







- Few-shot learning
https://www.youtube.com/watch?v=UkQ2FVpDxHg&list=PLvOO0btloRnuGl5OJM37a8c6auebn-rH2&index=1&t=3s
1.问题的引出
通过很少的样本来进行分类/回归


给你四张图像,人类大概可以知道,查询图像是什么。
同样,机器也需要知道。
Support set:很少的数据集,例如每类图像有2张。这么少的样本不足以训练一个模型。

传统的监督学习:让机器学习训练集,然后泛化到测试集。
Few-shot learning:让机器自己学会学习。
在一个大的数据集中,few-shot learning不是让nn知道什么是大象/老虎,让后去识别没见过的大象/老虎。学习的目的是理解事物之间的不同,学会区分不同事物。给两张图像,不让学会是什么,而是学会是否相同。
训练完模型之后,可以问模型,如下问题:

在来看大数据集,根本没有松鼠。模型不认识松鼠,但是模型知道事物之间的异同,可以告诉你,他们相同。


换种说法:
给你一张query图像,问nn,这是什么东西?训练的时候没有见过这种东西呀
在多给一个support set,包含6张图像,告诉她分别是狐狸,。。。。。

NN拿query,依次与support对比,发现和水獭最相似。因此,query应该是水獭。
Support set:带标签的术语。规模很小,每一类有一张/几张图象。在做预测的时候,提取额外的信息。
Traning set:规模很大,每一类有很多张图像。
核心:用足够大的模型,来训练一个大模型,如深度神经网络。训练的目的,不是让模型学会大象/老虎等。而是让模型学会事物的异同,然后根据support set,就可以知道quey是什么,尽管训练集中没有水獭类别。
2. few-shot learning & meta learning

传统监督学习:模型学习训练集,然后泛化到测试集。
Meta learning:学会学习。


靠一张卡片学会水獭,为 one-shot learning。

模型没有见过这张哈士奇,但是训练集里有上百张哈士奇,模型由一定的泛化能力。

模型不仅没有见过这张兔子,而是没有见过兔子这个类别的所有图像。
因此需要给模型看小卡片。


6-way 1-shot

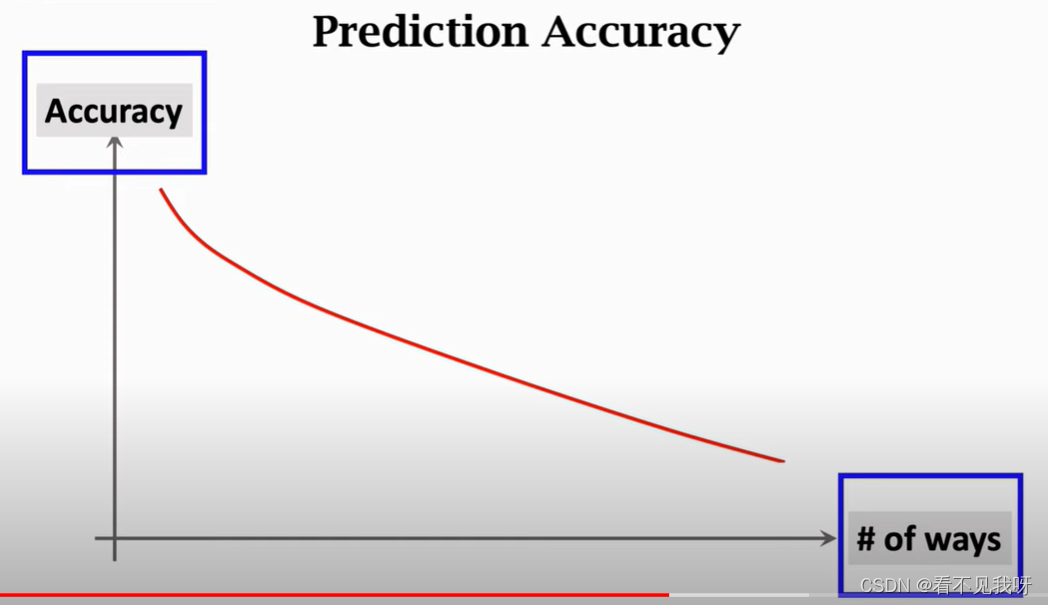
随着类别增加,分类准确率降低。

3选1,明显比6选1,准确呀。

参考样本越多,预测越容易。

3. 解决few-shot learning的问题

基本想法:学习一个函数,来学习相似度。




4. 数据集
如果做meta learning,需要用标准的数据集,来评价算法的好坏。

手写数字属于据。
1600类,每类由20张图像

















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









