






 本文对自动驾驶技术进行了综述。介绍了其研究背景、意义,指出虽面临诸多难题,但能提升交通安全、效率与环保性。阐述了国内外应用现状,目前主要集中在L2+和L3级别。还从传感器与数据集、模块化和端到端自动驾驶、语言大模型、通信技术等方面介绍了研究现状。
本文对自动驾驶技术进行了综述。介绍了其研究背景、意义,指出虽面临诸多难题,但能提升交通安全、效率与环保性。阐述了国内外应用现状,目前主要集中在L2+和L3级别。还从传感器与数据集、模块化和端到端自动驾驶、语言大模型、通信技术等方面介绍了研究现状。
自动驾驶综述
一、研究背景和意义
自动驾驶技术的崛起标志着交通领域面临的一场深刻变革。在过去的几十年里,随着计算机科学和人工智能的飞速发展,自动驾驶技术得以迅速演进。这一技术的涌现不仅源于计算能力的提升,更受益于传感器技术、机器学习和深度学习等领域的突破。自动驾驶系统通过实时感知和智能决策,为交通运输带来了更高效、更安全、更环保的前景[1]。
当前智能化已成为汽车产业发展的大趋势,而自动驾驶无疑是汽车智能化最重要的核心内涵之一。不过汽车自动驾驶面临技术攻关、成本控制、商业模式、用户接纳、法规限制和伦理挑战等一系列难题,使其有效落地绝非易事。这既给企业带来了巨大挑战,同时也孕育着巨大机遇。对于汽车企业而言,科学认识并准确把握自动驾驶的战略定位、技术路线、推进节奏和发展策略,不仅关系到产品的核心竞争力以及近期的市场表现,而且与企业在智能化时代的转型升级息息相关,将对自身长期的可持续发展产生深远影响[2]。
自动驾驶技术有望显著减少交通事故,提高道路安全性。它能够通过实时感知和快速响应,避免许多由人为驾驶引起的事故,减少交通伤亡;能够通过优化车辆行驶轨迹、实现高效的交叉口控制等方式,提高交通流的效率,减少交通堵塞,缩短行驶时间;同时,有望降低车辆燃油消耗、优化行车路线,从而减少尾气排放,对城市空气质量和环境保护具有积极影响;此外,可以实现更智能的交通流管理,通过实时优化车辆行进策略、调整信号灯配时等手段,提高整体交通系统的运行效率[3]。
二、国内外应用现状
为了规范我国自动驾驶技术发展,由工信部制定的《汽车驾驶自动化分级》(GB/T40429-2021)根据自动化系统承担的角色将驾驶智能分为6级,从第0级(L0)到第5级(L5)智能水平依次递增[4],这些级别描述了车辆在自动驾驶过程中的不同程度的自主性。
L0 (无自动化):驾驶员完全负责车辆的控制,没有任何自动化辅助。
L1 (辅助驾驶):车辆能够执行某些特定的任务,如巡航控制或车道保持,但驾驶员仍需保持监控和控制。
L2 (部分自动化):车辆能够同时执行多个自动化任务,如加速和转向,但驾驶员仍需在必要时介入。
L3 (条件自动化):在特定条件下,车辆可以完全自主执行驾驶任务,但在某些情况下,需要驾驶员介入。驾驶员可以放松,但需要随时准备接管控制。
L4 (高度自动化):车辆在特定环境或情境中可以完全自主执行驾驶任务,而无需驾驶员介入。驾驶员只需要在系统要求时介入,但大部分时间车辆是自主的。
L5 (全自动化):完全无需驾驶员介入,车辆在所有条件下都能够执行驾驶任务。车辆能够适应各种环境和情境,不需要人类驾驶员。
目前,实际应用中的自动驾驶技术主要集中在L2+和L3级别,而更高级别的自动驾驶技术仍在研发和测试阶段。
美国是全球自动驾驶技术的领先者之一。硅谷的一些科技巨头如谷歌母公司Alphabet旗下的Waymo、特斯拉等在自动驾驶领域投入巨大研发力量。欧洲也有多家公司和研究机构投入自动驾驶技术的研究,包括德国的大众、奔驰等,法国的雷诺等。日本的汽车制造商如丰田、本田等也在自动驾驶领域进行研发。日本政府也在支持自动驾驶技术的发展。在国内,如百度、蔚来、小米、华为等,都在自动驾驶领域进行研发。百度的Apollo项目是国内最为知名的自动驾驶研究项目之一,同时,国内的高校和研究机构也积极参与自动驾驶技术的研究。
