtype=torch_dtype,
from_tf=from_tf,
from_flax=from_flax,
device_map=device_map,
weights_only=weights_only,
)
- 解释:
- 使用
hf_quantizer.validate_environment()方法,验证当前环境是否满足量化的要求。 - 检查的参数包括:
torch_dtype:PyTorch 数据类型。from_tf和from_flax:是否从 TensorFlow 或 Flax 加载模型。device_map:设备映射,模型的各部分应放置在哪些设备上。weights_only:是否仅加载权重。
- 使用
6.2 更新 torch_dtype
torch_dtype = hf_quantizer.update_torch_dtype(torch_dtype)
- 解释:
- 使用
hf_quantizer.update_torch_dtype()方法,根据量化器的要求更新torch_dtype。
- 使用
6.3 更新 device_map
device_map = hf_quantizer.update_device_map(device_map)
- 解释:
- 使用
hf_quantizer.update_device_map()方法,根据量化器的要求更新device_map。
- 使用
6.4 更新用户代理信息
user_agent["quant"] = hf_quantizer.quantization_config.quant_method.value
- 解释:
- 在
user_agent字典中添加键"quant",值为使用的量化方法。 - 目的:
- 传递量化方法的信息,可能用于分析和支持。
- 在
6.5 强制设置 low_cpu_mem_usage 为 True
if low_cpu_mem_usage is None:
low_cpu_mem_usage = True
logger.warning("`low_cpu_mem_usage` 为 None,现在模型已量化,默认设置为 True。")
- 解释:
- 如果
low_cpu_mem_usage未设置(为None),则将其强制设置为True。 - 记录一条警告,提示已默认设置为
True。
- 如果
- 目的:
- 在模型被量化的情况下,启用低 CPU 内存使用模式,以提高内存效率。
7. 设置 is_quantized 标志
is_quantized = hf_quantizer is not None
- 解释:
- 如果
hf_quantizer不为None,则表示模型已量化,设置is_quantized为True。 - 否则,
is_quantized为False。
- 如果
14 解析存档文件
if pretrained_model_name_or_path is not None and gguf_file is None:
pretrained_model_name_or_path = str(pretrained_model_name_or_path)
is_local = os.path.isdir(pretrained_model_name_or_path)
if is_local:
# 模型是本地目录
...
elif os.path.isfile(os.path.join(subfolder, pretrained_model_name_or_path)):
# 预训练模型是本地文件
archive_file = pretrained_model_name_or_path
is_local = True
elif is_remote_url(pretrained_model_name_or_path):
# 预训练模型是远程 URL
filename = pretrained_model_name_or_path
resolved_archive_file = download_url(pretrained_model_name_or_path)
else:
# 模型是 Hugging Face Hub 上的远程模型,需要下载
# 设置默认文件名
if from_tf:
filename = TF2_WEIGHTS_NAME
elif from_flax:
filename = FLAX_WEIGHTS_NAME
elif use_safetensors is not False:
filename = _add_variant(SAFE_WEIGHTS_NAME, variant)
else:
filename = _add_variant(WEIGHTS_NAME, variant)
try:
# 调用 cached_file 下载并缓存模型文件
cached_file_kwargs = {
"cache_dir": cache_dir,
"force_download": force_download,
"proxies": proxies,
"resume_download": resume_download,
"local_files_only": local_files_only,
"token": token,
"user_agent": user_agent,
"revision": revision,
"subfolder": subfolder,
"_raise_exceptions_for_gated_repo": False,
"_raise_exceptions_for_missing_entries": False,
"_commit_hash": commit_hash,
}
resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs)
# 处理可能的文件不存在和其他异常情况
# ...
except EnvironmentError:
# 处理下载错误
raise
if is_local:
logger.info(f"loading weights file {archive_file}")
resolved_archive_file = archive_file
else:
logger.info(f"loading weights file {filename} from cache at {resolved_archive_file}")
解释:
-
确定模型是本地还是远程的
is_local = os.path.isdir(pretrained_model_name_or_path) if is_local: # 模型是本地目录 ... elif os.path.isfile(os.path.join(subfolder, pretrained_model_name_or_path)): # 预训练模型是本地文件 ... elif is_remote_url(pretrained_model_name_or_path): # 预训练模型是远程 URL ... else: # 模型需要从 Hugging Face Hub 下载 ...- 解释:
- 使用
os.path.isdir判断pretrained_model_name_or_path是否是本地目录。 - 如果不是目录,检查是否是本地文件。
- 如果不是本地文件,使用
is_remote_url检查是否是远程 URL。 - 如果以上都不是,则假定需要从 Hugging Face Hub 下载模型。
- 使用
- 解释:
-
确定存档文件路径
a. 如果是本地模型,检查本地文件路径
if is_local: if from_tf and os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, TF_WEIGHTS_NAME + ".index")): # 从 TensorFlow 1.x 检查点加载 archive_file = os.path.join(pretrained_model_name_or_path, subfolder, TF_WEIGHTS_NAME + ".index") elif from_tf and os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, TF2_WEIGHTS_NAME)): # 从 TensorFlow 2.x 检查点加载 archive_file = os.path.join(pretrained_model_name_or_path, subfolder, TF2_WEIGHTS_NAME) elif from_flax and os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_NAME)): # 从 Flax 检查点加载 archive_file = os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_NAME) elif use_safetensors is not False and os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(SAFE_WEIGHTS_NAME, variant))): # 从 safetensors 格式的权重加载 archive_file = os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(SAFE_WEIGHTS_NAME, variant)) elif not use_safetensors and os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(WEIGHTS_NAME, variant))): # 从 PyTorch 格式的权重加载 archive_file = os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(WEIGHTS_NAME, variant)) else: # 未找到合适的权重文件,抛出错误 raise EnvironmentError(...) resolved_archive_file = archive_file- 解释:
- 在本地目录中,依次检查可能存在的权重文件,这取决于
from_tf、from_flax、use_safetensors等参数。 - 如果找到相应的文件,设置
archive_file和resolved_archive_file。 - 如果未找到合适的文件,抛出
EnvironmentError。
- 在本地目录中,依次检查可能存在的权重文件,这取决于
b. 如果是远程模型,调用
cached_file下载并缓存模型文件else: # 设置要下载的文件名 if from_tf: filename = TF2_WEIGHTS_NAME elif from_flax: filename = FLAX_WEIGHTS_NAME elif use_safetensors is not False: filename = _add_variant(SAFE_WEIGHTS_NAME, variant) else: filename = _add_variant(WEIGHTS_NAME, variant) try: # 调用 cached_file 下载并缓存模型文件 cached_file_kwargs = { "cache_dir": cache_dir, "force_download": force_download, "proxies": proxies, "resume_download": resume_download, "local_files_only": local_files_only, "token": token, "user_agent": user_agent, "revision": revision, "subfolder": subfolder, "_raise_exceptions_for_gated_repo": False, "_raise_exceptions_for_missing_entries": False, "_commit_hash": commit_hash, } resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs) # 处理文件不存在或其他异常情况 # ... except EnvironmentError: # 处理下载过程中的环境错误 raise- 解释:
