







 本文提出Detector-in-Detector网络(DID-Net)提高多层次物体检测性能。该网络含BodyDetector和PartsDetector,以端到端方式训练。还收集标记了“human - parts”数据集。实验表明,DID-Net在人体、人脸和手部检测上效果良好,优于传统方法。
本文提出Detector-in-Detector网络(DID-Net)提高多层次物体检测性能。该网络含BodyDetector和PartsDetector,以端到端方式训练。还收集标记了“human - parts”数据集。实验表明,DID-Net在人体、人脸和手部检测上效果良好,优于传统方法。
Detector-in-Detector: Multi-Level Analysis for Human-Parts解读
论文链接:https://arxiv.org/pdf/1902.07017.pdf
论文代码:https://github.com/svjack/Detector-in-Detector;https://github.com/xiaojie1017/Human-Parts
论文出处:ACCV2018
摘要
- 近年来,随着深度卷积神经网络(CNN)的发展,基于视觉的人、手或脸检测方法取得了难以置信的成功。
- 在本文中,我们考虑了身体和身体部位之间的内在相关性,提出了一种新的框架来提高多层次物体的检测性能。
- 特别地,我们采用基于区域的物体检测结构,通过两个精心设计的检测器,分别以由粗到细的方式关注人体和身体部位,我们称之为Detector-in-Detector网络(DID-Net)。
- 第一个探测器被设计用来检测人体、手和脸。
- 第二种检测器在第一种检测器的身体检测结果的基础上,主要对每个身体内部的小尺度手和脸进行检测。
- 该框架通过优化 multi-task loss以端到端方式进行训练。
- 针对人体、人脸和手部检测数据集的不足,我们收集并标记了一个新的大型数据集“human - parts”,包含14,962张图像和106,879个注释。
- 实验结果表明,该方法对人体零件具有良好的检测效果。
1. 简介
- 人的部分是多层次的对象,其中脸和手是身体的子对象。
- 大多数检测框架在解决多层次对象检测问题时,忽略了多层次对象之间的内在相关性,将这些sub-objects和objects粗略地视为普通对象。
- 当使用通用的检测算法进行这种多层次的对象任务时,对于大型对象(如人体)的检测性能相对简单。在现实世界的应用中,关键的挑战主要来自于训练检测器,以识别像脸和手这样的小物体,因为它们的姿势变化很大,而且遮挡严重,这使得它们距离达到和人类一样的检测能力还很远。
