







懒得自己写,直接粘贴了
链接:https://www.zhihu.com/question/53224378/answer/194230021
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1.分析一(可以当做是修正网络的思想)
我就简单补充一点,为什么同一映射 I(x)=x 这一项前的系数为1而不是1/2。
- 一方面,实践发现机器学习要拟合的(target function)函数 f(x) 经常是很接近同一映射函数的。
- 另一方面,神经网络权值的初始值往往在 0 附近。
因此,以同一映射函数为初始函数,用其他神经网络做微调,相当于赢在了起跑线上。
形象但是松散一点描述就是,经验表明要拟合的函数接近一根直线,于是就用一根直线加一些微小的折线们叠加来拟合。如果只用直线,就成了线性分类/回归,细节难把握;而只用微小的折线们,要优化的路很长,并且还容易过拟合。
有篇文章 [1] 仔细分析了残差网络背后的原理,简单的说就是大量的(exponential)不同长度的神经网络组成的组合函数(ensemble)。
为什么简单补充一点就写了这么多。。。有什么再继续交流吧。对了,要想比较好的理解,最好找个好点的教程,自己动手运行一下代码。然后你会发现,就加了几行代码就拿了IMAGENET的冠军,简直赞啊!
[1] Christian Szegedy, Sergey Ioffe, and Vincent Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv preprint arXiv:1602.07261, 2016.
链接:https://www.zhihu.com/question/53224378/answer/169087864
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单来说,残差网络效果好,很大程度上依赖于残差连接回传的梯度缓解梯度消失等问题,所以只能取x,实验结果也佐证了这一点。
第一次答题,请多指教Orz。
对于resnet,可以参考Kaiming大神的两篇论文。
[1] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” http://Arxiv.Org, vol. 7, no. 3, pp. 171–180, 2015.
[2] K. He, X. Zhang, S. Ren, and J. Sun, “Identity Mappings in Deep Residual Networks Importance of Identity Skip Connections Usage of Activation Function Analysis of Pre-activation Structure,” no. 1, pp. 1–15, 2016.
- kaiming大神在[1]中提出了残差结构。之前的答主有提到,resnet的提出是为了解决深层网络优化的问题,如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。残差结构的输出表示为F(x) + x,相比于用多个堆叠的非线性层直接去学习恒等映射F(x) = x,残差结构直接学习F(x) = 0使得训练更容易些。
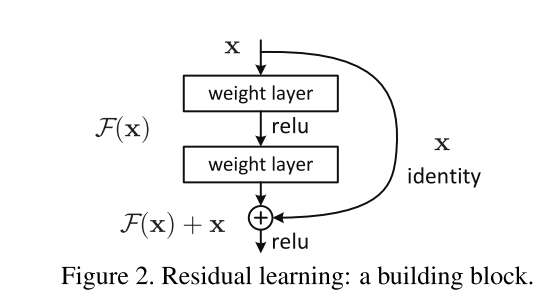
- 至于F(x)长什么样,这个问题不是特别理解。我觉得模型的训练,就是根据一个训练集数据(某个函数加入噪声后的采样)更好地拟合该函数。如果知道了这个函数长什么样,那就不用训练啦。另外,如果真的知道H(x)是什么样,那F(x)就是 H(x) - x 好了。
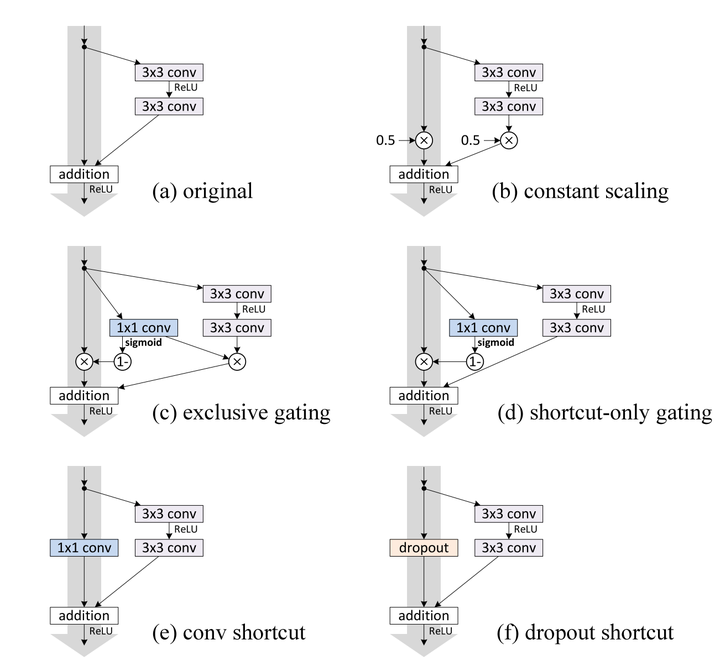
- 至于为何shortcut的输入时X,而不是X/2或是其他形式。kaiming大神的另一篇文章[2]中探讨了这个问题,对以下6种结构的残差结构进行实验比较,shortcut是X/2的就是第二种,结果发现还是第一种效果好啊。















 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









