







- Transformer
1.简介
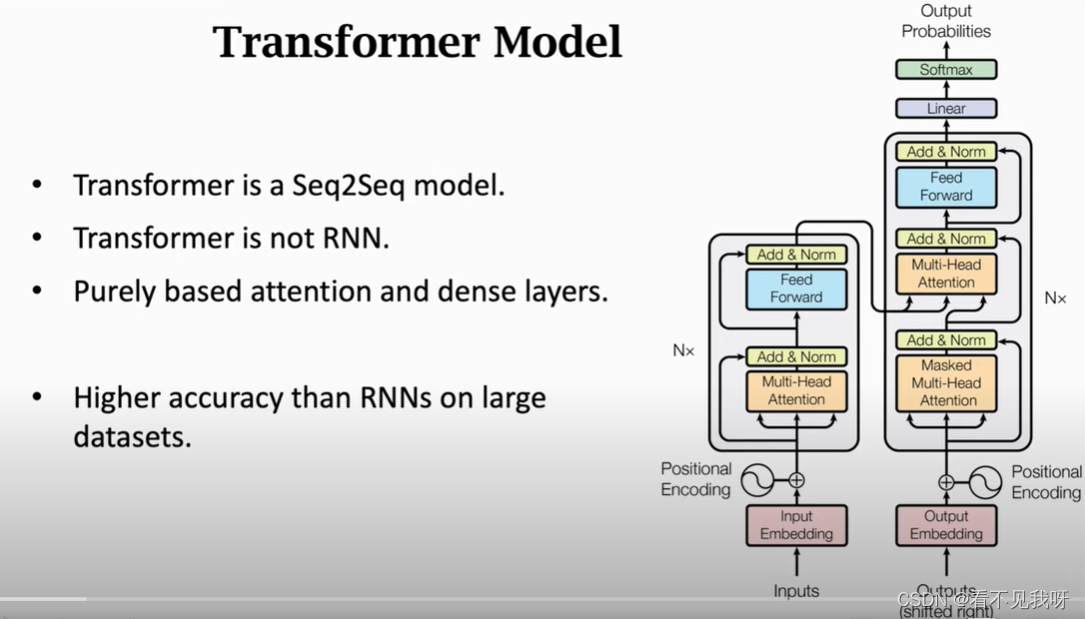
非rnn结构,仅仅基于attention + fc
现在机器翻译,全部用transformer + bert
2. 回顾attention

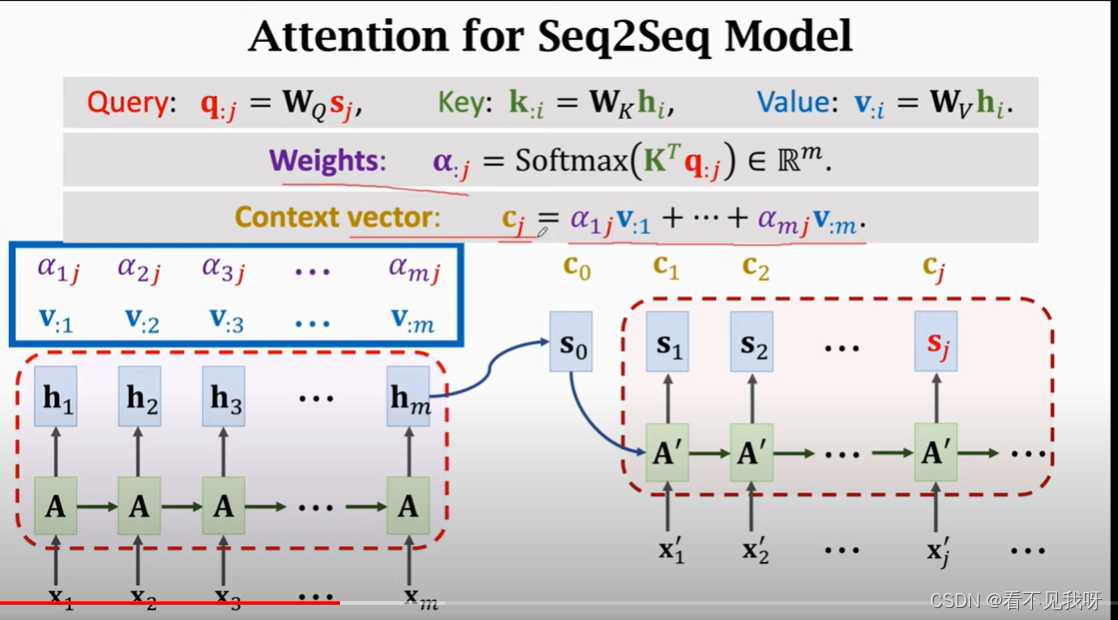
Hm:对所有的输入的概括
根据状态sj,生成单词。新生成的单词,作为xn
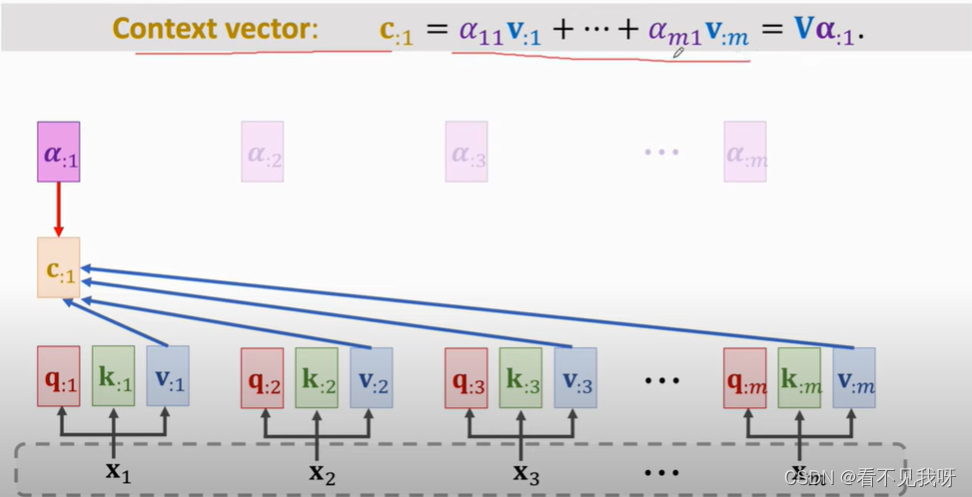
每一个s计算一个c(context vector)