- 在训练过程中,背景信息比小目标多,在进行小目标检测时产生了严重的干扰。
- 受到基于自上而下的姿态估计方法启发,这种方法首先从图像中定位和裁剪所有人,然后解决裁剪人中的单个人姿态估计问题。我们提出了一个基于区域的卷积神经网络,称为Detector-in-Detector Network (DID-Net),它允许网络首先看到图片中的身体,然后查看这些身体内部,找到微小的脸和手。
- 我们的网络包含两个基于区域的检测器:BodyDetector和PartsDetector。
- BodyDetector采用传统的Faster R-CNN实现预测一组人体边界框。
- 然后对检测到的人体特征图进行包装,然后发送到基于区域的PartsDetector中,预测手和脸的边界框。在PartsDetector中,许多对训练无用的背景区域被砍掉。因此,cropped body特征内部扰动较小,有利于小零件的检测。整个网络以端到端的方式进行训练。
- 我们构造了一个新的Human-Parts数据集,它包含14,962张人的身体,脸和手在现实的不受约束的条件下标记良好的图片。
- 据我们所知,这是第一个结合了人类三个重要部分的检测数据集。
2. Related work
自顶而下(Top-down)的姿态估计方法
- 自顶向下人体姿态估计算法使用两个独立的网络:一个人的检测网络和一个人的姿态估计网络来执行姿态估计任务。
- 首先用检测器在图像中检测人。然后从图像中裁剪出被检测到的人,利用单人姿态估计网络预测每个人的关键点。
- 许多自顶向下算法在COCO关键点基准上取得了优异的性能。
- 通过有效地共享特性,Mask-RCNN可以以端到端的方式完成这项任务。它首先生成人的proposals。然后对每个建议预测K个masks,每K个关键点类型对应一个mask,这是一个检测器中的姿态估计器结构。
3. Detector-in-Detector Network
- 所提出的Detector-in-Detector network (DID-Net)的体系结构如图2所示。
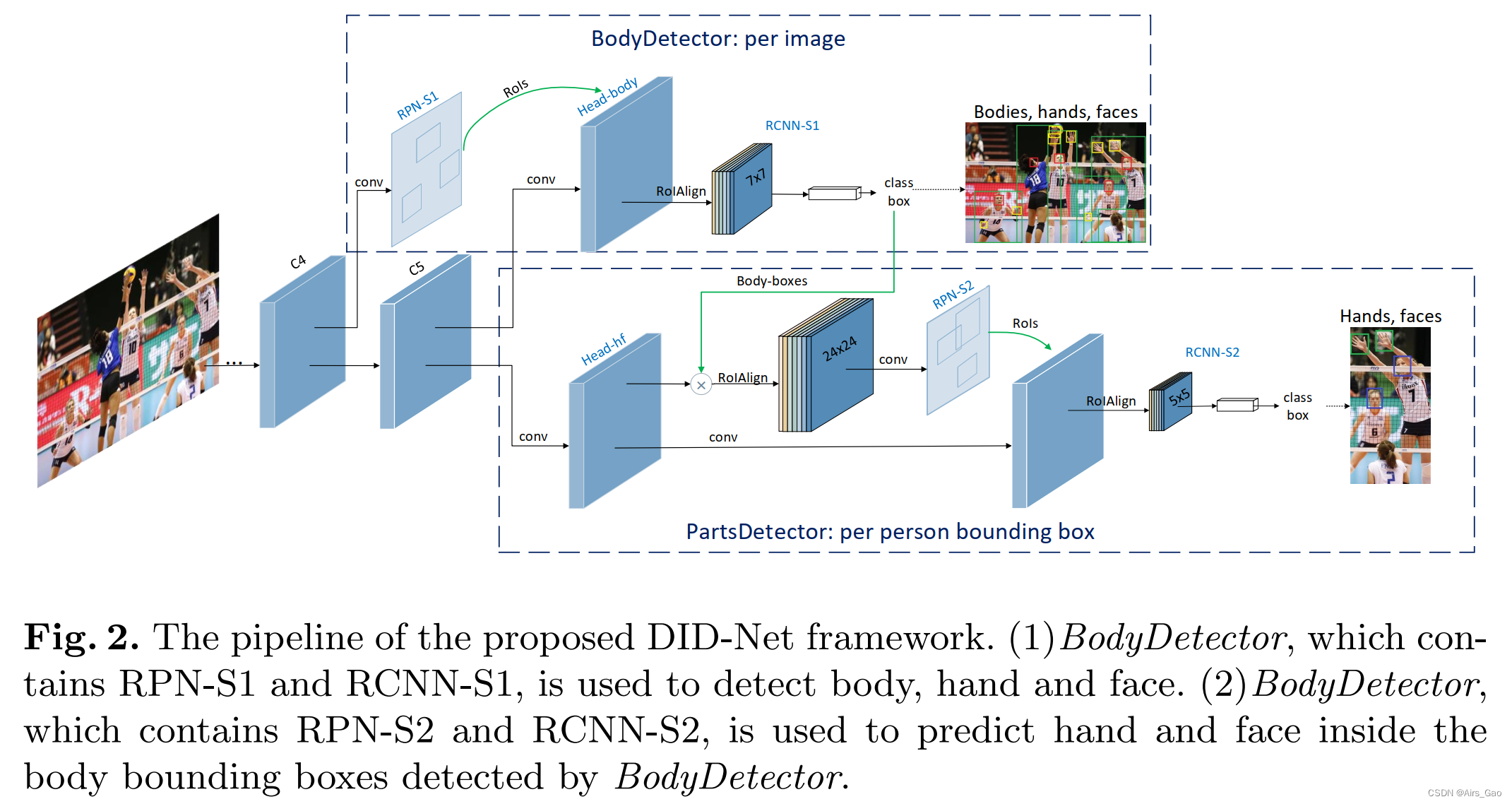
- 我们对Faster RCNN结构进行了扩展,在它之后附加了另一个轻量级部件检测器,这是一个Detertor-in-Detector结构。
- 框架包含两个检测器:
(1)BodyDetector是专为人体、手和脸检测而设计的。
(2)PartsDetector附加在由BodyDetector选定的身体边界框内,用于手部和面部检测。
3.1 BodyDetector
- BodyDetector使用与Faster RCNN相同的结构。我们的骨干网络是Resnet-50,它是在ImageNet上预先训练的.