目前已经量产的自动驾驶L3级别的车型:本田Legend Hybrid EX、奔驰S级、奥迪的A8L、55、TFSI等车型、特斯拉Model S、Model X、Model 3、Model Y等车型、凯迪拉克CT6、广汽Aion V、此外,小鹏P7、长安UNI-T、宝马iNEXT,也宣称可以实现L3级别的自动驾驶功能,但是目前还没有正式量产。L3级别的公司有特斯拉、蔚来汽车、极狐汽车(与华为合作)、奥迪(海外版)、奔驰(海外版)等。同时,宝马拿下国内首张L3测试牌照,12月14日,宝马集团宣布,搭载L3级别自动驾驶功能的车辆,在上海市正式获得高快速路自动驾驶测试牌照。
三、研究现状
从算法实现上,可以分为两大类,一类是通过将各个部分模块化来实现,另一类是直接通过端到端的实现。模块化自动驾驶系统的特点是按顺序排列的模块化任务,即感知、预测和规划。端到端这种方式直接将整个自动驾驶任务建模为一个端到端的神经网络。这个网络接收原始传感器数据,并输出控制指令。
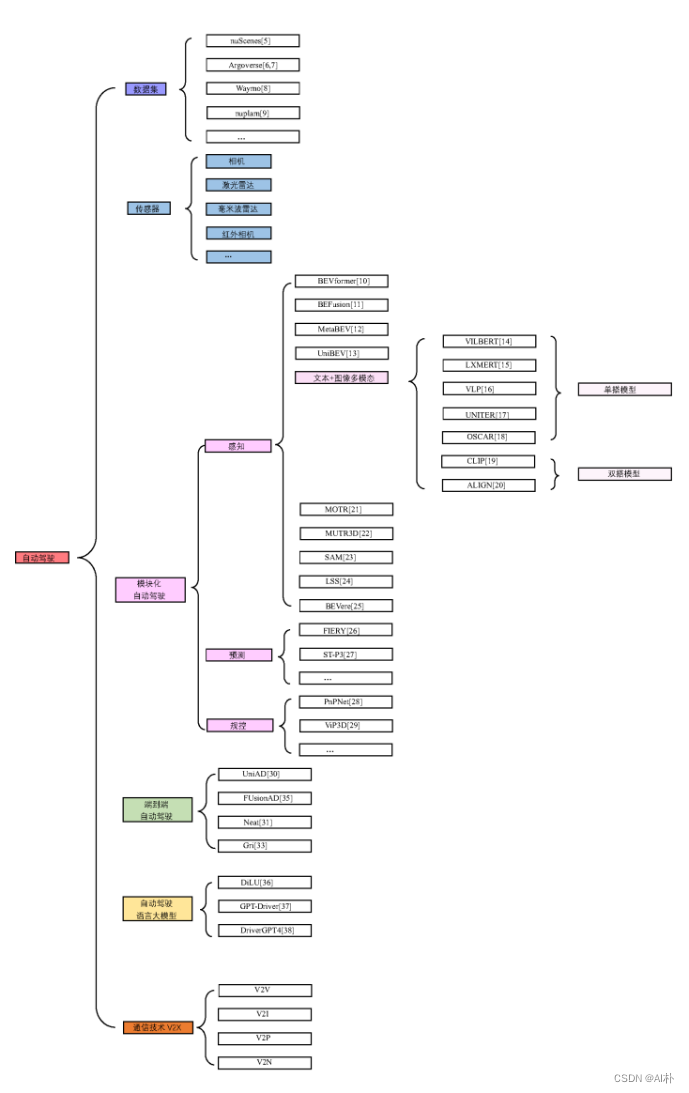
3.1传感器与数据集
自动驾驶公开数据集规模也不断扩大,包括nuScenes[5]、Argoverse[6, 7]、Waymo[8]和nuPlan[9]。NuScenes[5]数据集由nuTonomy公司创建,为了促进自动驾驶领域的研究和发展。它提供了大量的高分辨率传感器数据,包括激光雷达、摄像头、雷达等。这些数据涵盖了城市环境中的各种交通场景。NuScenes数据集包含多种传感器数据,其中包括32线激光雷达(LIDAR)、六个摄像头、雷达和惯性测量单元(IMU)。数据集涵盖了多样化的场景,包括城市街道、高速公路、天气变化等情况。提供API以便用户能够方便地访问数据,并有助于在数据上进行研究和实验。Argoverse[6, 7]是由Argo AI创建的数据集,包括激光雷达、摄像头、GPS和IMU等传感器,涵盖城市环境中的各种交通场景,具有高度的场景多样性,提供了高分辨率地图和预测轨迹的信息。Waymo[8]是谷歌(Alphabet旗下的子公司)的自动驾驶部门创建的数据集, 包括激光雷达、摄像头、雷达和其他传感器,提供了在城市和高速公路等不同场景中收集的数据,Waymo数据集具有大规模、高质量的特点,数据集中涵盖了大量的真实世界交通情况。nuPlan[9]是世界第一个针对自动驾驶规划方法测试的开源数据集,收集了波士顿、匹兹堡、拉斯维加斯和新加坡这4个城市收集了大约1300 小时的驾驶数据。
3.2模块化自动驾驶
在感知方面,感知算法向BEV+transformer架构升级,助力城市领航辅助驾驶脱高精度地图。包括传感器的创新,如单目相机到多目相机、加入毫米波和激光雷达等;多模态数据的融合包括以BEVFormer[10]为代表的在BEV空间进行多视角相机数据融合以及BEVFusion[11]、MetaBEV[12]、UniBEV[13]为代表的相机数据与激光雷达点云数据在BEV空间中融合。
BEVFormer[10]通过提取环视相机采集到的图像特征,并将提取的环视特征通过模型学习的方式转换到BEV空间(模型去学习如何将特征从 图像坐标系转换到 BEV 坐标系),从而实现 3D 目标检测和地图分割任务,通过预定义的网格形BEV查询与空间和时间空间交互,从而利用空间和时间信息。BEVFormer[10]为了聚合空间信息,设计了空间交叉注意,即每个BEV查询从跨摄像机视图的感兴趣区域中提取空间特征。对于时间信息,提出了时间自我注意来周期性地融合历史BEV信息。在低能见度条件下,显著提高了物体的速度估计和召回的精度。