- 根据模型的类型,设置需要下载的文件名,例如
pytorch_model.bin、tf_model.h5等。 - 使用
cached_file函数从 Hugging Face Hub 下载并缓存模型文件。 - 处理可能的异常,如文件不存在、网络错误等。
- 根据模型的类型,设置需要下载的文件名,例如
- 解释:
3. 处理 GGUF 文件的情况
elif gguf_file:
from .modeling_gguf_pytorch_utils import load_gguf_checkpoint
# 情况一:GGUF 文件在本地存在
if os.path.isfile(gguf_file):
gguf_path = gguf_file
# 情况二:GGUF 文件在远程,需要下载
else:
gguf_path = cached_file(pretrained_model_name_or_path, gguf_file, **cached_file_kwargs)
# 我们需要一个临时的模型来帮助重命名 state_dict
with torch.device("meta"):
dummy_model = cls(config)
state_dict = load_gguf_checkpoint(gguf_path, return_tensors=True, model_to_load=dummy_model)["tensors"]
resolved_archive_file = None
is_sharded = False
-
解释:
- 如果提供了
gguf_file参数,则处理 GGUF 格式的模型文件。 - 检查 GGUF 文件是否在本地存在,如果不存在,则尝试从远程下载。
- 使用临时的模型和
load_gguf_checkpoint函数加载模型的状态字典。 - 设置相关的变量,准备后续的模型加载流程。
- 如果提供了
3. 处理分片的检查点文件
# 如果检查点是分片的,我们需要下载并缓存每个检查点分片。
if is_sharded:
# 在这种情况下,resolved_archive_file 将成为一个文件列表,包含不同检查点分片的路径。
resolved_archive_file, sharded_metadata = get_checkpoint_shard_files(
pretrained_model_name_or_path,
resolved_archive_file,
cache_dir=cache_dir,
force_download=force_download,
proxies=proxies,
resume_download=resume_download,
local_files_only=local_files_only,
token=token,
user_agent=user_agent,
revision=revision,
subfolder=subfolder,
_commit_hash=commit_hash,
)
if is_sharded::检查变量is_sharded是否为True,表示模型的检查点是分片的。get_checkpoint_shard_files()函数:- 作用:获取所有分片文件的路径,并下载或缓存它们。
- 参数:
pretrained_model_name_or_path:预训练模型的名称或路径。resolved_archive_file:之前解析的检查点文件路径。- 其他参数:用于控制缓存、下载和网络配置等。
- 返回:
resolved_archive_file:更新为包含所有分片文件路径的列表。sharded_metadata:包含关于分片模型的元数据信息。
15. 检查并处理 safetensors 格式的文件
# 如果 safetensors 库可用,并且 resolved_archive_file 是字符串类型,且以 ".safetensors" 结尾
if (
is_safetensors_available()
and isinstance(resolved_archive_file, str)
and resolved_archive_file.endswith(".safetensors")
):
with safe_open(resolved_archive_file, framework="pt") as f:
metadata = f.metadata()
if metadata is None:
# 假设这是一个 PyTorch 检查点(针对 timm 检查点引入)
pass
elif metadata.get("format") == "pt":
pass
elif metadata.get("format") == "tf":
from_tf = True
logger.info("正在将 TensorFlow 的 safetensors 文件加载到 PyTorch 模型中。")
elif metadata.get("format") == "flax":
from_flax = True
logger.info("正在将 Flax 的 safetensors 文件加载到 PyTorch 模型中。")
elif metadata.get("format") == "mlx":
# 这是一个 mlx 文件,我们假设权重与 PyTorch 兼容
pass
else:
raise ValueError(
f"不兼容的 safetensors 文件。文件元数据的格式不是 ['pt', 'tf', 'flax', 'mlx'],而是 {metadata.get('format')}"
)
-
is_safetensors_available():检查是否安装了safetensors库,该库用于安全、高效地加载模型权重。 -
isinstance(resolved_archive_file, str):确认resolved_archive_file是一个字符串(即单个文件路径),而不是列表(表示分片文件)。 -
resolved_archive_file.endswith(".safetensors"):检查文件是否以.safetensors扩展名结尾,确认文件格式。 -
with safe_open(resolved_archive_file, framework="pt") as f::使用safe_open函数打开 safetensors 文件,指定框架为 PyTorch("pt")。 -
metadata = f.metadata():获取文件的元数据信息。 -
if metadata is None:- 如果元数据为
None,则假设这是一个 PyTorch 检查点。 - 原因:某些旧版本的 safetensors 文件可能没有元数据,默认认为是 PyTorch 格式。
- 如果元数据为
-
elif metadata.get("format") == "pt":- 如果元数据中的
"format"字段为"pt",表示这是一个 PyTorch 格式的 safetensors 文件。 - 处理:继续加载,无需特殊处理。
- 如果元数据中的
-
elif metadata.get("format") == "tf":- 如果
"format"为"tf",表示这是一个 TensorFlow 格式的 safetensors 文件。 - 处理:
- 将
from_tf变量设置为True,指示后续加载应按照 TensorFlow 模型进行处理。 - 记录一条日志信息,提示正在将 TensorFlow 的 safetensors 文件加载到 PyTorch 模型中。
- 将
- 如果
-
elif metadata.get("format") == "flax":- 如果
"format"为"flax",表示这是一个 Flax 格式的 safetensors 文件。 - 处理:
- 将
from_flax变量设置为True,指示后续加载应按照 Flax 模型进行处理。 - 记录一条日志信息,提示正在将 Flax 的 safetensors 文件加载到 PyTorch 模型中。
- 将
- 如果
-
elif metadata.get("format") == "mlx":- 如果
"format"为"mlx",表示这是一个 mlx(可能是特定硬件加速器格式)的文件。 - 处理:假设其权重与 PyTorch 兼容,继续加载。
- 如果
-
else:- 如果元数据中的
"format"字段不是以上支持的格式,抛出ValueError异常。 - 错误信息:提示不兼容的 safetensors 文件,并指出元数据中的格式。
- 如果元数据中的
15 加载状态字典
if from_pt:
if not is_sharded and state_dict is None:
# 现在是加载检查点的时候
state_dict = load_state_dict(resolved_archive_file, weights_only=weights_only)
-
解释:
-
if from_pt::如果模型是从 PyTorch 权重加载的(from_pt为True)。 -
if not is_sharded and state_dict is None::如果模型不是分片的,且state_dict尚未加载。-
is_sharded:指示模型的权重文件是否被分片。 -
state_dict:存储模型的权重参数。
-
-
**加载状态字典:**调用
load_state_dict函数,加载模型的权重。
-
-
目的:
- 确保在加载模型之前,
state_dict已经包含了模型的权重。
- 确保在加载模型之前,
当模型被分片时,加载方式与非分片模型 不同。对于分片的模型,不会直接调用 load_state_dict 函数来一次性加载完整的 state_dict,而是采用 按需加载 或 逐个加载分片 的方法。分片模型加载的核心发生在_load_pretrained_model方法中。
16 设置默认的 Torch 数据类型
在加载状态字典(state_dict)之后,根据实际加载的权重或配置,可能需要再次设置默认的 Torch 数据类型。
# 在加载状态字典后,我们需要设置模型的默认数据类型
# 首先,初始化 dtype_orig 为 None
dtype_orig = None
# 检查是否提供了 torch_dtype 参数
if torch_dtype is not None:
if isinstance(torch_dtype, str):
if torch_dtype == "auto":
# 如果 torch_dtype 为 "auto",尝试自动确定数据类型
if hasattr(config, "torch_dtype") and config.torch_dtype is not None:
torch_dtype = config.torch_dtype
logger.info(f"Will use torch_dtype={torch_dtype} as defined in model's config object")
else:
# 如果配置中不存在 torch_dtype,从权重中推断数据类型
if is_sharded and "dtype" in sharded_metadata:
torch_dtype = sharded_metadata["dtype"]
elif not is_sharded:
torch_dtype = get_state_dict_dtype(state_dict)
else:
one_state_dict = load_state_dict(resolved_archive_file[0], weights_only=weights_only)
torch_dtype = get_state_dict_dtype(one_state_dict)
del one_state_dict # 释放内存
logger.info(
f"Since the `torch_dtype` attribute can't be found in model's config object, "
f"will use torch_dtype={torch_dtype} as derived from model's weights"
)
elif hasattr(torch, torch_dtype):
# 如果 torch_dtype 是有效的 torch.dtype 字符串,获取对应的 dtype
torch_dtype = getattr(torch, torch_dtype)