Decoder 的当前状态与encoder的所有状态做对比,用align函数计算相关性alpha。
此处,WK,WQ,WV均为attention的参数,需要从训练集中学习到。
此处的attention是用在RNN上的。
对,根据RNN的性质,此处的参数是共享的。


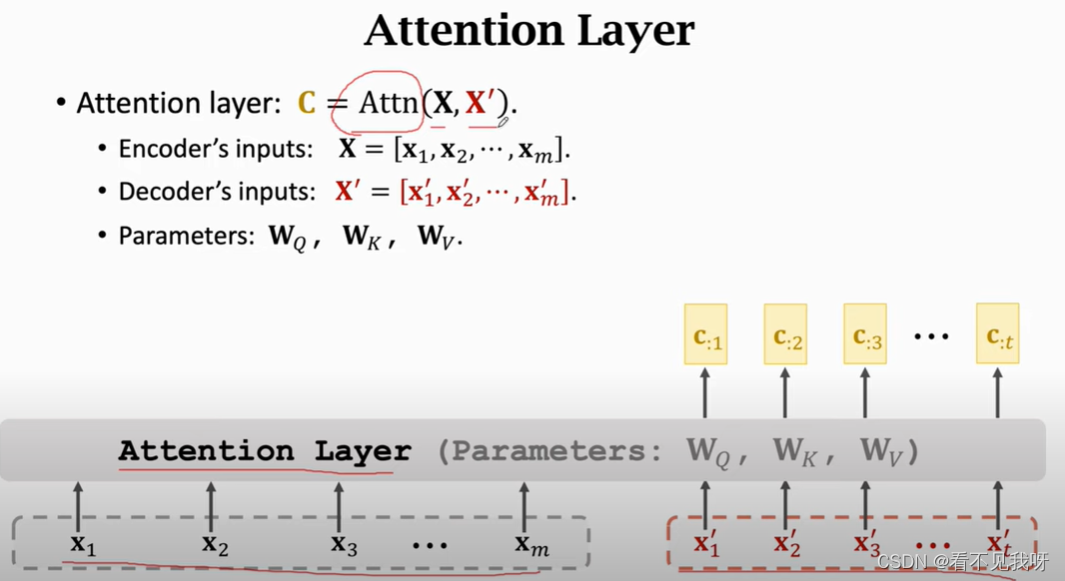
3. attention without RNN
此时,会得到attention 和 self-attention,而transformer正式有这两层结构组成的。
下面搭建attention层