BEVFusion[11]、MetaBEV[12]、UniBEV[13]都是激光雷达点云数据和多视角相机数据的融合。其中BEVFusion[11]融合了来自激光雷达和相机的多模态BEV特征。但是,从这两个来源提取这些特征的方法存在差异,可能导致camera和激光雷达BEV特征之间的不对齐;MetaBEV[12] 优化了BEVFusion[11],采用了一个包含多个可变形注意层的模块来更好地对齐特征,尽管并没有完全解决底层特征的不对齐问题。UniBEV[13]的新颖之处在于其从不同传感器统一提取BEV特征的方法,确保了特征的良好对齐,从其具有统一的BEV编码器的原始坐标系中提取多模态的BEV特征,并将BEV特征通过通道归一化权重策略融合。
同时,图像与文本的跨模态融合也是感知的关键一环。在图像与文本的多模态算法方面,单塔模型如VILBERT [14]、LXMERT [15]、VLP [16]、UNITER [17]和Oscar [18]在图像和文本的联合学习中表现出色。VILBERT[14]和LXMERT[15]通过引入注意力机制实现了图像和文本的联合训练,从而促进了二者之间的信息交流。VLP[16]通过在多个任务上进行预训练,包括图像标注和视觉问答等,取得了良好的效果。UNITER[17]作为通用的图像-文本表示模型,通过跨模态对抗训练实现了图像和文本的联合训练。Oscar[18]通过在大规模的图像标注和文本语料库上进行预训练,在多模态任务上表现出卓越性能。图像+文本"的多模态算法,单塔模型有VILBERT [14], LXMERT [15], VLP [16], UNITER [17], Oscar [18],
其中VILBERT(Visual-Linguistic BERT)[14]是一个基于BERT的模型,通过联合训练图像和自然语言,实现对图像和文本的理解。使用注意力机制,同时处理图像和文本,促进二者之间的信息交流。LXMERT(Language-visual model for reasoning)[15]是一个联合学习图像和文本的模型,特别适用于视觉问答等任务。融合了图像和文本特征,通过多任务学习提高模型的性能。VLP(Visual-Language Pre-training)[16]通过联合学习图像和文本,预训练模型以适应多个视觉-语言任务。通过预训练在多个任务上取得了很好的效果,包括图像标注、视觉问答等。UNITER(UNiversal Image-TExt Representation)[17]是一个通用的图像-文本表示模型,可以用于多种下游任务。使用跨模态对抗训练(CMAD)来联合训练图像和文本表示。Oscar[18]是利用海量数据进行预训练,以提高在多模态任务上的性能。一个图像和文本的跨模态预训练模型,通过大规模的图像标注和文本语料库进行预训练。
双塔模型算法,比如CLIP [19]和ALIGN [20],CLIP(Contrastive Language-Image Pre-training)是由OpenAI提出的双塔模型,通过对比学习图像和文本的表示。通过对比学习建立图像和文本的对应关系,从而实现泛化到多种任务的能力。ALIGN[20]是一种多模态模型,旨在通过对齐图像和文本的表示来提高性能。采用对齐机制,使得图像和文本的表示在共同嵌入空间中更加相似,有助于跨模态任务的处理。