# 更新配置中的 torch_dtype
for sub_config_key in config.sub_configs.keys():
sub_config = getattr(config, sub_config_key)
sub_config.torch_dtype = torch_dtype
elif isinstance(torch_dtype, torch.dtype):
# 如果 torch_dtype 是 torch.dtype 对象,直接使用
for sub_config_key in config.sub_configs.keys():
sub_config = getattr(config, sub_config_key)
sub_config.torch_dtype = torch_dtype
elif isinstance(torch_dtype, dict):
# 如果 torch_dtype 是字典,为每个子配置设置对应的 dtype
for key, curr_dtype in torch_dtype.items():
if hasattr(config, key):
value = getattr(config, key)
value.torch_dtype = curr_dtype
# 对于不属于任何子配置的模块,设置主要的 torch_dtype
torch_dtype = torch_dtype.get("")
config.torch_dtype = torch_dtype
if isinstance(torch_dtype, str) and hasattr(torch, torch_dtype):
torch_dtype = getattr(torch, torch_dtype)
elif torch_dtype is None:
torch_dtype = torch.float32
else:
# 如果 torch_dtype 参数类型无效,抛出错误
raise ValueError(
f"`torch_dtype` can be one of: `torch.dtype`, `'auto'`, a string of a valid `torch.dtype` or a `dict` with valid `torch_dtype` "
f"for each sub-config in composite configs, but received {torch_dtype}"
)
# 调用 cls._set_default_torch_dtype(torch_dtype) 设置默认的 Torch 数据类型
dtype_orig = cls._set_default_torch_dtype(torch_dtype)
else:
# 如果未提供 torch_dtype 参数,设置默认的 dtype 为浮点32(float32)
default_dtype = str(torch.get_default_dtype()).split(".")[-1]
config.torch_dtype = default_dtype
for key in config.sub_configs.keys():
value = getattr(config, key)
value.torch_dtype = default_dtype
解释:
-
初始化
dtype_origdtype_orig = None- 用于存储原始的默认数据类型,以便在模型加载完成后还原。
-
检查是否提供了
torch_dtype参数- 如果
torch_dtype不为None,则根据其类型进行处理。
- 如果
-
处理
torch_dtype-
字符串类型
-
如果
torch_dtype为"auto",则尝试自动确定数据类型:- 优先从模型的配置对象中获取
torch_dtype。 - 如果配置中没有定义
torch_dtype,则从加载的权重中推断数据类型,使用get_state_dict_dtype(state_dict)函数获取。 - 调用
logger.info记录使用的torch_dtype。
- 优先从模型的配置对象中获取
-
如果
torch_dtype是有效的torch.dtype名称字符串(如"float32"、"float16"等),则使用getattr(torch, torch_dtype)获取对应的torch.dtype对象。 -
更新配置对象中各子配置的
torch_dtype。
-
-
torch.dtype类型-
如果
torch_dtype本身就是一个torch.dtype对象,直接使用。 -
更新配置对象中各子配置的
torch_dtype。
-
-
字典类型
-
如果
torch_dtype是一个字典,则为每个子配置设置对应的torch_dtype。 -
提取主配置的
torch_dtype,并进行适当的转换。
-
-
其他情况
- 如果
torch_dtype的类型不符合上述任何一种,抛出ValueError。
- 如果
-
-
调用
cls._set_default_torch_dtype(torch_dtype)dtype_orig = cls._set_default_torch_dtype(torch_dtype)-
通过调用
cls._set_default_torch_dtype(torch_dtype)方法,设置 PyTorch 的默认数据类型。 -
这个方法会更改全局的默认数据类型,确保在模型实例化时使用正确的数据类型。
-
-
未提供
torch_dtype的情况-
如果
torch_dtype为None,则将默认数据类型设置为浮点32(float32)。 -
更新配置对象中各子配置的
torch_dtype。
-
** 检查是否需要保留在 float32 精度的模块**
# 检查 `_keep_in_fp32_modules` 是否不为 None
use_keep_in_fp32_modules = (cls._keep_in_fp32_modules is not None) and (
(torch_dtype == torch.float16) or hasattr(hf_quantizer, "use_keep_in_fp32_modules")
)
-
解释:
-
cls._keep_in_fp32_modules:类属性,可能包含需要保留在 float32 精度的模块名称列表。 -
use_keep_in_fp32_modules:布尔值,指示是否需要特殊处理这些模块。-
条件:
-
cls._keep_in_fp32_modules不为None,即存在需要特殊处理的模块。 -
torch_dtype为torch.float16,即模型整体使用 float16 精度。 -
或者量化器
hf_quantizer具有use_keep_in_fp32_modules属性。
-
-
-
-
目的:
- 当模型使用 float16 精度时,可能需要保留某些数值敏感的模块在 float32 精度,以避免数值不稳定。
确定已加载的状态字典键
if is_sharded:
loaded_state_dict_keys = sharded_metadata["all_checkpoint_keys"]
else:
loaded_state_dict_keys = list(state_dict.keys())
-
解释:
-
loaded_state_dict_keys:存储已加载的权重键名称列表。 -
如果模型是分片的,从
sharded_metadata中获取所有检查点的键。 -
否则,从
state_dict中获取键列表。
-
-
目的:
- 在后续处理中,可能需要知道哪些权重已经加载,以便进行匹配或替换。
在特定情况下将 state_dict 设置为 None
if (
gguf_path is None
and (low_cpu_mem_usage or (use_keep_in_fp32_modules and is_accelerate_available()))
and pretrained_model_name_or_path is not None
):
# 如果某些权重需要保持为 float32 并且未安装 accelerate,
# 我们稍后希望选择 state_dict 不为 None 的路径,即不需要 accelerate 的路径。
state_dict = None
-
解释:
-
条件判断:
-
gguf_path is None:未使用 GGUF 文件加载模型。 -
low_cpu_mem_usage为真,或者需要保留模块在 float32 且安装了 accelerate。 -
pretrained_model_name_or_path不为None:指定了预训练模型的路径或名称。
-
-
操作:
- 将
state_dict设置为None。
- 将
-
-
目的:
-
在低 CPU 内存使用模式下,或者需要保留模块在 float32 且安装了 accelerate 时,可能希望释放
state_dict,以减少内存占用。 -
这样在后续加载模型时,会采取不同的加载路径,不需要
state_dict。
-
17 实例化模型
这段代码使用了比较复杂的上下文管理,对上下文管理不熟悉的可以参考:Python:上下文管理器
config.name_or_path = pretrained_model_name_or_path
# 实例化模型。
init_contexts = [no_init_weights(_enable=_fast_init)]
if is_deepspeed_zero3_enabled() and not is_quantized and not _is_ds_init_called:
import deepspeed
logger.info("检测到 DeepSpeed ZeRO-3:为此模型激活 zero.init()")
init_contexts = [
deepspeed.zero.Init(config_dict_or_path=deepspeed_config()),
set_zero3_state(),
] + init_contexts
elif low_cpu_mem_usage:
if not is_accelerate_available():
raise ImportError(
f"使用 `low_cpu_mem_usage=True` 或 `device_map` 需要 Accelerate 库:`pip install 'accelerate>={ACCELERATE_MIN_VERSION}'`"
)
init_contexts.append(init_empty_weights())
if is_deepspeed_zero3_enabled() and is_quantized:
init_contexts.append(set_quantized_state())
config = copy.deepcopy(config) # 我们不想在 from_pretrained 中就地修改配置
if not getattr(config, "_attn_implementation_autoset", False):
config = cls._autoset_attn_implementation(
config, use_flash_attention_2=use_flash_attention_2, torch_dtype=torch_dtype, device_map=device_map
)
with ContextManagers(init_contexts):
# 确保我们不运行缓冲模块的初始化函数
model = cls(config, *model_args, **model_kwargs)
1. 设置模型配置的名称或路径
config.name_or_path = pretrained_model_name_or_path
-
解释:
- 将预训练模型的名称或路径赋值给配置对象
config的name_or_path属性。
- 将预训练模型的名称或路径赋值给配置对象
-
目的:
- 确保配置对象包含模型的来源信息,便于后续处理和日志记录。
** 初始化上下文管理器列表**
# 实例化模型。
init_contexts = [no_init_weights(_enable=_fast_init)]
-
解释:
- 初始化一个上下文管理器列表
init_contexts,初始包含no_init_weights。
- 初始化一个上下文管理器列表
-
