







四,VIT
- 概述


需要在的数据集上进行预训练。
Vit本质为 transformer encoder网络。
- 算法

Vit将图片划分为大小相同的patches,可以重叠划分,也可以不重叠划分。

每个patches都是RGB的图像,属于张量。
需要将张量拉伸为向量。
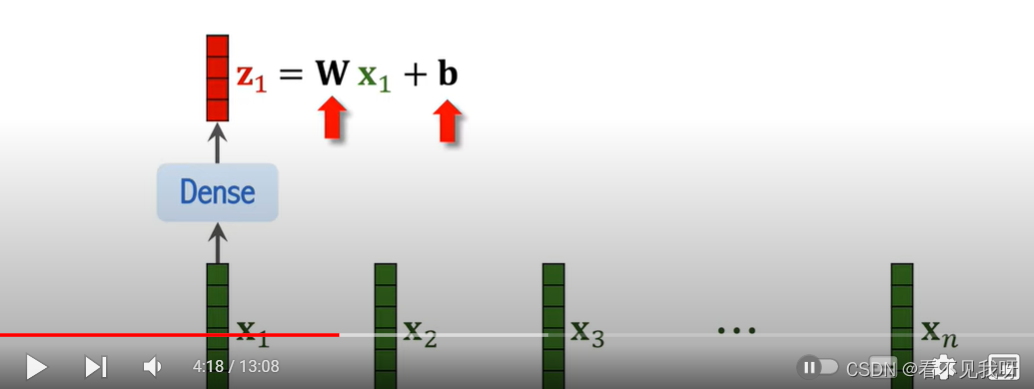
Fc对向量x进行线性变化,注意不采用relu,得到z,此处WB为参数,需要训练得到,并且所有patch共享参数。