自动驾驶的目标追踪和检测MOTR[21]、MUTR3D[22]。MOTR[23]是一个真正的完全端到端的跟踪框架。它能够学习建模目标的长程时间变化,隐式地进行时间关联,并避免了以前的显式启发式策略。基于Transformer和DETR,MOTR[23]引入了track query这个概念,一个track query负责建模一个目标的整个轨迹,它可以在帧间传输并更新从而无缝完成目标检测和跟踪任务。时间聚合网络(temporal aggregation network,TAN)配合多帧训练被用来建模长程时间关系。
MUTR3D[22]是第一个完全端到端的多相机3D跟踪框架。与现有的使用显式跟踪试探法的检测跟踪方法不同,MUTR3D[22]隐式地模拟了目标轨迹的位置和外观变化。此外,MUTR3D[22]通过消除常用的后处理步骤,如非最大值抑制、边界框关联和Re-ID,简化了3D跟踪流程。
在分割算法中,随着SAM(Segment Anything)[23]的爆火,其也成为加入自动驾驶模块的热门趋势。SAM[23] 基于对自然语言处理 (NLP) 产生重大影响的基础模型。 它专注于可提示的分割任务,使用提示工程来适应不同的下游分割问题。该模型支持多种提示类型,具有零样本泛化能力。将SAM[23]加入自动驾驶感知模块是一种新的尝试,同时对于自动驾驶数据集的辅助标注也可推进自动驾驶技术的发展。
构建实时地图算法LSS[24]、BEVerse[25]等。LSS的方法提供了一个很好的融合到BEV视角下的方法。基于此方法,无论是动态目标检测,还是静态的道路结构认知,甚至是红绿灯检测,前车转向灯检测等等信息,都可以使用此方法提取到BEV特征下进行输出,极大地提高了自动驾驶感知框架的集成度。BEVerse[25]首先执行共享特征提取和提升(lifting),从多时间戳和多视图图像生成4D BEV表征。在自运动补偿之后,利用时空编码器进一步提取BEV特征。最后,加上多个任务解码器进行联合推理和预测。在解码器中,提出栅格采样器(grid sampler)来生成对不同任务支持不同范围和粒度的BEV特征。此外,还设计一个迭代流(iterative flow)方法,实现内存高效的未来预测。
在预测方面,算法有FIERY[26],ST-P3[27]等。FIERY[27]是一种单目摄像头中BEV未来概率预测模型。 其预测动态智体的未来实例分割和运动,转换为非参数未来轨迹。 结合传统自动驾驶栈的感知、融合和预测组件,直接从RGB 单目相机输入估计BEV预测。ST-P3[27], 一个基于视觉的可解释的端到端系统,该系统可以改善感知、预测和规划的特征学习,多个时刻下的环视相机图像会依次经过感知、预测、规划模块,输出最终的规划路径,感知和预测模块的特征输出,可以经过解码器得到不同类型的场景语义信息,增强可解释性,还通过每个模块中特殊的设计来增强时空特征的学习。
在规划控制方面,算法有PnPNet[28]、ViP3D[29]等。PnPNet[28]是将感知和预测任务与目标跟踪结合起来,形成一个端到端的系统。它将序列传感器数据作为输入,并输出每个时间步长的对象轨迹及其未来轨迹。关键组件是一个新的跟踪模块,它从检测中在线生成对象跟踪,并利用轨迹水平特征进行运动预测。提高了自动驾驶对环境的全面理解和对未来场景的预测。ViP3D[29]一种视觉轨迹预测流水线,利用原始视频的丰富信息预测场景中智体的未来轨迹。ViP3D[29]在整个流水线中使用稀疏智体query,使其完全可微分和可解释。此外,提出一种新的端到端视觉轨迹预测任务的评估指标,端到端预测精度,其在综合考虑感知和预测精度的同时,对预测轨迹与地面真实轨迹进行评分。
3.3端到端自动驾驶