no_init_weights(_enable=_fast_init):-
一个上下文管理器,用于在模型实例化时禁止权重的初始化,以减少内存使用。
-
_fast_init:一个布尔值,指示是否启用快速初始化。
-
-
目的:
- 在实例化模型时,避免立即分配权重内存,降低内存峰值。
3. 检查是否启用了 DeepSpeed ZeRO-3 模式
if is_deepspeed_zero3_enabled() and not is_quantized and not _is_ds_init_called:
import deepspeed
logger.info("检测到 DeepSpeed ZeRO-3:为此模型激活 zero.init()")
init_contexts = [
deepspeed.zero.Init(config_dict_or_path=deepspeed_config()),
set_zero3_state(),
] + init_contexts
-
解释:
-
条件判断:如果已经启用了 DeepSpeed ZeRO-3 模式,且模型未量化,且未调用过 DeepSpeed 初始化。
-
is_deepspeed_zero3_enabled():检查 DeepSpeed ZeRO-3 是否启用。 -
not is_quantized:确保模型未量化。 -
not _is_ds_init_called:确保 DeepSpeed 初始化未被调用过,避免重复初始化。
-
-
导入:导入
deepspeed库。 -
日志记录:记录一条信息,指示检测到 DeepSpeed ZeRO-3 模式。
-
更新
init_contexts:-
添加 DeepSpeed 的初始化上下文管理器:
-
deepspeed.zero.Init(config_dict_or_path=deepspeed_config()):-
DeepSpeed 的 Zero Init 上下文管理器,用于在 ZeRO-3 模式下高效初始化模型,减少内存占用。
-
config_dict_or_path=deepspeed_config():DeepSpeed 的配置,可能从配置文件或默认设置获取。
-
-
set_zero3_state():一个上下文管理器,用于设置 DeepSpeed ZeRO-3 的相关状态。
-
-
将新添加的上下文管理器放在
init_contexts的前面。
-
-
-
目的:
- 在 DeepSpeed ZeRO-3 模式下,使用 DeepSpeed 提供的工具,高效地初始化模型,节省内存。
4. 检查是否启用了低 CPU 内存使用模式
elif low_cpu_mem_usage:
if not is_accelerate_available():
raise ImportError(
f"使用 `low_cpu_mem_usage=True` 或 `device_map` 需要 Accelerate 库:`pip install 'accelerate>={ACCELERATE_MIN_VERSION}'`"
)
init_contexts.append(init_empty_weights())
-
解释:
-
条件判断:如果未启用 DeepSpeed ZeRO-3,但启用了
low_cpu_mem_usage模式。low_cpu_mem_usage:布尔值,指示是否启用低 CPU 内存使用模式。
-
检查 Accelerate 库:
-
is_accelerate_available():检查 Accelerate 库是否可用。 -
如果 Accelerate 不可用,抛出
ImportError,提示需要安装 Accelerate。
-
-
更新
init_contexts:- 添加
init_empty_weights()上下文管理器,用于在模型实例化时不分配实际的权重内存。
- 添加
-
-
目的:
- 在未使用 DeepSpeed 的情况下,通过 Accelerate 提供的工具,实现低内存占用的模型初始化。
5. 检查在 DeepSpeed ZeRO-3 模式下处理量化模型
if is_deepspeed_zero3_enabled() and is_quantized:
init_contexts.append(set_quantized_state())
-
解释:
-
条件判断:如果启用了 DeepSpeed ZeRO-3,且模型是量化的。
is_quantized:布尔值,指示模型是否被量化。
-
更新
init_contexts:- 添加
set_quantized_state()上下文管理器,用于在 DeepSpeed ZeRO-3 模式下正确地处理量化模型的状态。
- 添加
-
-
目的:
- 确保在使用 DeepSpeed ZeRO-3 时,量化模型能够正确初始化和加载。
6. 复制配置对象
config = copy.deepcopy(config) # 我们不想在 from_pretrained 中就地修改配置
-
解释:
- 使用
copy.deepcopy创建配置对象的深拷贝。
- 使用
-
目的:
- 避免在
from_pretrained方法中对原始配置对象进行就地修改,防止副作用。
- 避免在
7. 自动设置注意力机制的实现
if not getattr(config, "_attn_implementation_autoset", False):
config = cls._autoset_attn_implementation(
config, use_flash_attention_2=use_flash_attention_2, torch_dtype=torch_dtype, device_map=device_map
)
-
解释:
-
条件判断:如果配置中未设置
_attn_implementation_autoset属性或其值为False。 -
调用
_autoset_attn_implementation方法:-
cls._autoset_attn_implementation():类方法,用于自动设置注意力机制的实现方式。 -
参数:
-
config:模型配置对象。 -
use_flash_attention_2:布尔值,指示是否使用 Flash Attention 2。 -
torch_dtype:用于实例化模型的数据类型。 -
device_map:设备映射,指示模型的各部分应加载到哪些设备上。
-
-
-
更新配置对象:
- 方法可能会修改配置对象中的属性,指定注意力机制的实现选项。
-
-
目的:
- 根据当前的硬件、框架和配置,自动选择最佳的注意力机制实现,以优化模型性能。
8. 在上下文管理器中实例化模型
with ContextManagers(init_contexts):
# 确保我们不运行缓冲模块的初始化函数
model = cls(config, *model_args, **model_kwargs)
-
解释:
-
使用
ContextManagers上下文管理器,进入由init_contexts列表中的各个上下文管理器组成的上下文环境。-
ContextManagers(init_contexts):- 自定义的上下文管理器,可同时管理多个上下文。
-
-
实例化模型:
-
model = cls(config, *model_args, **model_kwargs):- 使用配置对象和其他参数,实例化模型类
cls。
- 使用配置对象和其他参数,实例化模型类
-
注意:由于上下文管理器的作用,模型的权重可能未被实际初始化,以减少内存使用。
-
-
-
目的:
- 在适当的上下文环境中,使用正确的设置和策略,实例化模型对象。
18 最后的准备工作
# 首先检查我们是否是从 `from_pt` 加载的
if use_keep_in_fp32_modules:
if is_accelerate_available() and not is_deepspeed_zero3_enabled():
low_cpu_mem_usage = True
keep_in_fp32_modules = model._keep_in_fp32_modules
else:
keep_in_fp32_modules = []
if hf_quantizer is not None:
hf_quantizer.preprocess_model(
model=model, device_map=device_map, keep_in_fp32_modules=keep_in_fp32_modules
)
# 我们将原始的 dtype 存储在量化模型的配置中,因为一旦权重被量化,我们就无法轻易检索它
# 注意,一旦您加载了一个量化模型,您就不能更改它的 dtype,因此这将成为唯一的可信来源
config._pre_quantization_dtype = torch_dtype
if isinstance(device_map, str):
special_dtypes = {}
if hf_quantizer is not None:
special_dtypes.update(hf_quantizer.get_special_dtypes_update(model, torch_dtype))
special_dtypes.update(
{
name: torch.float32
for name, _ in model.named_parameters()
if any(m in name for m in keep_in_fp32_modules)
}
)
target_dtype = torch_dtype
if hf_quantizer is not None:
target_dtype = hf_quantizer.adjust_target_dtype(target_dtype)
no_split_modules = model._get_no_split_modules(device_map)
if device_map not in ["auto", "balanced", "balanced_low_0", "sequential"]:
raise ValueError(
"如果传递一个字符串作为 `device_map`,请在 'auto'、'balanced'、'balanced_low_0' 或 'sequential' 中选择。"
)
device_map_kwargs = {"no_split_module_classes": no_split_modules}
if "special_dtypes" in inspect.signature(infer_auto_device_map).parameters:
device_map_kwargs["special_dtypes"] = special_dtypes
elif len(special_dtypes) > 0:
logger.warning(
"此模型有一些需要保持高精度的权重,您需要升级 `accelerate` 以正确处理它们(`pip install --upgrade accelerate`)。"
)
if device_map != "sequential":
max_memory = get_balanced_memory(
model,
dtype=target_dtype,
low_zero=(device_map == "balanced_low_0"),
max_memory=max_memory,
**device_map_kwargs,
)
else:
max_memory = get_max_memory(max_memory)
if hf_quantizer is not None:
max_memory = hf_quantizer.adjust_max_memory(max_memory)
device_map_kwargs["max_memory"] = max_memory
# 在创建设备映射之前,确保共享权重已绑定在一起
model.tie_weights()
device_map = infer_auto_device_map(model, dtype=target_dtype, **device_map_kwargs)
if hf_quantizer is not None:
hf_quantizer.validate_environment(device_map=device_map)
elif device_map is not None:
model.tie_weights()