Z不仅编码了内容表征,而且包含位置信息。如果不用位置信息,会掉点3%。
一定要用positon encoder,但是具体什么形式的position,影响不大。

如果不用位置编码,则上图左右的transformer的输出一样。这样不好。
因此需要进行编码。
如果patches变化顺序,则其位置编码也会变化。

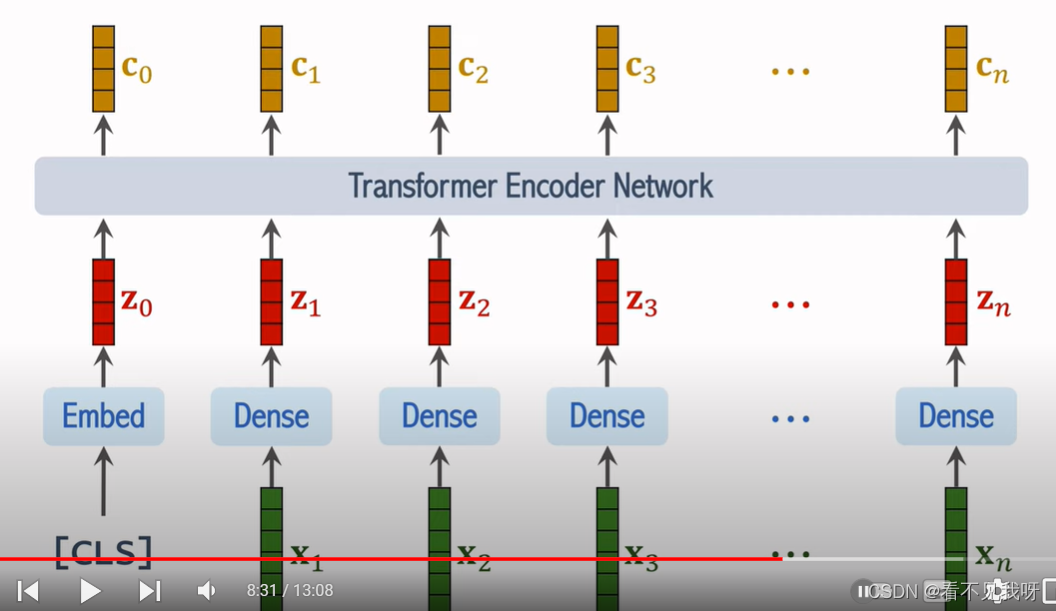
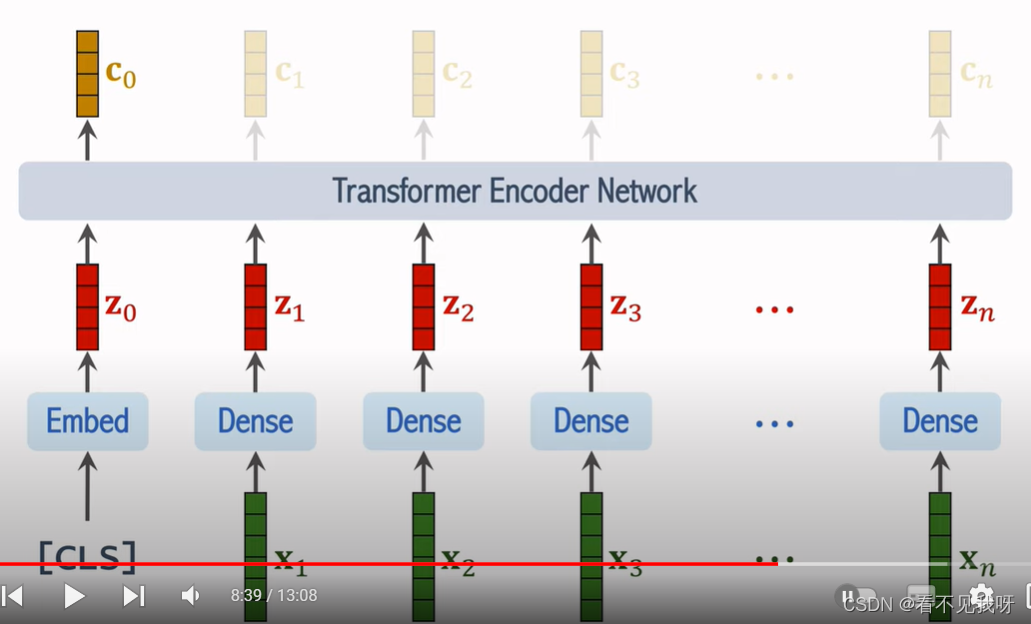
