








CVPR2019论文
论文:ArXiv
代码:GitHub
作者在知乎上的文章:知乎

对于视频目标跟踪(VOT)领域的任务,在第一帧给定BBox,获得后续帧中的BBox
对于视频目标分割(VOS)领域的任务,在第一帧给定Mask,获得后续帧中的Mask
那么对于VOT,能否通过分割的结果获得更准确的BBox信息?对于VOS,能不能只通过初始帧的BBox,利用跟踪得到快速的分割Mask?
所以,作者的主要思想是提出一个统一的框架:①对于跟踪领域,提供分割得到更精确的预测;②对于视频分割领域,提出使用box这种低成本的初始化,用tracking来引导分割的快速vos框架。
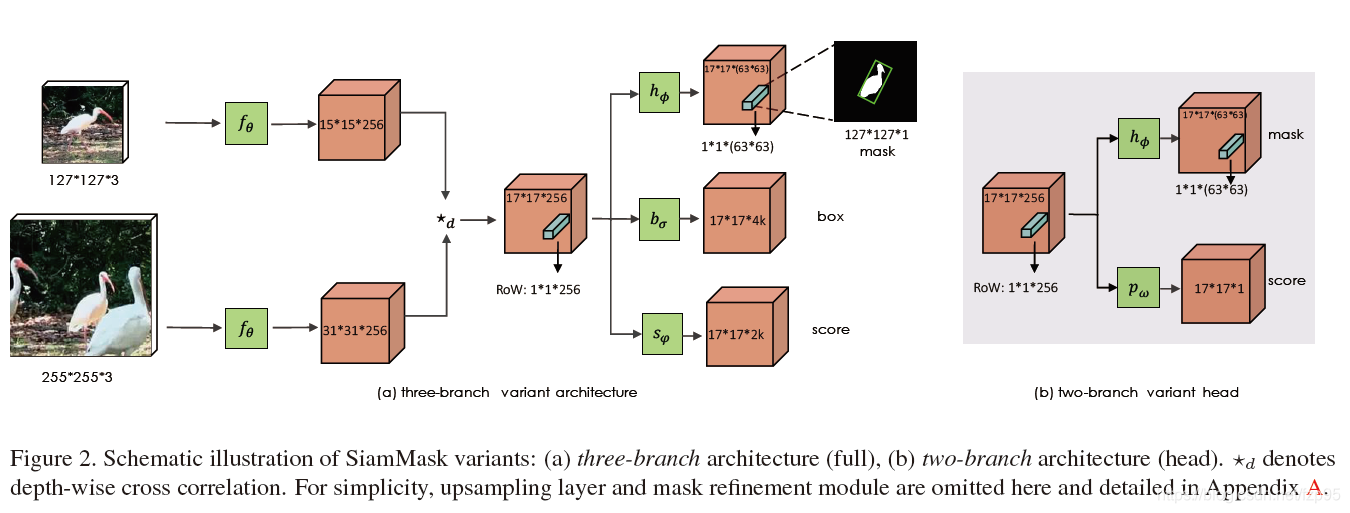
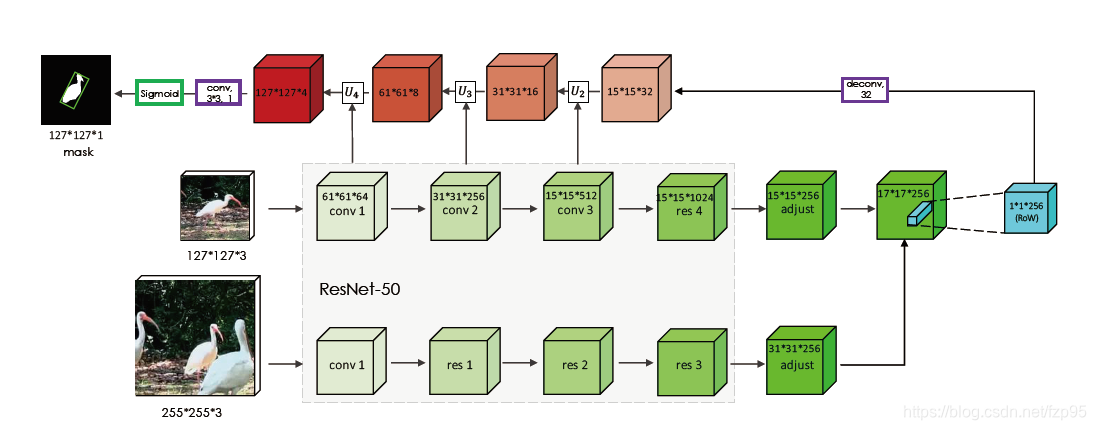
SiamMask框架
在实现上,SiamMask有两种变种:两分支和三分支变种,baseline分别为对SiamFC和SiamRPN。两分支即为在原始的响应图分支外,再加入mask分支,三分支为在原始的得分图和边界框回归分支外,加入mask分支。
再看框架图:在中间互相关后的响应图中,作者对每个位置上的1x1x256称为RoW(response of a candidate window),想要表达的就是,把这个RoW再通过1x1分支编码为一行向量来表示一个mask,产生预测,采用了deepmask的思想。设置成1x1x(63x63)是为了resize到63x63x1然后直接进行上采样到127x127,再通过设置阈值得到最终mask。
按论文中的意思,每个位置的RoW都会产生一个mask,到底选哪个mask是在推断过程中根据score branch来选择的。
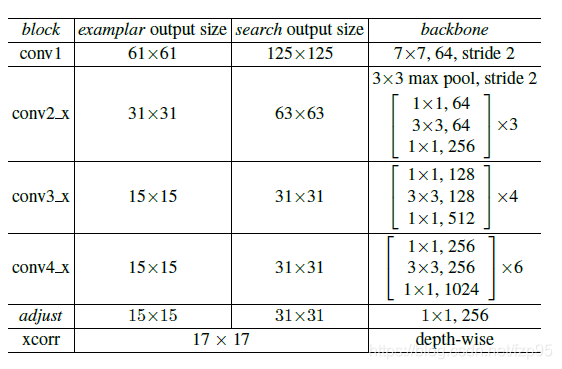
Backbone
前面的主干网络
f
θ
f_{\theta }
fθ为resnet-50的前4个阶段,这部分网络共享参数,输出接不共享参数的1x1卷积来调整通道,
★
d
\bigstar _{d}