tied_params = find_tied_parameters(model)
# 检查是否没有在不同设备上的共享参数
check_tied_parameters_on_same_device(tied_params, device_map)
1. 处理需要保留在 float32 精度的模块
if use_keep_in_fp32_modules:
if is_accelerate_available() and not is_deepspeed_zero3_enabled():
low_cpu_mem_usage = True
keep_in_fp32_modules = model._keep_in_fp32_modules
else:
keep_in_fp32_modules = []
-
解释:
-
use_keep_in_fp32_modules:布尔值,指示是否有模块需要保留在 float32 精度下。-
条件为真时,执行以下操作:
-
检查 Accelerate 库是否可用,且未启用 DeepSpeed ZeRO-3。
-
is_accelerate_available():检查 Accelerate 库是否可用。 -
is_deepspeed_zero3_enabled():检查是否启用了 DeepSpeed ZeRO-3 模式。
-
-
如果满足条件,将
low_cpu_mem_usage设置为True。 -
获取需要保留在 float32 精度的模块列表:
model._keep_in_fp32_modules:模型中需要保留高精度的模块名称列表。
-
-
条件为假时,设置
keep_in_fp32_modules为空列表。
-
-
-
目的:
- 确保在低精度计算(如 float16)下,哪些模块需要保持高精度(float32),以避免数值不稳定。
2. 量化模型的预处理
if hf_quantizer is not None:
hf_quantizer.preprocess_model(
model=model, device_map=device_map, keep_in_fp32_modules=keep_in_fp32_modules
)
# 我们将原始的 dtype 存储在量化模型的配置中,因为一旦权重被量化,我们就无法轻易检索它
# 注意,一旦您加载了一个量化模型,您就不能更改它的 dtype,因此这将成为唯一的可信来源
config._pre_quantization_dtype = torch_dtype
-
解释:
-
检查是否存在量化器(
hf_quantizer不为None)。 -
调用量化器的
preprocess_model方法,对模型进行预处理。-
参数:
-
model: 要处理的模型实例。 -
device_map: 设备映射,指示模型的各部分应加载到哪些设备。 -
keep_in_fp32_modules: 需要保持在 float32 精度的模块列表。
-
-
-
保存原始数据类型:
config._pre_quantization_dtype = torch_dtype:将原始的torch_dtype存储在配置中。
-
-
目的:
-
对模型进行适当的预处理,以适应量化需求。
-
保存原始数据类型信息,以便在量化后无法直接获取时参考。
-
3. 处理设备映射(device_map)
if isinstance(device_map, str):
special_dtypes = {}
if hf_quantizer is not None:
special_dtypes.update(hf_quantizer.get_special_dtypes_update(model, torch_dtype))
special_dtypes.update(
{
name: torch.float32
for name, _ in model.named_parameters()
if any(m in name for m in keep_in_fp32_modules)
}
)
target_dtype = torch_dtype
if hf_quantizer is not None:
target_dtype = hf_quantizer.adjust_target_dtype(target_dtype)
no_split_modules = model._get_no_split_modules(device_map)
if device_map not in ["auto", "balanced", "balanced_low_0", "sequential"]:
raise ValueError(
"如果传递一个字符串作为 `device_map`,请在 'auto'、'balanced'、'balanced_low_0' 或 'sequential' 中选择。"
)
device_map_kwargs = {"no_split_module_classes": no_split_modules}
if "special_dtypes" in inspect.signature(infer_auto_device_map).parameters:
device_map_kwargs["special_dtypes"] = special_dtypes
elif len(special_dtypes) > 0:
logger.warning(
"此模型有一些需要保持高精度的权重,您需要升级 `accelerate` 以正确处理它们(`pip install --upgrade accelerate`)。"
)
# ... 后续处理
-
解释:
-
检查
device_map是否为字符串类型。- 可能的字符串值包括:“auto”、“balanced”、“balanced_low_0”、“sequential”。
-
构建
special_dtypes字典:-
用于指定模型中特定参数需要使用的特殊数据类型。
-
从量化器获取特殊数据类型更新:
hf_quantizer.get_special_dtypes_update(model, torch_dtype):获取需要特殊处理的参数数据类型。
-
添加需要保持在 float32 精度的参数:
- 遍历模型的所有参数,如果参数名包含在
keep_in_fp32_modules中,则将其数据类型设为torch.float32。
- 遍历模型的所有参数,如果参数名包含在
-
-
调整目标数据类型
target_dtype:-
如果存在量化器,可能需要调整目标数据类型。
-
hf_quantizer.adjust_target_dtype(target_dtype):量化器调整后的数据类型。
-
-
获取不应拆分的模块列表:
model._get_no_split_modules(device_map):获取在设备映射中不应拆分的模块类列表。
-
检查
device_map的值是否有效:- 如果不是预期的字符串值,抛出
ValueError。
- 如果不是预期的字符串值,抛出
-
构建
device_map_kwargs字典,准备传递给设备映射推断函数:-
包含
no_split_module_classes和special_dtypes。 -
根据
infer_auto_device_map函数的参数签名,确定是否需要传递special_dtypes。 -
如果需要特殊数据类型,但 Accelerate 版本过旧,不支持该参数,给出警告提示升级。
-
-
-
目的:
-
自动推断模型的设备映射,将模型的不同部分分配到合适的设备上,优化性能和内存使用。
-
对于需要特殊数据类型处理的参数,确保设备映射过程中能够考虑到。
-
4. 管理内存分配
if device_map != "sequential":
max_memory = get_balanced_memory(
model,
dtype=target_dtype,
low_zero=(device_map == "balanced_low_0"),
max_memory=max_memory,
**device_map_kwargs,
)
else:
max_memory = get_max_memory(max_memory)
if hf_quantizer is not None:
max_memory = hf_quantizer.adjust_max_memory(max_memory)
device_map_kwargs["max_memory"] = max_memory
# 在创建设备映射之前,确保共享权重已绑定在一起
model.tie_weights()
device_map = infer_auto_device_map(model, dtype=target_dtype, **device_map_kwargs)
if hf_quantizer is not None:
hf_quantizer.validate_environment(device_map=device_map)
-
解释:
-
根据
device_map的值,确定内存分配策略:-
如果
device_map不等于"sequential",使用get_balanced_memory函数计算平衡的内存分配。-
参数:
-
model: 模型实例。 -
dtype: 目标数据类型。 -
low_zero: 布尔值,指示是否在零号设备上使用低内存。 -
max_memory: 可选,指定每个设备的最大内存。 -
**device_map_kwargs: 其他参数。
-
-
-
如果
device_map等于"sequential",使用get_max_memory函数获取最大内存。
-
-
如果存在量化器,可能需要调整最大内存设置:
hf_quantizer.adjust_max_memory(max_memory):量化器可根据需要调整内存分配。
-
更新
device_map_kwargs,添加max_memory信息。 -
在创建设备映射之前,确保共享权重已绑定:
model.tie_weights():确保共享参数正确绑定,以避免在不同设备上出现不一致。
-
推断设备映射:
infer_auto_device_map(model, dtype=target_dtype, **device_map_kwargs):根据模型、数据类型和参数,自动推断设备映射。
-
如果存在量化器,验证模型环境:
hf_quantizer.validate_environment(device_map=device_map):确保量化器和设备映射兼容。
-
-
目的:
-
根据模型大小、数据类型和设备情况,合理地将模型的各部分分配到设备上,确保内存不超载,同时优化性能。
-
确保共享参数不会被分配到不同的设备上,避免错误。
-
5. 处理非字符串类型的 device_map
elif device_map is not None:
model.tie_weights()
tied_params = find_tied_parameters(model)
# 检查是否没有在不同设备上的共享参数
check_tied_parameters_on_same_device(tied_params, device_map)
-
解释:
-
如果
device_map不是字符串类型,但不为None,则执行以下操作:-
确保共享权重已绑定:
model.tie_weights()。
-
找到共享参数:
tied_params = find_tied_parameters(model):获取模型中共享参数的映射。
-
检查共享参数是否在相同的设备上:
check_tied_parameters_on_same_device(tied_params, device_map):确保共享参数被分配到相同的设备上,避免在不同设备间共享参数造成错误。
-
-
-
目的:
- 在用户提供了自定义的设备映射时,确保模型的共享参数在相同的设备上,维护模型的正确性。
19 加载预训练权重
if from_tf:
#略
elif from_flax:
#略
elif from_pt:
# 恢复默认的 dtype
if dtype_orig is not None:
torch.set_default_dtype(dtype_orig)
(
model,
missing_keys,
unexpected_keys,
mismatched_keys,
offload_index,
error_msgs,
) = cls._load_pretrained_model(
model,
state_dict,
loaded_state_dict_keys, # XXX: 重命名?