- Backbone网络生成一系列多尺度的卷积特征maps。我们将这些特征maps表示为(C2, C3, C4, C5),这是从每个scale阶段的最后一层提取的。
- 为了增加C5特征图的分辨率,我们将有效stride从32像素减少到16像素。因此,每一层对应的stride相对于输入图像为(4,8,16,16)像素。
- C4特征预测一组proposals,使用region proposal network(RPN-S1)。
- 然后,利用RoI Align(使用7×7大小)将每个proposal的特征从Head-body中裁剪出来,汇集到一个固定大小的特征向量中。
- 然后将这些特征输入到RCNN-S1中,对身体、手和脸进行per-proposal分类操作和box refinement。
- 为了模型的紧致性,在C5的顶部特征上使用256个核的1×1卷积层后生成Head-body,以降低维数。
- 在Head-body的特征图顶部添加RoI Align层。
- 维度1024的两个新的fully connected (fc) layer应用于RoI Align特性,然后是边界框回归和分类分支。
3.2 PartsDetector
- PartsDetector共享第一阶段相同的卷积特征,通过简单地将Head-hf添加到C5,与Head-body平行, 其中包含256通道功能与Head-body相同。
- 选择第一阶段分类分数较高的预测体边界框。对所选方案进行非最大抑制(non - maximum suppression, NMS)来消除高度重叠的检测边界框。
- box regression后,将person proposals 的特征从Head-hf 包装 with RoI Align,并且池化为24 × 24大小。
- 将RPN-S2应用于被包裹的身体特征上,生成手和脸的roi。
- 然后从另一组特征中提取出roi的特征,这组特征是输出的256个通道特征,通过在Head-hf上加入2个3×3 的卷积层获得。
- 在提取的RoI特征后附加两个fully connected layers,用于使用 RCNN-S2进一步分类和box regression。
- 在这一阶段,我们使用尺寸24 × 24 for 身体的RoI Align 尺寸,并使用尺寸5 × 5 for 手或脸的裁剪特征,因为他们之间的比例差异。