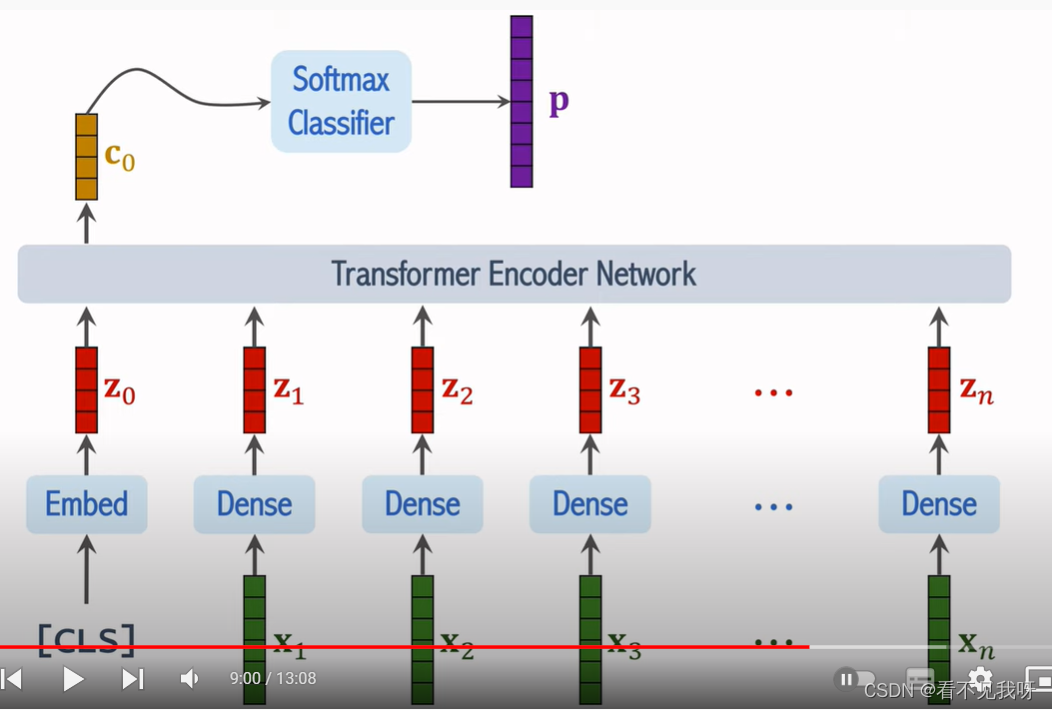
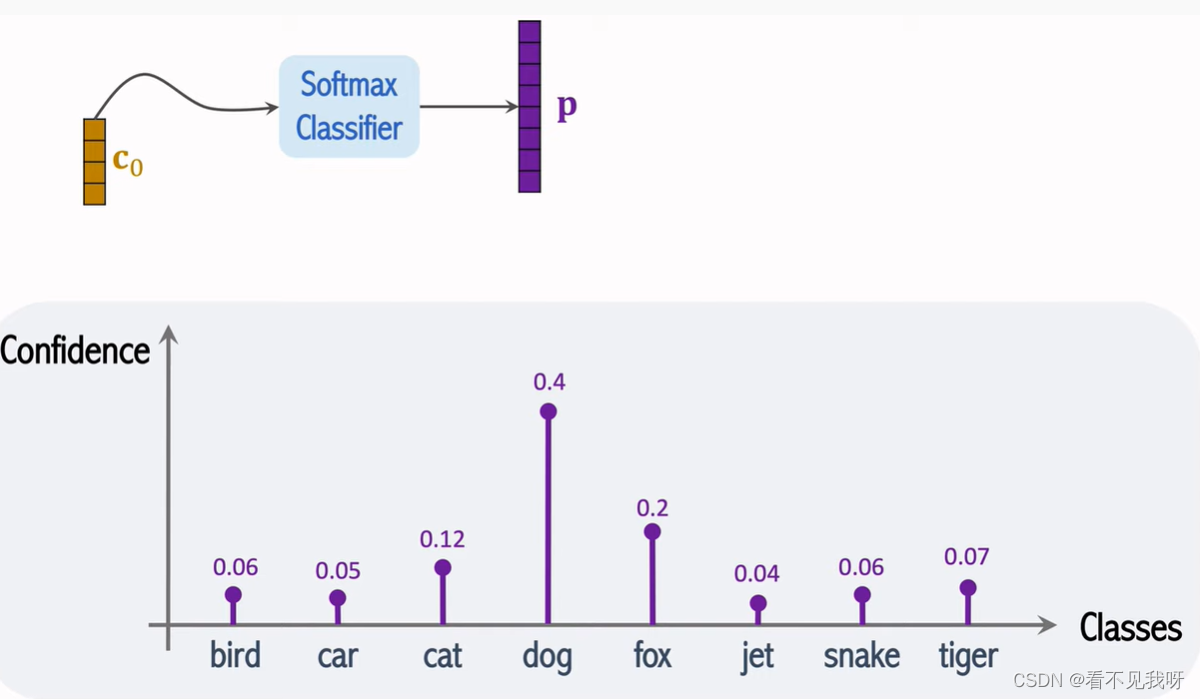
- 训练

数据集A很大,如JFT数据集-3亿张图像;
数据集B相对小,如imagenet-130万张图像

- 评估
















 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