同时,UniAD[30]的发表为自动驾驶提出了一条新路径,即端到端自动驾驶[27,31,32,33,34],UniAD[30]集成了感知、预测和规划等关键任务,并将这些任务整合到一个基于 Transformer 的端到端网络框架中。它通过深度学习允许各个子任务共享特征,并且可以优化每个子任务以执行安全的规划。这个框架是业界首个将全栈关键任务整合到一个深度神经网络中的自动驾驶模型。相较于UniAD[30],UniAD[30]只使用了相机多视角数据融合,FusionAD[35]在传感器使用了激光雷达和相机多模态数据融合,FusionAD[35],这是第一个统一的基于BEV多模态、多任务端到端学习框架,专注于自动驾驶的预测和规划任务。首先,我们设计了一个简单而有效的transformer架构,将多模态信息融合到一个transformer中,以在BEV空间中产生统一的特征。
3.4自动驾驶语言大模型
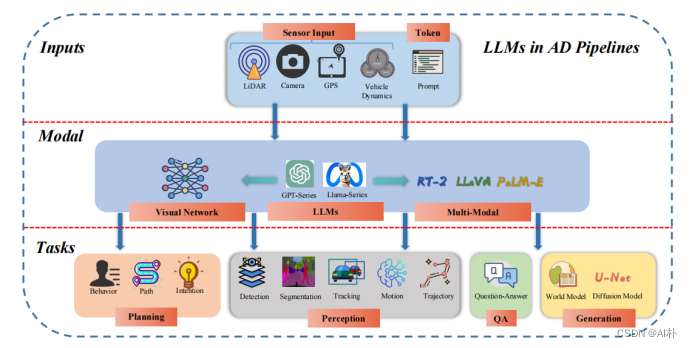
随着语言大模型的爆火,自动驾驶语言大模型也成为最新的研究方向,如DiLu[36]、GPT-Driver[37]、DriveGPT4[38]等也取得成效。DiLu[36]框架,它结合了推理和反思模块,使系统能够基于常识知识做出决策并不断演化。DiLu[36]能够积累经验,并在泛化能力上明显优于基于强化学习的方法。此外,DiLu[36]能够直接从现实世界的数据集中获取经验,突显了其在实际自动驾驶系统上的潜力。GPT-Driver[37]可以将OpenAI GPT-3.5模型转化为可靠的自动驾驶车辆运动规划器。GPT-Driver[37]将规划器的输入和输出表示为语言标记,并利用LLM通过坐标位置的语言描述生成驾驶轨迹。提出了一种新颖的提示-推理-微调策略,以激发LLM的数值推理潜力。借助这一策略,LLM可以用自然语言描述高度精确的轨迹坐标,以及其内部的决策过程。DriveGPT4[38]是一个使用LLM的可解释的端到端自动驾驶系统,能够解释车辆行为并提供相应的推理,还可以回答用户提出的各种问题,以增强互动性。此外,DriveGPT4[38]以端到端的方式预测车辆的低级控制信号。
3.5通信技术
在自动驾驶中,通信技术也决定着自动驾驶的智能化进展。车联万物(Vehicle-to-Everything,V2X)[39,40,41,42],是指车辆与一切事物之间的通信技术。这种通信技术旨在通过车辆与周围的基础设施、其他车辆、行人以及云端系统之间的实时信息交流,提高交通安全性、效率和智能性。V2X技术是自动驾驶和智能交通系统中的重要组成部分。车与车(Vehicle-to-Vehicle,V2V)、车与路端单元(Vehicle-to-Infrastructure,V2I)、车与人(Vehicle-to-Pedestrian,V2P)以及车与网络(Vehicleto-Network,V2N)间的数据交互。
四、结论和展望
自动驾驶技术的研究现状呈现出多样化和快速发展的趋势。从算法实现的角度,研究者们采用了模块化自动驾驶系统和端到端两大类方法,各自在感知、预测、规划等任务中进行深入探索。同时,自动驾驶语言大模型广泛应用于自动驾驶的决策制定、规划路径、甚至对于互动性的增强。它们有望解决复杂场景下的决策问题,并提供对系统内部决策过程的可解释性。
挑战:随着自动驾驶技术的不断发展,仍然存在一系列挑战,包括对于复杂交通场景的适应性、数据隐私和安全性、法规和标准等。
展望:研究者们期望通过不断创新,解决技术和法规挑战,推动自动驾驶技术更广泛、更安全、更普及的应用。自动驾驶技术有望成为未来交通领域的重要变革推动力。
五、参考文献
[1]李克强,戴一凡,李升波等.智能网联汽车(ICV)技术的发展现状及趋势[J].汽车安全与节能学报,2017,8(01):1-14.