- 在训练过程中,考虑到我们使用的数据集,我们在每张图像中选择前16个身体检测,通常每张图像中最多包含11个人。
- 在PartsDetector中,我们在编写实现代码时,将每一个被检测到的人体视为检测器中的一个输入图像。
- NMS用于消除推理和训练过程中高度重叠的检测边界框。
3.3 Loss function
- 我们的网络被训练来实现多任务loss的最小化,其中包括来自两个检测器的RPN和RCNN模块的分类和bounding-box regression损失。
- 我们在分类中使用softmax cross-entropy loss,在bbounding box回归中使用smooth L1 loss。
- 对于两个探测器的RPN阶段,分类loss 是背景/前景类的softmax cross-entropy loss。
- 损失函数如下所示:
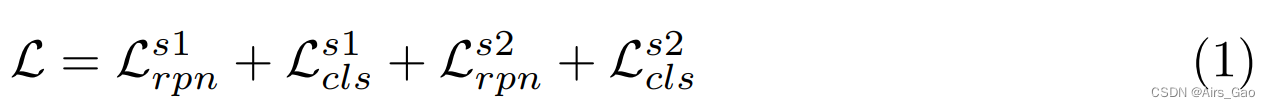
其中,L_s1_rpn和L_s1_cls表示BodyDetector中RPN-S1 and RCNN-S1的loss。
L_s2_rpn和L_s2_cls表示PartsDetector中RPN-S2 and RCNN-S2的loss。
4. Experiments
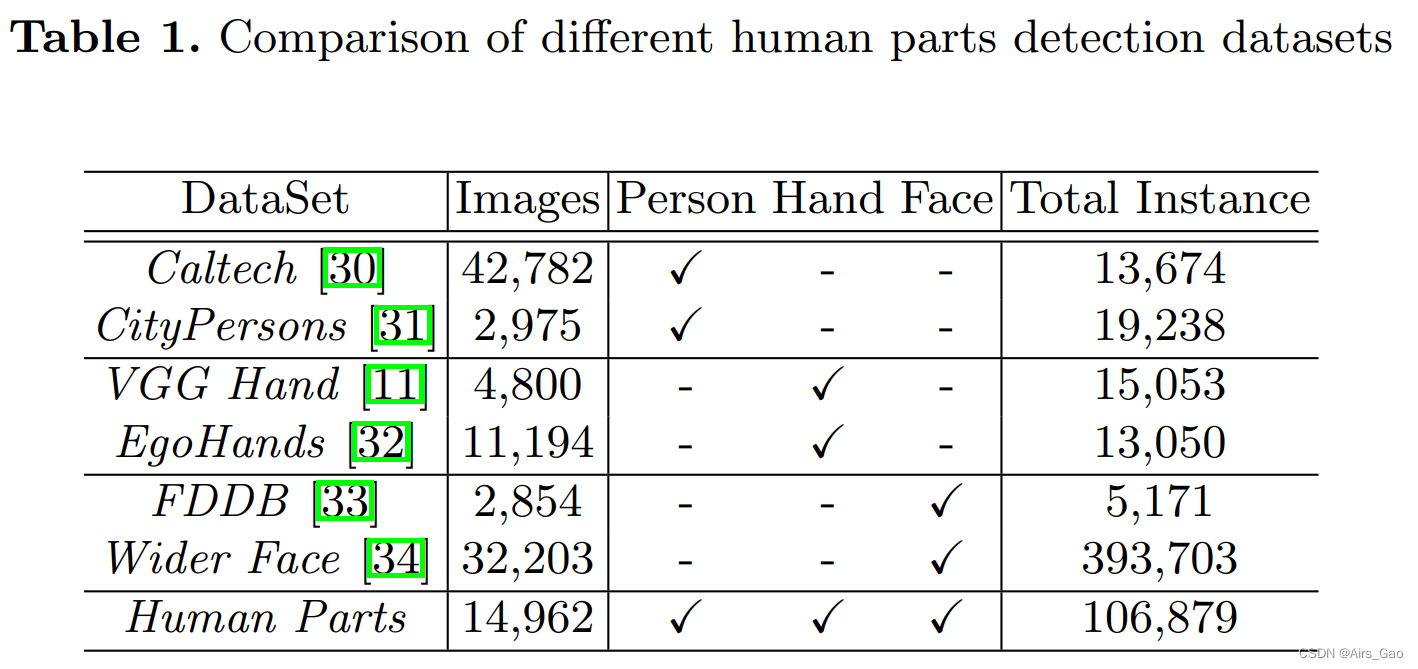
4.1 Human-Parts Datasets
- 在本文中,我们收集并标记了一个名为HumanParts的检测数据集,该数据集包含人、手和脸三个类别的注释。
- 每张图片的人数从1到11。
- 我们的数据集总共包含14,962张图像(我们使用12000个用于训练,2962个用于测试)和106879个注释(35306人,27,821张脸和43,752只手)。
- 我们用xmin, ymin, xmax和ymax坐标标记了每一个可见的人,手或脸,并确保注释覆盖了整个对象,包括遮挡的部分,但没有额外的背景。
- 注释的格式按照PASCAL VOC。
- 有代表性的图片和注释见图3所示。

关于这个数据集的更多细节以及与其他人体部位数据集的比较见表1。
4.2 Implementation Details
- 我们在Human-Parts数据集上进行所有实验。对12000张训练集图像和2962张测试集图像进行训练和评估。
