







引言
Transformer技术在自然语言处理领域取得突破,催生了BERT、GPT和T5等模型。它在计算机视觉中也显示出潜力,尤其在自动驾驶领域,Transformer在物体检测、车道检测和分割等关键任务中替代了传统CNN和RNN,与强化学习结合用于路径规划。其自注意力机制增强了对动态环境的理解,对自动驾驶车辆的导航安全至关重要。
探索Transform:结构和功能见解
1、 Transform架构:结构概述
Transform架构是一项突破性创新,通过利用注意力机制进行序列处理,标志着从传统循环层的转变。它由两个主要部分组成:编码器和解码器。编码器通过多头注意力和前馈网络处理输入嵌入,两者都通过层规范化和残差连接得到增强。解码器结构与编码器相似,也聚焦于编码器输出,生成最终的输出序列。位置编码在此架构中至关重要,因为它们使模型能够识别序列顺序,这一关键特性是Transform本身无法辨别词序的。此功能对于把握语言上下文至关重要,使得位置编码成为Transform设计的基本组成部分。在接下来的内容中,我们将详细描述Transform的各个组成部分。
2、 自注意力机制:Transform的核心
Transform模型的核心是自注意力机制(图1),它评估输入序列各个部分之间的关系。在这一过程中,每个输入元素被转换为三个向量:查询(q)、键(k)和值(v),通常维度为d = 512,并编成矩阵Q、K和V。然后,注意力函数通过查询和键的点积计算交互分数,并通过除以√d来稳定训练。这些分数通过softmax函数转换为概率,指示每个元素应受到的关注程度。最终输出(Y)计算为:
Y = softmax( Q · KT / √d ) V.
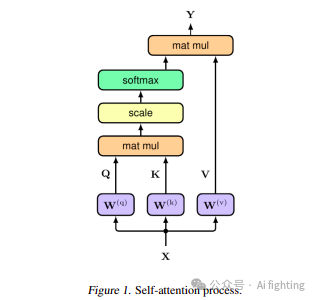
这是值向量的加权和,概括了整个序列的上下文。此外,编码器-解码器注意力机制使解码器能够根据其当前状态和编码器输出专注于输入序列的相关部分。此机制与位置编码结合,确保对序列排序有全面理解。
3、 多头注意力:增强维度分析
多头注意力机制(图2)增强了分析输入数据各个维度的能力。最初,将输入向量划分为每个头的三个不同集合:查询集合Q’、键集合K’和值集合V’,每个子集的维度为d/h。当d为512时,每个集合由较小的向量组成——具体来说,每个集合有h个向量,每个向量的维度为64。这些向量然后组合成矩阵Q’、K’和V’,以进行随后的注意力计算。多头注意力过程公式化如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2883
2883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