resolved_archive_file,
pretrained_model_name_or_path,
ignore_mismatched_sizes=ignore_mismatched_sizes,
sharded_metadata=sharded_metadata,
_fast_init=_fast_init,
low_cpu_mem_usage=low_cpu_mem_usage,
device_map=device_map,
offload_folder=offload_folder,
offload_state_dict=offload_state_dict,
dtype=torch_dtype,
hf_quantizer=hf_quantizer,
keep_in_fp32_modules=keep_in_fp32_modules,
gguf_path=gguf_path,
weights_only=weights_only,
)
1. 检查并恢复默认的数据类型
if dtype_orig is not None:
torch.set_default_dtype(dtype_orig)
-
解释:
-
dtype_orig:在此前的代码中,如果在加载模型时更改了全局的默认数据类型(例如,为了兼容模型的权重),我们会保存原始的默认dtype。 -
torch.set_default_dtype(dtype_orig):将 PyTorch 的全局默认dtype恢复为原始值。
-
-
目的:
- 确保全局的
dtype设置不会因为加载模型而改变,防止影响其他代码或后续操作。
- 确保全局的
2. 调用 _load_pretrained_model 方法
(
model,
missing_keys,
unexpected_keys,
mismatched_keys,
offload_index,
error_msgs,
) = cls._load_pretrained_model(
model,
state_dict,
loaded_state_dict_keys,
resolved_archive_file,
pretrained_model_name_or_path,
ignore_mismatched_sizes=ignore_mismatched_sizes,
sharded_metadata=sharded_metadata,
_fast_init=_fast_init,
low_cpu_mem_usage=low_cpu_mem_usage,
device_map=device_map,
offload_folder=offload_folder,
offload_state_dict=offload_state_dict,
dtype=torch_dtype,
hf_quantizer=hf_quantizer,
keep_in_fp32_modules=keep_in_fp32_modules,
gguf_path=gguf_path,
weights_only=weights_only,
)
-
解释:
-
调用类的私有方法
_load_pretrained_model:用于将预训练的 PyTorch 模型权重加载到模型实例中,并处理加载过程中的各种配置和优化。 -
返回值:
model:加载了权重后的模型实例。missing_keys:模型中缺失的键(即在权重文件中存在,但在模型中未找到的参数)。unexpected_keys:权重文件中存在,但模型中不需要的参数键。mismatched_keys:模型中存在,但在权重文件中形状不匹配的参数键。offload_index:在使用零内存或低内存策略时,记录需要卸载的参数索引。error_msgs:加载过程中产生的错误信息。
-
参数:
model:模型实例,尚未加载预训练权重。state_dict:模型的状态字典,包含了预训练的参数。loaded_state_dict_keys:加载的状态字典中的键列表。resolved_archive_file:模型权重文件的路径。pretrained_model_name_or_path:预训练模型的名称或路径。- 其他参数:如
ignore_mismatched_sizes、sharded_metadata、low_cpu_mem_usage等,控制加载过程的行为和优化选项。
-
-
目的:
- 加载预训练权重:将预训练的参数加载到模型实例中。
- 处理和优化:根据提供的配置,优化加载过程,例如在低内存情况下分片加载、设备映射、量化处理等。
- 错误处理:记录加载过程中可能出现的各种问题,以便用户检查和处理。
涉及的参数和配置解释
常用参数
-
ignore_mismatched_sizes:- 作用:在加载权重时,如果发现权重的形状与模型期望的形状不匹配,是否忽略这些不匹配。
- 用途:在某些情况下,模型可能有一些层的参数形状与预训练权重的形状不同,设置为
True可以跳过这些不匹配,加载其他匹配的参数。
-
sharded_metadata:- 作用:如果模型的权重被分片存储,包含了关于分片的元数据信息。
- 用途:在加载分片模型时,帮助正确地加载所有分片的权重。
-
low_cpu_mem_usage:- 作用:启用低 CPU 内存使用模式,在加载大型模型时,减少内存占用。
- 用途:通过按需加载权重、延迟初始化等方法,降低内存峰值,适用于内存有限的环境。
-
device_map:- 作用:指定模型的各部分(如层、模块)应该加载到哪些设备上(如 CPU、GPU)。
- 用途:在多设备环境下,将模型分布到多个设备,以充分利用硬件资源。
-
hf_quantizer:- 作用:Hugging Face 提供的量化器,用于对模型进行量化处理。
- 用途:在加载模型时,应用量化,以减少模型大小,加速推理。
-
keep_in_fp32_modules:- 作用:指定哪些模块需要保留在 float32 精度下,不进行量化或低精度处理。
- 用途:对于数值敏感的模块(如 LayerNorm),保留高精度以避免精度损失。
20 权重共享
在加载预训练权重并处理完可能的缺失键、意外键和尺寸不匹配等信息后,模型需要确保某些权重之间的共享关系。例如,对于语言模型,输入嵌入层和输出嵌入层通常共享相同的权重。
调用 model.tie_weights() 方法可以确保这些共享关系被正确建立。
# 加载预训练权重后,调用 tie_weights 方法
if hasattr(model, "tie_weights"):
model.tie_weights()
- 解释:
- 使用
hasattr(model, "tie_weights")检查模型是否具有tie_weights方法。 - 如果存在,则调用
model.tie_weights(),将需要共享的权重绑定在一起。 - 这一步骤在模型加载预训练权重后执行,确保模型的结构和预期一致。
- 使用
2. tie_weights 方法的作用
tie_weights 方法通常在模型的定义中实现,用于共享模型中某些层的权重。以下是一个典型的实现示例:
def tie_weights(self):
"""
Tie the weights between the input embeddings and the output embeddings.
"""
output_embeddings = self.get_output_embeddings()
input_embeddings = self.get_input_embeddings()
if output_embeddings is not None and input_embeddings is not None:
output_embeddings.weight = input_embeddings.weight
- 解释:
- 方法
get_output_embeddings()和get_input_embeddings()分别获取模型的输出嵌入层和输入嵌入层。 - 将输出嵌入层的权重指向输入嵌入层的权重,实现权重共享。
- 这样,当更新输入嵌入层的权重时,输出嵌入层的权重也会同步更新,反之亦然。
- 方法
注意事项:
-
为什么需要权重共享?