- 我们使用standard average precision(AP)和mean average precision(mAP)进行评价。
- 我们报告AP和mAP分数使用intersection over union (IoU)阈值为0.5。
- 所有的网络都是从预先训练的ImageNet分类网络ResNet-50进行微调的。
- 我们的系统是用Pytorch实现的。
- 对于anchor的生成,我们在BodyDetector阶段使用尺度(642,1282,2562,5122),在PartsDetector阶段使用尺度(322,642,1282,2562),考虑到身体和身体部位的尺度变化。
- 所有anchors的aspect ratio为(0.5,1、2)由于在野外手和脸有很大的变化。
- 在培训过程中,BodyDetector的RCNN-S1阶段采用512的mini-batch size,PartsDetector的RCNN-S2阶段每个person RoI采用32的mini-batch size。
- 采用多尺度训练策略,对不同尺度目标具有鲁棒性。
- 在我们的方法中,较短的一侧被调整为(416,480,576,688,864,1024)像素。
- 我们只使用水平图像翻转增强。
- 在测试阶段,每个图像较短的一面被调整到800像素,并独立测试。
- 在训练过程中,我们采用了使用随机梯度下降(SGD)的端到端学习过程。
- 整个网络经过30,000次迭代训练,初始学习率为0.01。
- 我们在20,000次迭代时将学习率衰减0.1。动量为0.9,权值衰减为0.0005。
- 在推断过程中,BodyDetector模块输出300个最佳评分anchors作为检测。
- 而在PartsDetector模块中,由于每个身体区域内的部分有限,我们只选择30个最佳评分anchors。
- BodyDetector 和 PartsDetector中hand和face的输出结果融合在一起,并对输出执行阈值为0.45的NMS。
4.3 Main results
-
在表2中,我们使用不同的数据和我们的DID-Net对传统的Faster RCNN训练进行研究。
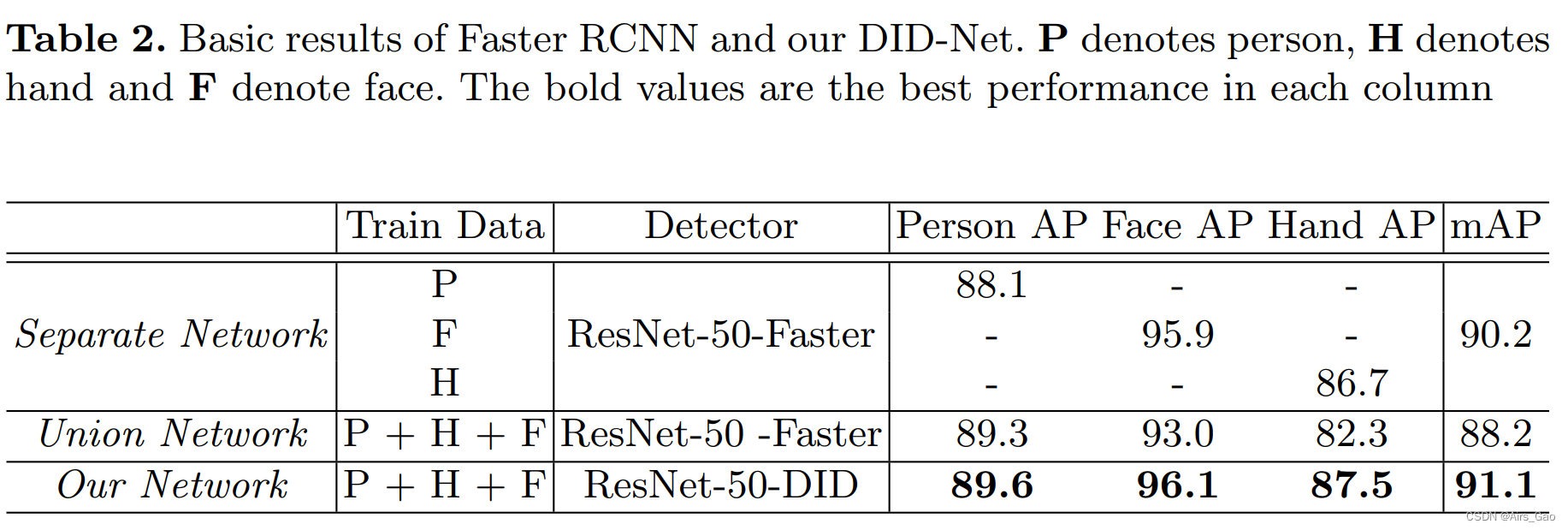