★d为depth-wise互相关,因此得分图的通道数还是256。主干网络结构图如下所示:
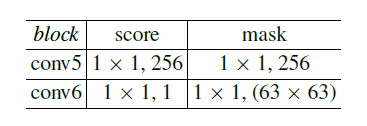
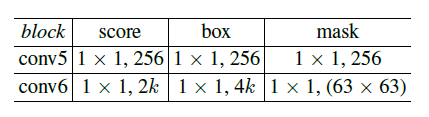
Heads
其中两个变种头部网络的mask分支结构都一样,至于为什么是63x63,作者提到:
设置成63x63x1主要是为了节约计算资源。预测127*127需要1w多的channel。太大了。上采样到127是为了和exemplar一样
其他分支卷积核的设置为了改变通道数,具体作用可详见上面两篇论文。两个变种的卷积具体结构如下:
两分支:
三分支:
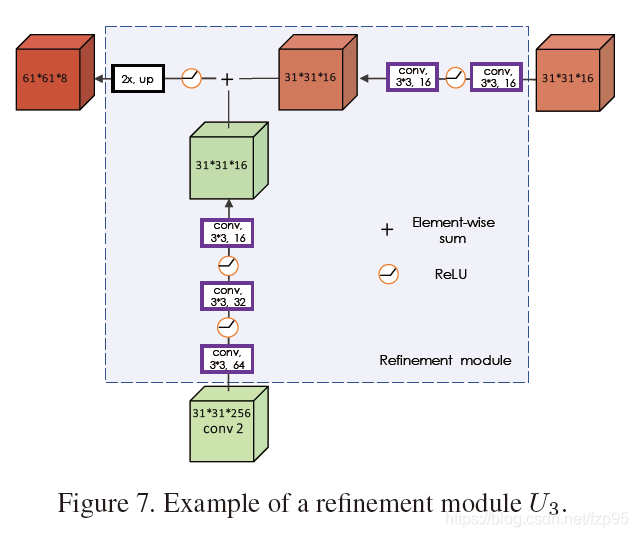
作者提到,直接这样预测mask的方式得到的精度并不太高,所以提出了如下图所示的Refine模块
U
U
U来提升分割的精度:在原始的响应图上对每个RoW不采用升维到63x63的方式,而是直接对RoW进行deconv上采样得到mask。
Refine Module借鉴了SharpMask的思路:
Loss:
mask分支loss:
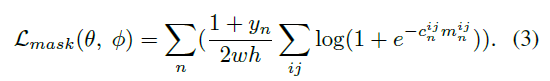
其中
θ
\theta
θ和
ϕ
\phi
ϕ分别是主干网络和mask头网络的权重,
y
n
y_n
yn是第n个RoW的标签,取
±
1
\pm 1
±1,不考虑标签为-1的。
c
n
i
j
c_n^{ij}
cnij为真实mask上第ij位置的标签,总共有
w
h
wh
wh个,对应的
m
n
i
j
m_n^{ij}
mnij就是预测的标签。
总loss:
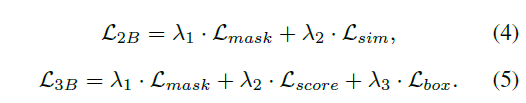
其中
λ
1
=
32
,
λ
2
=
λ
3
=
1
\lambda_1=32,\lambda_2=\lambda_3=1
λ1=32,λ2=λ3=1
实验
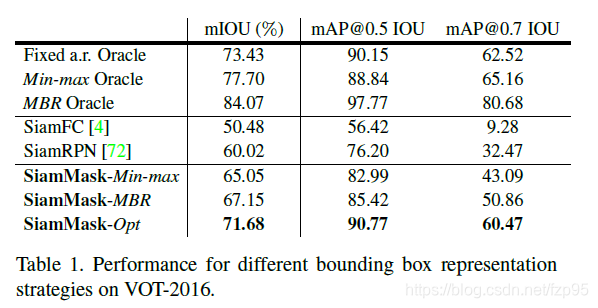
1. 三种根据mask选包围框的策略对跟踪结果的影响
三种策略见下图,具体描述参见文章