不用RNN,直接计算输入的k和v,一共得到m个k向量和m个v向量。注意,一共三个参数。

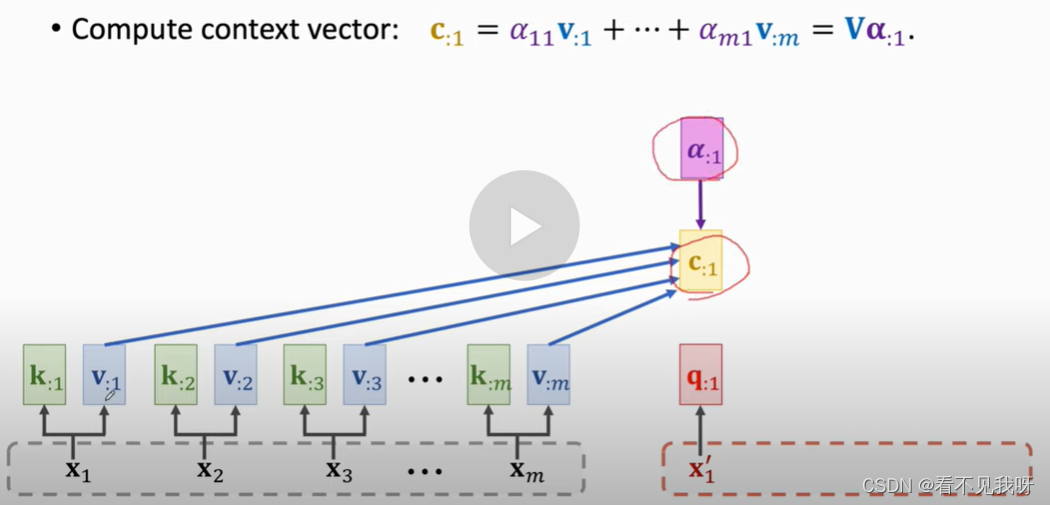
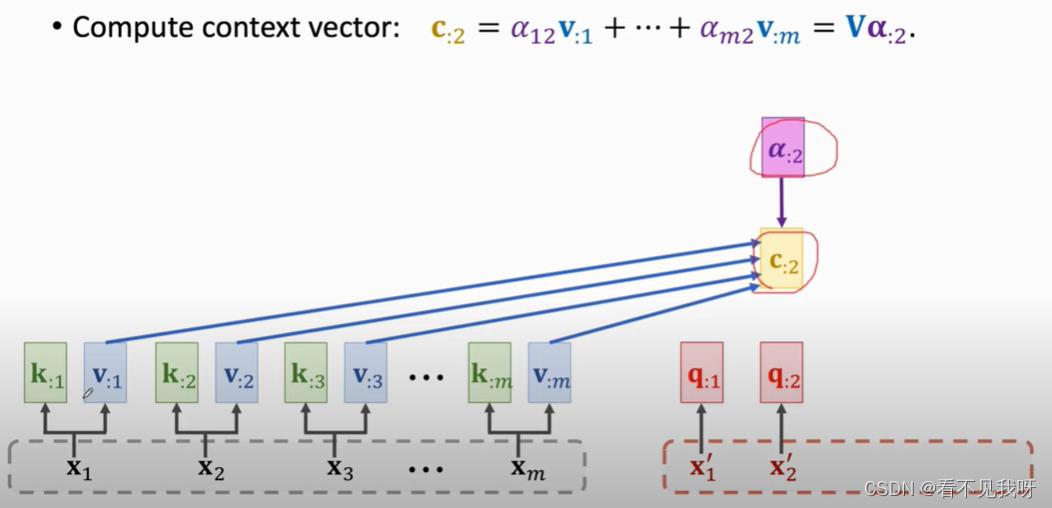

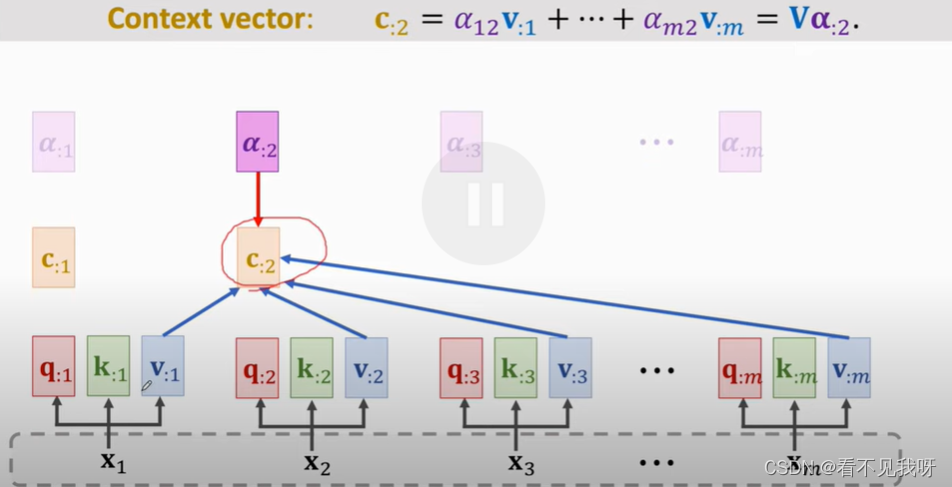
每一个c向量,对应一个x向量。
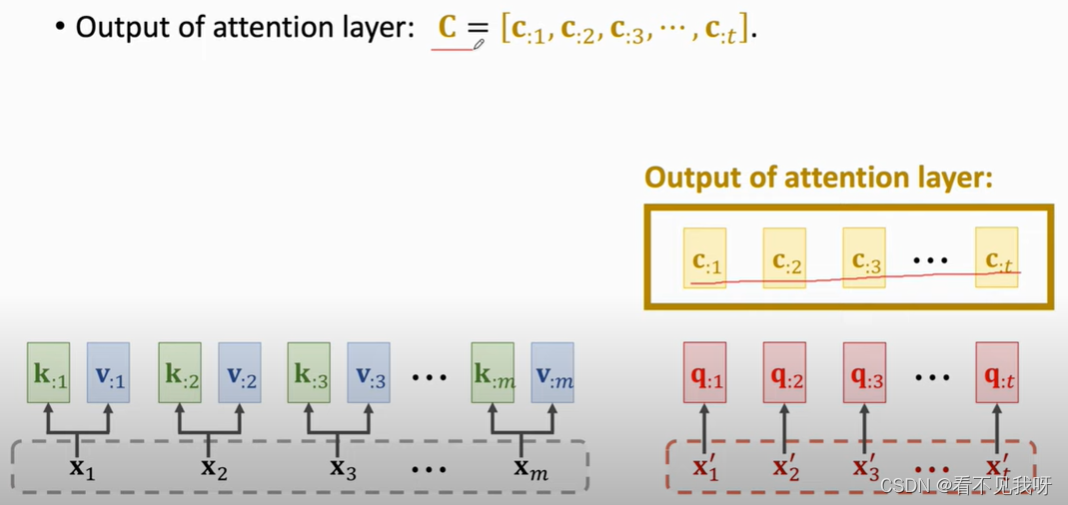
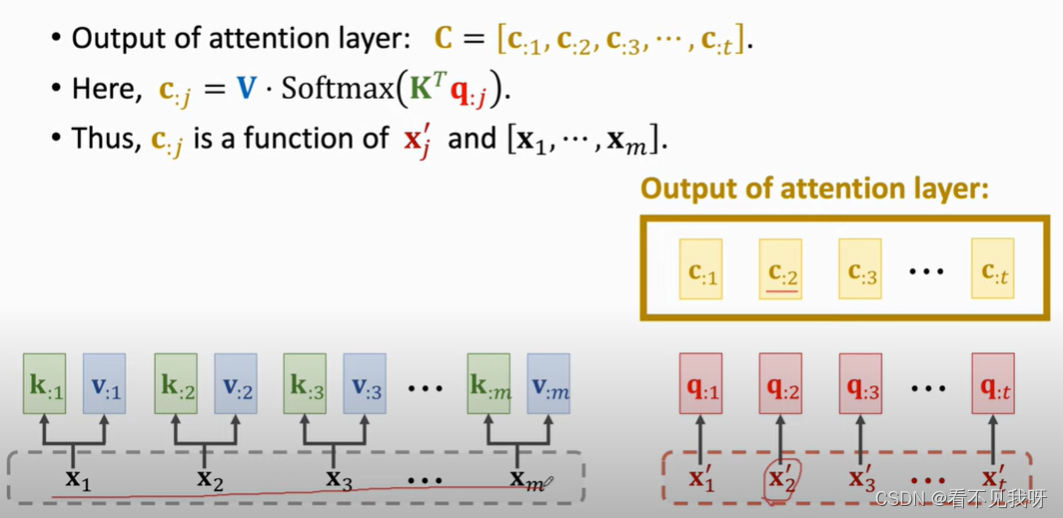
C就是最终的输出。