Separate Network 在一个ResNet-50 Faster R-CNN网络中只处理一个类别检测任务。(即person,hand,face分开检测);
Union Network在同一网络中同时执行三类检测任务。(即person,hand,face同时检测)。 -
Person AP
在Union Network中一起进行多目标检测任务后,人的AP性能从88:1提高到89:6,由此我们可以推断手和脸的显著性将有助于人的检测性能。 -
Small Parts AP
Union Network中小部件AP值较Separate Network降低。原因主要来自人体与身体各部位之间的尺度差异。在实际操作中,整个图像主要被人体等较大的物体所占据。小的手和脸通常占据相对较小的面积。在固定anchor尺度和anchor比的情况下,RPN产生的小锚点较少,导致小零件检测性能较差。 -
与Separate Network和Union Network相比,DID-Net在每个主体内部进行另一个RPN,其他物体或背景的干扰较少。
-
DID-Net可以了解更多身体部位之间的空间区域关系。此外,在提取人proposals的特征时,我们将这些包装的特征汇集到24 × 24的大小,这将比原始的人特征映射更大。这个操作将缩小small parts的特征,为进一步的检测提供了高分辨率的特征图。
4.4 Ablation study
- 在表3中,我们评估了不同的组件如何影响PartsDetector的检测性能。为了比较公平,我们修改了骨干网和BodyDetector的参数。因此,表3中的人员AP是常数。
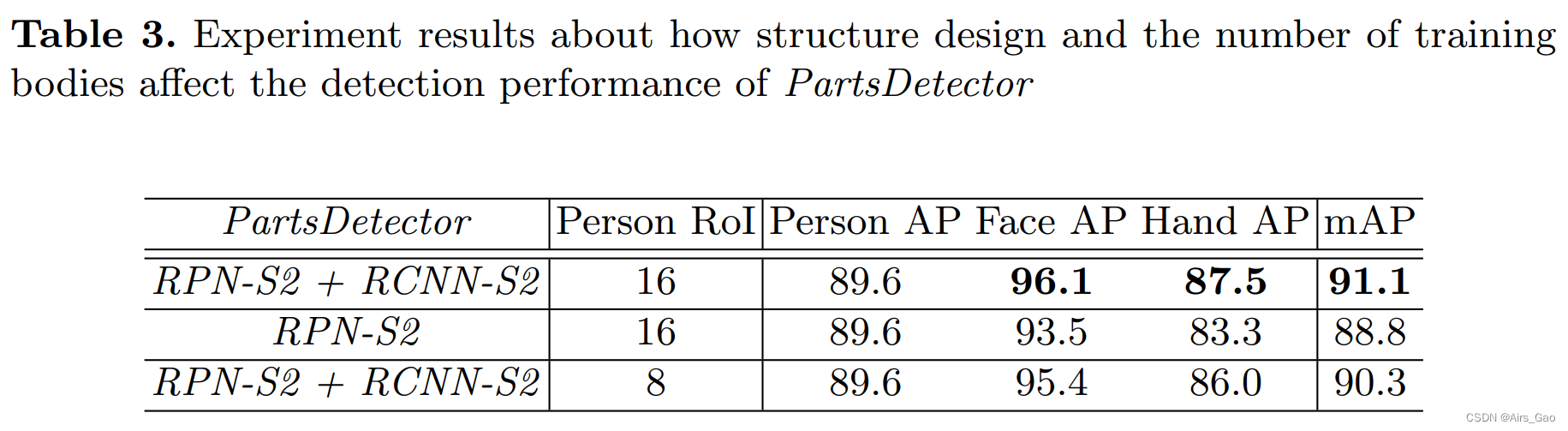
- Architecture
PartsDetector有两种设计:
(1)RPN-S2 + RCNNS2设计:它遵循我们在第3节中描述的结构。采用两种RoI Align操作,如图2所示。
(2) RPN-S2与SSD一样,直接输出每个RoI的classification和box regression。只有一个RoI Align操作。
从表3可以看出,PartsDetector的两级设计可以在小部件检测上实现更高的精度。 - Person RoI
Person RoI表示多个人体在NMS操作之后在训练过程中从BodyDetector中选择。
考虑到计算效率,不使用较大的数字。选择16和8.