这块主要是想通过实验说明,包围框的选择策略对结果影响很大。
考虑到速度的影响,最终算法选择的是MBR的策略选择包围框。
2. 跟踪结果比较

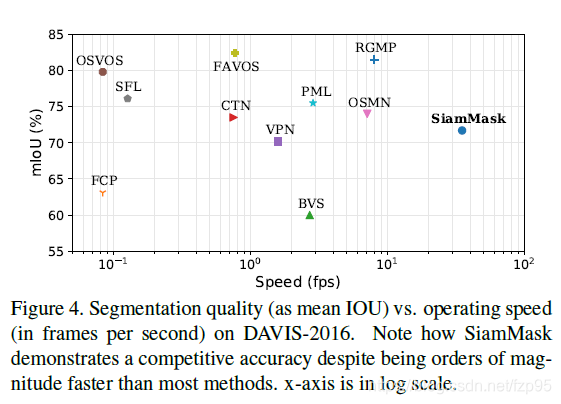
3. 分割结果比较
主要的亮点是保证精度还可以的情况下,速度达到非常快,而且不需要初始mask,只需要初始帧的一个bounding box即可。
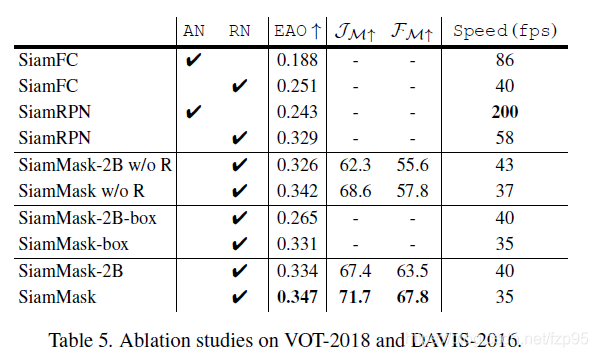
4. Ablation studies
比较了不同的主干网络,有没有采用refine模块,是否采用axis-aligned bounding等做比较。具体描述细节可参见文章
结尾
整篇论文其实就是在介绍一个概念,还是开头那句话,这个思想是最核心的,具体的实现只是图个方便,期待后续更加精确而高效的工作提出来不断拓展跟踪的新方向。















 2275
2275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