- 权重共享可以减少模型参数的数量,降低模型的复杂度。
- 在语言模型中,共享输入和输出嵌入层的权重可以在一定程度上提高模型的泛化能力。
-
何时调用
tie_weights?- 通常在加载预训练权重后调用,以确保共享关系在最新的权重上正确建立。
-
模型必须具有
tie_weights方法吗?- 不一定,但大多数支持权重共享的模型都会实现该方法。
- 如果模型不支持权重共享或不需要共享权重,那么可能不存在
tie_weights方法。
21 设置模型为评估模式
调用 `model.eval()`,将模型设置为评估模式。这将停用一些模块(例如 `Dropout`)。
22加载生成配置(如果适用)
# 检查模型是否支持生成
if model.can_generate():
try:
# 尝试加载生成配置
model.generation_config = GenerationConfig.from_pretrained(
pretrained_model_name_or_path,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
_from_auto=from_auto_class,
**kwargs,
)
except (OSError, TypeError):
logger.info(
"Generation config file not found, using a generation config created from the model config."
)
# 如果未找到生成配置,则从模型配置创建一个新的生成配置
model.generation_config = GenerationConfig.from_model_config(model.config)
else:
model.generation_config = None
1. 检查模型是否支持生成
if model.can_generate():
- 解释:
- 使用
model.can_generate()方法判断模型是否支持生成。 - 只有当模型具备生成能力时,才需要加载生成配置。
- 生成能力通常指模型能够执行文本生成任务,例如语言模型、文本摘要等。
- 使用
2. 尝试加载生成配置
try:
# 尝试从预训练模型的路径或名称中加载生成配置
model.generation_config = GenerationConfig.from_pretrained(
pretrained_model_name_or_path,
cache_dir=cache_dir,
force_download=force_download,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
token=token,
revision=revision,
subfolder=subfolder,
_from_auto=from_auto_class,
**kwargs,
)
- 解释:
- 调用
GenerationConfig.from_pretrained方法,从指定的模型路径或名称中加载生成配置(通常是generation_config.json文件)。 - 传递了一系列参数,以确保生成配置能够正确加载:
cache_dir:缓存目录,用于存储下载的配置文件。force_download:是否强制重新下载配置文件。resume_download:在下载过程中如果中断,是否继续下载。proxies:网络代理设置。local_files_only:是否仅使用本地文件,不进行网络下载。token:访问私有模型时的身份验证令牌。revision:模型版本或分支。subfolder:子文件夹,如果配置文件位于特定的子目录中。_from_auto:是否从自动模型加载器中调用。**kwargs:其他关键字参数。
- 调用
3. 处理加载生成配置时的异常
except (OSError, TypeError):
logger.info(
"Generation config file not found, using a generation config created from the model config."
)
# 如果未找到生成配置,则从模型配置创建一个新的生成配置
model.generation_config = GenerationConfig.from_model_config(model.config)
- 解释:
- 如果在加载生成配置的过程中出现
OSError或TypeError异常,表示生成配置文件可能不存在或格式不正确。 - 这时,记录一条信息,表示未找到生成配置文件,将使用模型配置创建新的生成配置。
- 调用
GenerationConfig.from_model_config(model.config)方法,从模型的配置对象中创建一个默认的生成配置。
- 如果在加载生成配置的过程中出现
4. 如果模型不支持生成
else:
model.generation_config = None
- 解释:
- 如果模型不支持生成,将
model.generation_config设置为None。 - 这意味着对于不具备生成能力的模型,不需要加载或设置生成配置。
- 如果模型不支持生成,将
扩展说明:
-
GenerationConfig类:GenerationConfig类用于保存生成相关的配置参数,如最大生成长度、解码策略(如 beam search、top-k sampling)、重复惩罚等。- 这些参数在使用模型进行文本生成时非常重要,影响生成结果的质量和多样性。
-
为什么需要从预训练模型中加载生成配置?
- 因为模型的作者可能在训练时针对生成任务进行了优化,并保存在生成配置文件中。
- 加载预训练的生成配置可以确保生成过程使用与训练时一致的参数设置,获得更好的生成效果。
-
GenerationConfig.from_pretrained方法:- 该方法类似于模型和配置的
from_pretrained方法,可从指定的路径或名称中加载生成配置文件。
- 该方法类似于模型和配置的
-
处理异常的原因:
- 并非所有的预训练模型都会包含生成配置文件。
- 为了提高代码的鲁棒性,当生成配置文件缺失时,程序可以从模型配置创建默认的生成配置,以确保生成功能的正常运行。
23 分配模型(如果提供了 device_map)
# 如果有必要,将模型分发到所有设备上,并设置钩子函数
if device_map is not None:
device_map_kwargs = {
"device_map": device_map,
"offload_dir": offload_folder,
"offload_index": offload_index,
"offload_buffers": offload_buffers,
}
if "skip_keys" in inspect.signature(dispatch_model).parameters:
device_map_kwargs["skip_keys"] = model._skip_keys_device_placement
# 针对 HQQ 方法,在单 GPU 环境中,我们强制设置钩子
if (
"force_hooks" in inspect.signature(dispatch_model).parameters
and hf_quantizer is not None
and hf_quantizer.quantization_config.quant_method == QuantizationMethod.HQQ
):
device_map_kwargs["force_hooks"] = True
if (
hf_quantizer is not None
and hf_quantizer.quantization_config.quant_method == QuantizationMethod.FBGEMM_FP8
and isinstance(device_map, dict)
and ("cpu" in device_map.values() or "disk" in device_map.values())
):
device_map_kwargs["offload_buffers"] = True
if not is_fsdp_enabled() and not is_deepspeed_zero3_enabled():
dispatch_model(model, **device_map_kwargs)
if hf_quantizer is not None:
hf_quantizer.postprocess_model(model, config=config)
model.hf_quantizer = hf_quantizer
if _adapter_model_path is not None:
model.load_adapter(
_adapter_model_path,
adapter_name=adapter_name,
token=token,
adapter_kwargs=adapter_kwargs,
)
if output_loading_info:
if loading_info is None:
loading_info = {
"missing_keys": missing_keys,
"unexpected_keys": unexpected_keys,
"mismatched_keys": mismatched_keys,
"error_msgs": error_msgs,
}
return model, loading_info
if tp_plan is not None:
assert tp_device is not None, "tp_device not set!"
if not model.supports_tp_plan:
raise NotImplementedError("This model does not have a tensor parallel plan.")
