







前言
自动驾驶系统的开发是一个技术与哲学的双重挑战,核心在于模拟人类的直觉推理和常识。尽管机器学习在模式识别上取得了进展,但在复杂情境下仍存在局限。人类决策基于感官感知,但能预见行动结果和预判变化,这是机器难以复制的。
世界模型是解决这一差距的关键,它模仿人类的感知和决策,使系统能预测和适应环境。这一概念从70年代的控制理论发展而来,与模型预测控制(MPC)紧密相关,并受到心理模型理论的支持。神经网络的发展,尤其是循环神经网络(RNN),为动态系统建模提供了新深度,促进了对环境交互的理解。
2018年,Ha和Schmidhuber提出世界模型,使用混合密度网络和RNN提取环境数据模式,标志着自动系统对其操作环境理解的突破。在自动驾驶领域,世界模型的引入是向数据驱动智能的转变,解决了数据稀缺问题,增强了模拟环境中训练的能力,预示着自动驾驶汽车将具备更复杂的预测和响应能力。
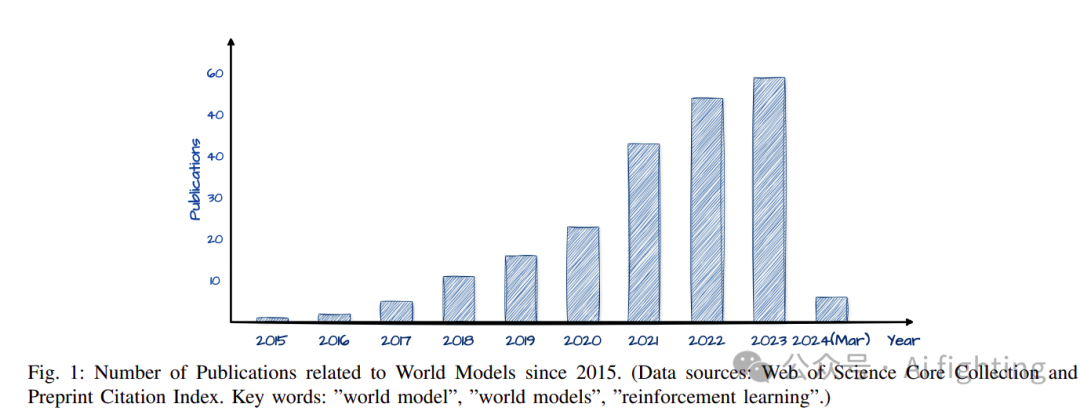
在自动驾驶领域,世界模型的引入标志着向数据驱动智能的关键转变,在这种智能中,预测和模拟未来情景的能力成为安全和效率的基石。数据稀缺性问题,特别是在如鸟瞰图(BEV)标注等专业任务中,突显了世界模型等创新解决方案的实际必要性。通过从历史数据中生成预测情景,这些模型不仅规避了数据收集和标注带来的限制,还增强了在模拟环境中训练自动系统的能力,这些环境可以反映甚至超越现实世界条件的复杂性。这种方法预示着一个新时代的到来,在这个时代,自动驾驶汽车具备反映某种直觉的预测能力,使它们能够以前所未有的复杂程度导航和响应其环境。
欢迎加入自动驾驶实战群

世界模型的发展
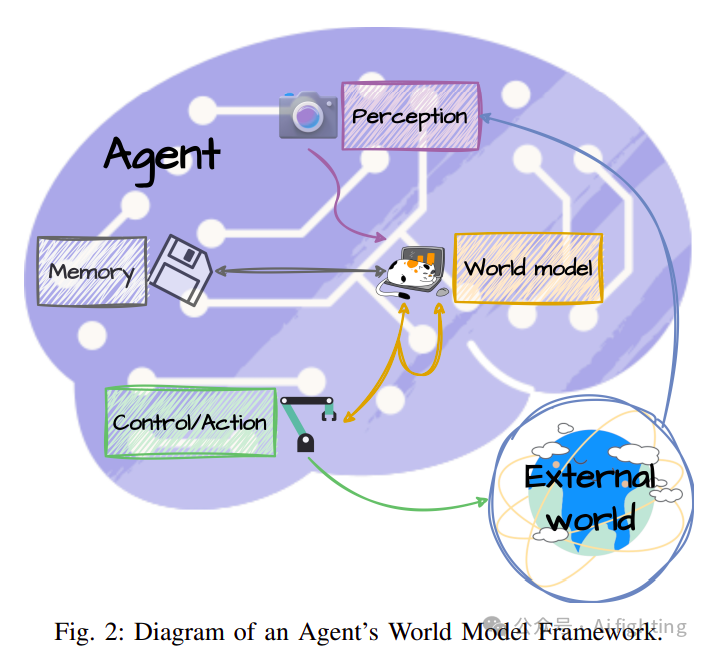
世界模型的架构是一个复杂的系统,它尝试模仿人类大脑在认知和决策方面的功能。
世界模型的架构基础:
-
感知模块:作为系统的感官输入,使用如变分自动编码器(VAE)、掩码自动编码器(MAE)和离散自动编码器(DAE)等先进技术,将复杂的环境输入转化为易于处理的格式。这个模块对于准确捕捉环境特征至关重要。
-
记忆模块:类似于人类的海马体,负责记录和存储信息,包括短期和长期记忆。它通过重放经历来加强学习,并将过去的经验应用于未来的决策中,从而加深对环境动态的理解。
-
控制/行动模块:负责与环境的互动,评估当前状态和预测,以确定实现目标的最佳行动。这个模块的独立训练允许使用不同的策略,如进化策略,来解决复杂的强化学习问题。
-
世界模型模块:作为系统的核心,负责估计当前状态的缺失信息和预测未来状态。它通过模拟潜在的未来场景,使系统能够主动准备和调整策略,体现了人类认知中的预测和适应性思维。
世界模型的应用:
-
在处理高维感官输入时,世界模型利用潜在动态模型来抽象表示观测信息,允许在潜在状态空间内进行紧凑的前向预测。这种方法利用深度学习和潜在变量模型的进步,实现高效的并行预测。
-
世界模型通过潜在变量来表示不确定性,这在处理真实世界动态的不可预测性时尤为重要。例如,在汽车在交叉路口的不确定性场景中,潜在变量帮助模型设想基于当前状态的各种未来可能性。
-
世界模型需要在预测的确定性与真实世界现象的固有不确定性之间找到平衡。这种平衡对于模型在复杂环境中的有效性至关重要,确保了模型能够灵活应对各种情况。
这个任
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