结果表明,如果在训练过程中选择的body小于图像实际包含的body,Head-hf的特征将不能包含对未选择body的足够响应。
不完整的训练将导致PartsDetector的性能下降。
4.5 Comparisons with the state-of-arts
- 我们将提议的DID-Net与表4中对Human-Parts数据集执行的最先进方法进行比较,其中包括SSD(训练图像大小为512 × 512)、Faster R-CNN、RFCN和FPN。
SSD是使用它论文的原始设置进行的。
对于这些基于区域的检测器,多尺度训练(在4.2中描述),锚点尺度为(642,1282,2562,5122),锚点比率为(0.5,1,2), RoI Align在训练期间所有模型均采用。
所有模型经过30,000次迭代训练,初始学习率为0.01,权值衰减为0.0005,动量为0.9。
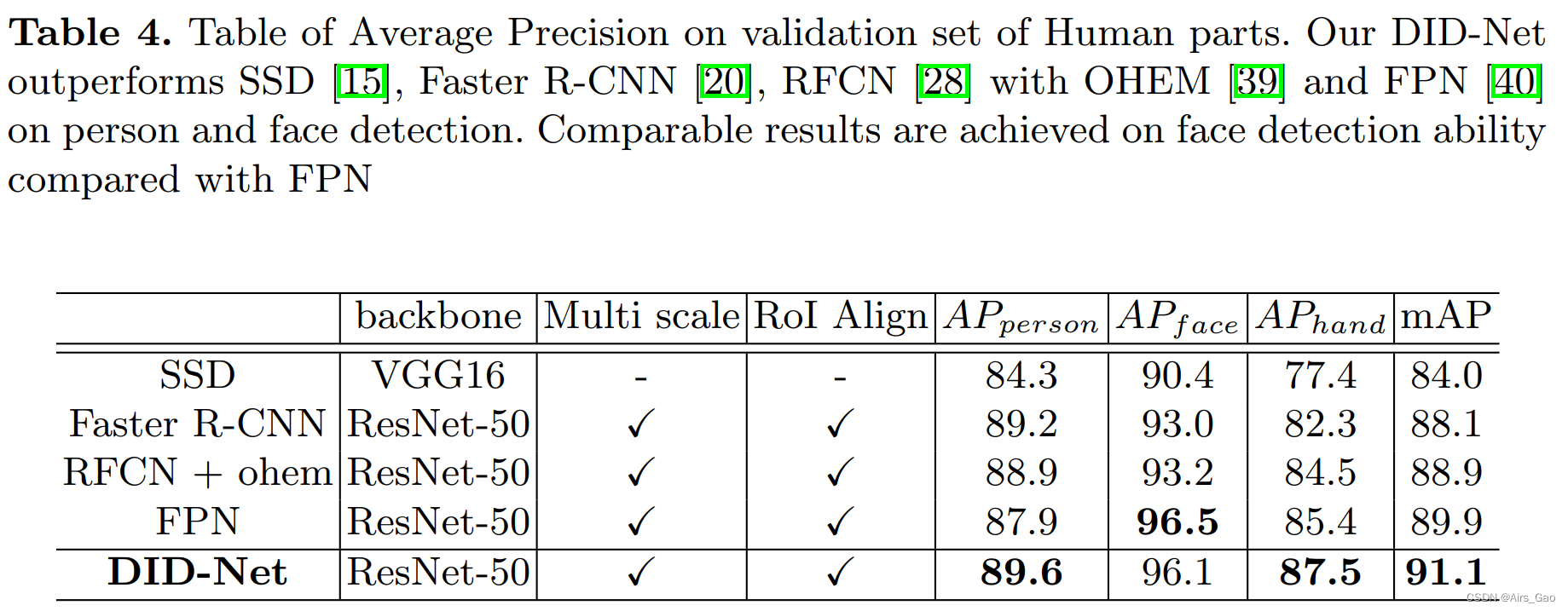
- 结果表明,我们的DID-Net在人和手的分类上达到了最高的准确率。
- 基于区域的两阶段检测模型(Faster R-CNN, RFCN,FPN)的性能优于单级检测器(SSD),证明了两级检测器的能力。
- 由于不同尺度特征的高效融合,FPN在手和脸检测性能上比Faster R-CNN更好。
- 在基础的BodyDetector上加入PartsDetector后,我们的体系结构对人脸和手的检测性能有了很大的提升。
4.6 Qualitative Results
- 我们在样本图像上给出了一些定性的人体部位检测结果图4所示。

- 从第一行的Faster RCNN结果中,我们观察到仍然存在一些无法检测到的小手或小脸(在黄色框中).
- 而在DID-Net的结果中,可以检测到这些困难的部分。结果如图4第二行所示。


















 2823
2823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