# 假设将模型在整个进程组中进行分片
world_size = torch.distributed.get_world_size()
device_mesh = torch.distributed.init_device_mesh(tp_device.type, (world_size,))
# 应用张量并行
model.tensor_parallel(device_mesh)
1. 模型的设备映射和分发
if device_map is not None:
device_map_kwargs = {
"device_map": device_map,
"offload_dir": offload_folder,
"offload_index": offload_index,
"offload_buffers": offload_buffers,
}
if "skip_keys" in inspect.signature(dispatch_model).parameters:
device_map_kwargs["skip_keys"] = model._skip_keys_device_placement
# 针对 HQQ 方法,在单 GPU 环境中,我们强制设置钩子
if (
"force_hooks" in inspect.signature(dispatch_model).parameters
and hf_quantizer is not None
and hf_quantizer.quantization_config.quant_method == QuantizationMethod.HQQ
):
device_map_kwargs["force_hooks"] = True
if (
hf_quantizer is not None
and hf_quantizer.quantization_config.quant_method == QuantizationMethod.FBGEMM_FP8
and isinstance(device_map, dict)
and ("cpu" in device_map.values() or "disk" in device_map.values())
):
device_map_kwargs["offload_buffers"] = True
if not is_fsdp_enabled() and not is_deepspeed_zero3_enabled():
dispatch_model(model, **device_map_kwargs)
解释
-
if device_map is not None:- 检查是否提供了
device_map,即模型的设备映射。 device_map:一个字典或字符串,指定模型的各个部分应被加载到哪些设备上(如 CPU、GPU 等)。
- 检查是否提供了
-
device_map_kwargs = { ... }- 构建一个字典
device_map_kwargs,包含传递给dispatch_model函数的参数。 - 参数包括:
"device_map":设备映射。"offload_dir":卸载参数的目录(offload_folder)。"offload_index":卸载索引。"offload_buffers":是否卸载缓冲区(offload_buffers)。
- 构建一个字典
-
检查
dispatch_model函数是否支持skip_keys参数if "skip_keys" in inspect.signature(dispatch_model).parameters:- 使用
inspect.signature检查dispatch_model的函数参数列表,看看是否支持skip_keys参数。 - 如果支持,添加
"skip_keys"参数到device_map_kwargs中,值为model._skip_keys_device_placement。
- 使用
-
针对 HQQ 量化方法的特殊处理
if ( "force_hooks" in inspect.signature(dispatch_model).parameters and hf_quantizer is not None and hf_quantizer.quantization_config.quant_method == QuantizationMethod.HQQ ):- 检查
dispatch_model函数是否支持force_hooks参数。 - 检查是否存在量化器
hf_quantizer,并且量化方法是HQQ(Hypothetical Quantization Quantizer)。 - 如果条件满足,设置
device_map_kwargs["force_hooks"] = True,强制在单 GPU 环境中设置钩子。
- 检查
-
针对 FBGEMM FP8 量化方法的卸载缓冲区处理
if ( hf_quantizer is not None and hf_quantizer.quantization_config.quant_method == QuantizationMethod.FBGEMM_FP8 and isinstance(device_map, dict) and ("cpu" in device_map.values() or "disk" in device_map.values()) ):- 检查是否存在量化器,量化方法是
FBGEMM_FP8,并且device_map是字典类型,且映射中包含"cpu"或"disk"。 - 如果条件满足,设置
device_map_kwargs["offload_buffers"] = True。
- 检查是否存在量化器,量化方法是
-
检查是否未启用 FSDP 或 DeepSpeed ZeRO-3
if not is_fsdp_enabled() and not is_deepspeed_zero3_enabled():- 检查是否未启用 Fully Sharded Data Parallel(FSDP)和 DeepSpeed ZeRO-3。
- 如果未启用,则调用
dispatch_model(model, **device_map_kwargs)。
-
dispatch_model函数- 作用:根据
device_map,将模型的不同部分分配到指定的设备上,并设置必要的钩子函数,以支持按需加载、异步加载等功能。 device_map_kwargs:传递给dispatch_model的参数,配置设备映射和卸载等行为。
- 作用:根据
目的
- 分发模型:将模型的各个部分按照设备映射加载到合适的设备上,可能涉及到卸载机制,以优化内存使用。
- 设置钩子函数:在模型的参数或模块上设置钩子,以支持按需加载、异步加载、量化等特性。
- 兼容特殊的量化方法:针对某些量化方法(如 HQQ、FBGEMM_FP8),根据需求强制设置钩子或调整卸载缓冲区的行为。
2. 量化模型的后处理
if hf_quantizer is not None:
hf_quantizer.postprocess_model(model, config=config)
model.hf_quantizer = hf_quantizer
解释
-
if hf_quantizer is not None:- 检查是否存在量化器
hf_quantizer。
- 检查是否存在量化器
-
hf_quantizer.postprocess_model(model, config=config)- 调用量化器的
postprocess_model方法,对模型进行后处理。 - 作用:在模型加载完成后,可能需要对模型进行额外的处理,以适配量化器的要求。这个后处理可能包括调整参数、设置特殊的属性等。
- 调用量化器的
-
model.hf_quantizer = hf_quantizer- 将量化器实例
hf_quantizer赋值给模型的hf_quantizer属性。 - 目的:在模型实例中保留对量化器的引用,方便后续操作或推理过程中使用。
- 将量化器实例
目的
- 完成量化过程:在模型加载并分发到设备后,进行量化器的后处理,确保模型在量化环境下能够正确运行。
- 保存量化器信息:将量化器保存到模型实例中,以便在后续使用过程中访问量化器的配置和方法。
3. 适配器的加载
if _adapter_model_path is not None:
model.load_adapter(
_adapter_model_path,
adapter_name=adapter_name,
token=token,
adapter_kwargs=adapter_kwargs,
)
解释
-
if _adapter_model_path is not None:- 检查是否提供了适配器模型的路径
_adapter_model_path。
- 检查是否提供了适配器模型的路径
-
model.load_adapter(...)- 调用模型的
load_adapter方法,加载适配器模型。 - 参数:
_adapter_model_path:适配器模型的路径。adapter_name:适配器的名称。token:访问 Hugging Face Hub 所需的令牌(如果适配器存储在私有仓库中)。adapter_kwargs:其他适配器加载的关键字参数。
- 调用模型的
目的
- 加载适配器模型:将预训练的适配器(Adapter)加载到模型中,用于特定任务的微调或定制化。
- 适配器机制:适配器是一种在预训练模型上添加的小型可训练模块,允许在保持预训练模型参数不变的情况下,适应新任务。
4. 加载信息的输出
if output_loading_info:
if loading_info is None:
loading_info = {
"missing_keys": missing_keys,
"unexpected_keys": unexpected_keys,
"mismatched_keys": mismatched_keys,
"error_msgs": error_msgs,
}
return model, loading_info
解释
-
if output_loading_info:- 检查是否需要输出加载信息,
output_loading_info是一个布尔值。
- 检查是否需要输出加载信息,
-
if loading_info is None:- 如果
loading_info为空,构建一个新的loading_info字典,包含加载过程中收集到的信息。
- 如果
-
loading_info字典包含:"missing_keys":模型中缺失的参数键列表。"unexpected_keys":在加载的状态字典中存在,但模型中未预期的参数键列表。"mismatched_keys":参数形状不匹配的键列表。"error_msgs":加载过程中发生的错误信息。
-
return model, loading_info- 返回模型实例和加载信息。
目的
- 提供详细的加载信息:当用户需要了解加载过程中发生的情况时,返回包含详细信息的字典,方便调试和验证模型加载的正确性。
5. 应用张量并行
if tp_plan is not None:
assert tp_device is not None, "tp_device not set!"
if not model.supports_tp_plan:
raise NotImplementedError("This model does not have a tensor parallel plan.")
# 假设将模型在整个进程组中进行分片
world_size = torch.distributed.get_world_size()
device_mesh = torch.distributed.init_device_mesh(tp_device.type, (world_size,))
# 应用张量并行
model.tensor_parallel(device_mesh)
解释
-
if tp_plan is not None:- 检查是否提供了张量并行计划
tp_plan。
- 检查是否提供了张量并行计划
-
assert tp_device is not None, "tp_device not set!"- 断言
tp_device不为None,如果为None,抛出断言错误,提示未设置tp_device。
- 断言
-
if not model.supports_tp_plan:- 检查模型是否支持张量并行计划,如果不支持,抛出
NotImplementedError。
- 检查模型是否支持张量并行计划,如果不支持,抛出
-
初始化设备网格
-
world_size = torch.distributed.get_world_size()- 获取当前分布式环境的全局进程数
world_size。
- 获取当前分布式环境的全局进程数
-
device_mesh = torch.distributed.init_device_mesh(tp_device.type, (world_size,))- 初始化设备网格(
device_mesh),类型为tp_device.type(如'cuda'或'cpu'),尺寸为(world_size,),表示一维的设备网格。
- 初始化设备网格(
-
-
应用张量并行
-
model.tensor_parallel(device_mesh)- 将模型应用张量并行策略,使用之前创建的设备网格
device_mesh。 - 作用:将模型的参数和计算分布在多个设备(如 GPU)上,以实现并行计算。
- 将模型应用张量并行策略,使用之前创建的设备网格
-
目的
- 实施张量并行:在多 GPU 环境下,将模型的计算划分为多个并行的部分,提高模型训练或推理的效率。
- 确保模型兼容性:在应用张量并行之前,检查模型是否支持该特性,避免不支持的模型引发错误。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