[2]赵福全,刘宗巍,刘兆鹏等.自动驾驶技术发展关键问题辨析与实施策略建议[J].智能网联汽车,2023(05):15-26.
[3]本报编辑部. 自动驾驶安全技术与应用场景并进[N]. 中国计算机报,2023-12-11(003).DOI:10.28468/n.cnki.njsjb.2023.000224.
[4]中华人民共和国工业和信息化部.GB/T 40429-2021汽车驾驶自动化分级[S].北京:国家标准化管理委员会,2021.
[5]H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong,Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom,“nuscenes: A multimodal dataset for autonomous driving,” in CVPR, 2020.
[6]M. Chang, J. Lambert, P. Sangkloy, J. Singh, S. Bak,A. Hartnett, D. Wang, P. Carr, S. Lucey,
[7]D. Ramanan, andJ. Hays, “Argoverse: 3d tracking and forecasting with richmaps,” in CVPR, 2019.
[8]B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh,S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. K.Pontes, D. Ramanan, P. Carr, and J. Hays, “Argoverse 2:Next generation datasets for self-driving perception and forecasting,” in NeurIPS, 2021.
[9]P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine, V. Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y. Zhang, J. Shlens,Z. Chen, and D. Anguelov, “Scalability in perception for autonomous driving: Waymo open dataset,” in CVPR,2020.
[10]H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. Wolff,A. Lang, L. Fletcher, O. Beijbom, and S.Omari, “Nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles,” in CVPR Workshops, 2021.
[11]Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. BEVFormer:Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In ECCV, 2022.
[12]T. Liang, H. Xie, K. Yu, Z. Xia, Z. Lin, Y. Wang, T. Tang, B. Wang,and Z. Tang, “BEVFusion: A simple and robust lidar-camera fusion framework,” in NeurIPS, 2022
[13]C. Ge, J. Chen, E. Xie, Z. Wang, L. Hong, H. Lu, Z. Li, and P. Luo, “MetaBEV: Solving sensor failures for bev detection and map segmentation,” arXiv preprint arXiv:2304.09801, 2023.
[14]Shiming Wang, Holger Caesar, Liangliang Nan, Julian F. P. Kooij. UniBEV: Multi-modal 3D Object Detection with Uniform BEV Encoders for Robustness against Missing Sensor Modalities. arXiv:2309.14516
[15]VILBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In NeurIPS, 2019.
[16]LXMERT: Learning cross-modality encoder representations from transformers. In EMNLP, 2019.
[17]Unified vision-language pre-training for image captioning and vqa. In AAAI, 2020.
[18]UNITER: Universal image-text representation learning. In ECCV, 2020.
[19]OSCAR: Object-semantics aligned pre-training for vision-language tasks. In ECCV, 2020.
[20]Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
[21]Scaling up visual and vision-language representation learning with noisy text supervision. In ICML, 2021.
[22]Fangao Zeng, Bin Dong, Tiancai Wang, Xiangyu Zhang, and Yichen Wei. Motr: End-to-end multiple-object tracking with transformer. In ECCV, 2021.
[23]Tianyuan Zhang, Xuanyao Chen, Yue Wang, Yilun Wang,and Hang Zhao. MUTR3D: A Multi-camera Tracking Framework via 3D-to-2D Queries. In CVPR Workshop,2022.