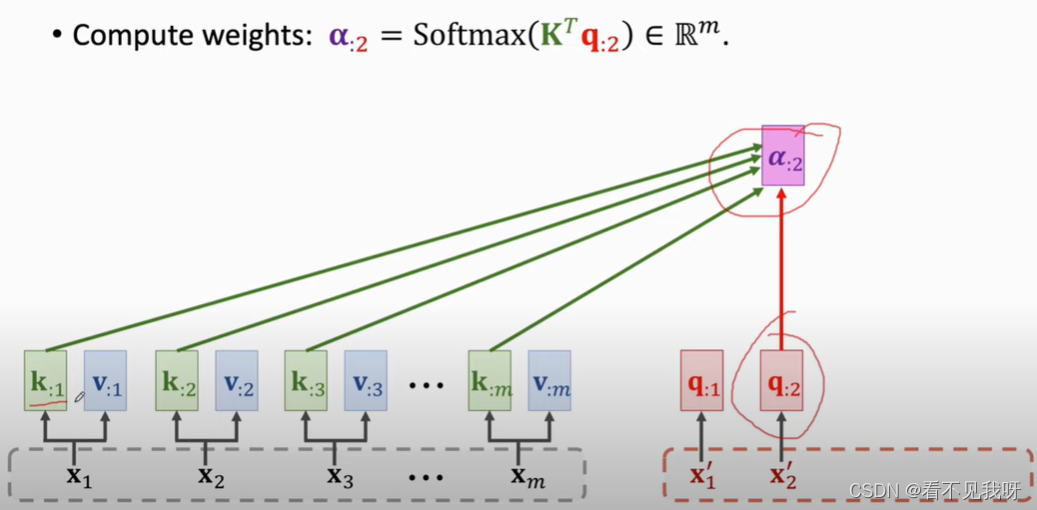
C2可以看到全部输入x,以及解码器的本次输入x’
C2作为特征向量,输入softmax,得到概率分布p2,
P2抽样,得到x3‘
这个过程和rnn很相似,RNN采用状态h作为特征向量;attention采用c作为特征向量。并且不会遗忘。
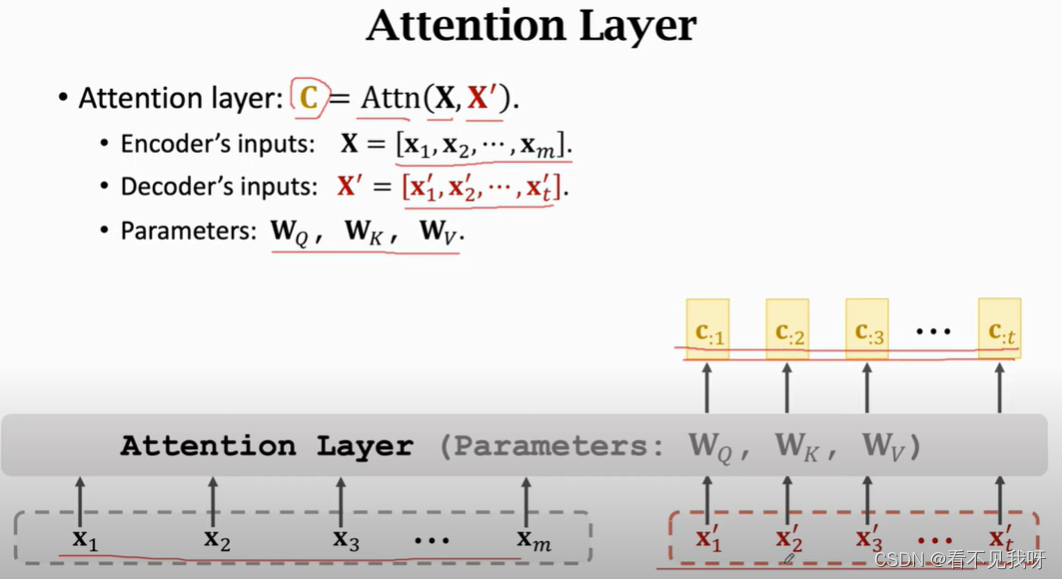
此即为attention层,输出c为矩阵,其列向量为c1,c2,…
4. self-attention without RNN
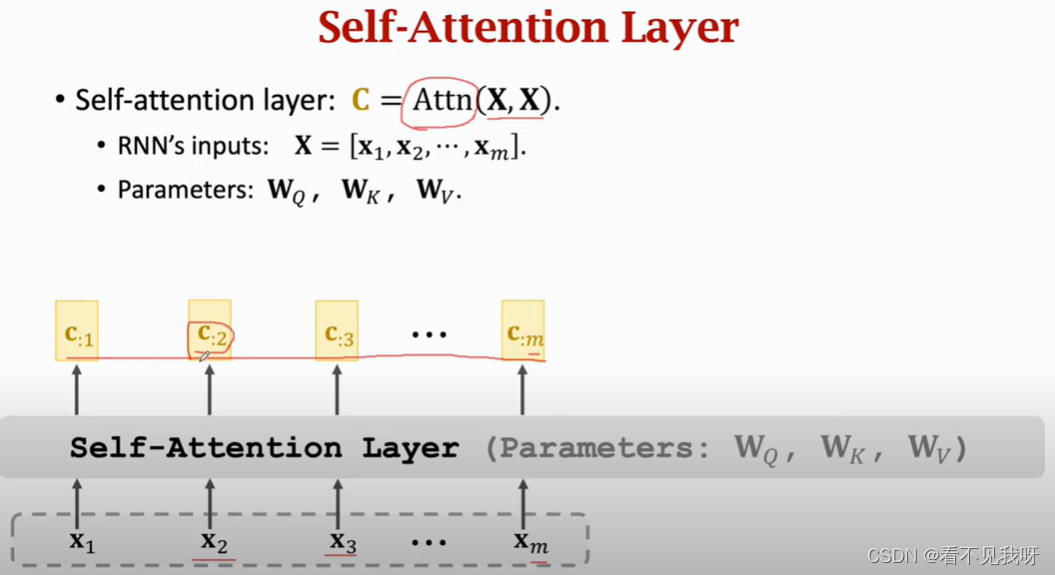