[24]A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson,T. Xiao, S. Whitehead, A. C.Berg, W.-Y. Lo et al., “Segment anything,” arXiv preprint arXiv:2304.02643, 2023.
[25]Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In ECCV, 2020.
[26]Yunpeng Zhang, Zheng Zhu, Wenzhao Zheng, Junjie Huang, Guan Huang, Jie Zhou, and Jiwen Lu. BEVerse: Unified perception and prediction in birds-eye-view for vision-centric autonomous driving. arXiv preprint arXiv:2205.09743, 2022.
[27]Anthony Hu, Zak Murez, Nikhil Mohan, Sof´ıa Dudas, Jeffrey Hawke, Vijay Badrinarayanan, Roberto Cipolla, and Alex Kendall. FIERY: Future instance prediction in bird’seye view from surround monocular cameras. In ICCV, 2021.
[28]S. Hu, L. Chen, P. Wu, H. Li, J. Yan, and D. Tao, “St-p3: End-to-end vision-based autonomous driving via spatialtemporal feature learning,” in ECCV, 2022.
[29]Ming Liang, Bin Yang, Wenyuan Zeng, Yun Chen, Rui Hu,Sergio Casas, and Raquel Urtasun. Pnpnet: End-to-end perception and prediction with tracking in the loop. In CVPR, 2020.
[30]Junru Gu, Chenxu Hu, Tianyuan Zhang, Xuanyao Chen, Yilun Wang, Yue Wang, and Hang Zhao. ViP3D: End-toend visual trajectory prediction via 3d agent queries. In CVPR, 2023.
[31]Y. Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai,S. Du, T. Lin, W. Wang, L. Lu, X. Jia, Q. Liu, J.Dai, Y. Qiao,and H. Li, “Planning-oriented autonomous driving,” in CVPR, 2023.
[32]K. Chitta, A. Prakash, and A. Geiger, “Neat: Neural attention fields for end-to-end autonomous driving,” in ICCV, 2021.
[33]J. Hawke, R. Shen, C. Gurau, S. Sharma, D. Reda, N. Nikolov, P. Mazur, S. Micklethwaite, N. Griffiths,A. Shah, et al., “Urban driving with conditional imitation learning,” in ICRA, 2020.
[34]R. Chekroun, M. Toromanoff, S. Hornauer, and F. Moutarde, “Gri: General reinforced imitation and its application to vision-based autonomous driving,” arXiv.org, vol. 2111.08575, 2021.
[35]L. Feng, Q. Li, Z. Peng, S. Tan, and B. Zhou, “Trafficgen: Learning to generate diverse and realistic traffic scenarios,” in ICRA, 2023.
[36]Tengju Ye, Wei Jing, Chunyong Hu, Shikun Huang, Lingping Gao, Fangzhen Li, Jingke Wang, Ke Guo, Wencong Xiao, Weibo Mao, Hang Zheng, Kun Li, Junbo Chen, Kaicheng Yu.FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving. arXiv:2308.01006
[37]Licheng Wen, Daocheng Fu, Xin Li, Xinyu Cai, Tao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, and Yu Qiao. Dilu: A knowledge-driven approach to autonomous driving with large language models. arXiv preprint arXiv:2309.16292, 2023.
[38]Jiageng Mao, Yuxi Qian, Hang Zhao, and Yue Wang. Gpt-driver: Learning to drive with gpt. arXiv preprint arXiv:2310.01415, 2023.
[39]Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee. K. Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model, 2023.
[40]谭伟杰,杨雨婷,牛坤等.基于MI-PUF的V2X车联网通信安全认证协议[J].信息网络安全,2023,23(12):38-48.
[41]吴冬升,曾少旭,邝文华等.国际V2X业务应用场景分析[J].智能网联汽车,2023(06):23-26.
[42]翟硕,钱本华,王睿等. 车联网技术的发展与应用综述[C]//中国科学技术大学,中国自动化学会系统仿真专业委员会,中国仿真学会仿真技术应用专业委员会.第24届中国系统仿真技术及其应用学术年会(CCSSTA24th 2023)论文集.2023.
[43]Donglin Wang, Yann Nana Nganso, Hans D. Schotten. A Short Overview of 6G V2X Communication Standards.In IEEE ICN 2023.

















 2550
2550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