Self attention 并非sequence2sequence。
其只有一个输入序列,输出为c1,c2,。。。cm
C:2并非仅仅依赖于x2,而是依赖于所有的m个x向量,改变任意一个x向量,c:2均会发生改变。
Self attention的原理和self attention的原理一样,仅仅是输入不一样。


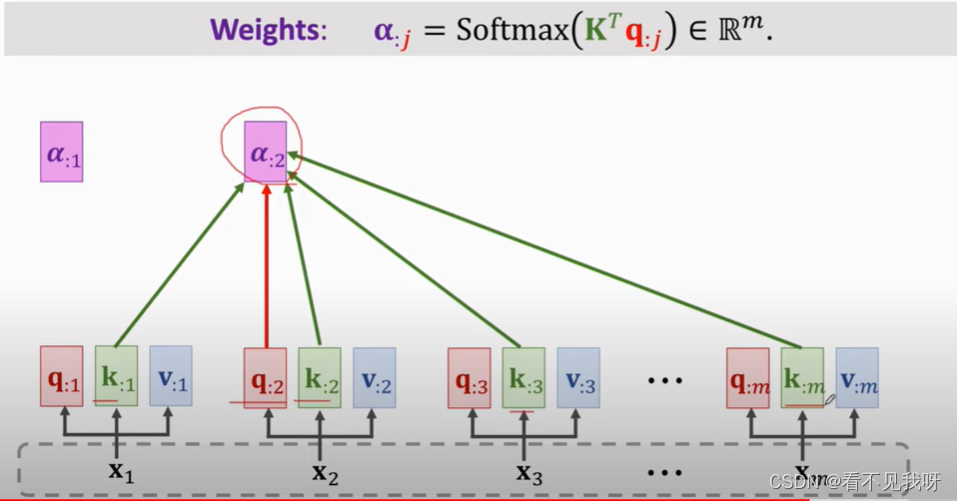



和attention的区别,仅仅是q向量的获取方式不一样。Attention是从解码器中获取的。Self attention是从编码器中获取的。
5.总结
总结:
首先attention是用在sequence2sequence中,后来发现,attetion并不仅限于s2s模型,而是可以用在所有的rnn上。当只有一个rnn时,称为self-attemtion。
后来发现,仅仅只用attention就很好的,加上rnn效果反而不好了。此即为transformer。
Selft-attention的输入和输出一样,因此可以替换rnn。















 7937
7937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









