







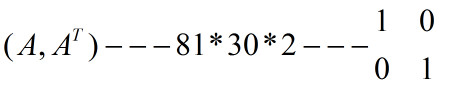
设A是一个9*9的随机矩阵,让矩阵的每个格子都是一个0到1之间的随机数。A^T是矩阵A的转置。测试集由1000个A和A^T组成,这个网络是否可以收敛并分类?
在收敛误差δ一致的前提下,实验统计了7组收敛误差δ,每组收敛误差收敛199次,统计平均值。得到数据如下
| 9*9 | ||||||||||||
| f2[0] | f2[1] | 迭代次数n | 平均准确率p-ave | 1-0 | 0-1 | δ | 耗时ms/次 | 耗时ms/199次 | 耗时 min/199 | 最大值p-max | 迭代次数标准差 | pave标准差 |
| 0.499498 | 0.49809 | 10.90955 | 0.500035 | 0.557819 | 0.442251 | 0.5 | 26.81407 | 5336 | 0.088933 | 0.5255 | 11.26349 | 0.003822 |
| 0.53774 | 0.462017 | 24827.81 | 0.504281 | 0.77495 | 0.233613 | 0.4 | 545.0704 | 108472 | 1.807867 | 0.514 | 2953.655 | 0.003854 |
| 0.490303 | 0.509541 | 127786.5 | 0.511249 | 0.61295 | 0.409548 | 0.3 | 2722.774 | 541837 | 9.030617 | 0.5205 | 17410.29 | 0.003752 |
| 0.550817 | 0.449115 | 209571.7 | 0.507741 | 0.628131 | 0.387352 | 0.2 | 4392.603 | 874132 | 14.56887 | 0.5235 | 15133.06 | 0.005972 |
| 0.449076 | 0.550917 | 276271 | 0.505261 | 0.592126 | 0.418397 | 0.1 | 5901.533 | 1174425 | 19.57375 | 0.527 | 20397.54 | 0.007861 |
| 0.448115 | 0.551887 | 427154.3 | 0.502309 | 0.527935 | 0.476683 | 0.01 | 9562.055 | 1902855 | 31.71425 | 0.5275 | 30589.25 | 0.009812 |
| 0.467382 | 0.532618 | 561370.3 | 0.501595 | 0.512362 | 0.490829 | 0.001 | 12240.93 | 2435961 | 40.59935 | 0.528 | 48150.88 | 0.010577 |
可以观察到迭代次数n随着δ的减小而增大,但分类准确率都约为50%。表明这个网络是可收敛的但不可分类。
矩阵A和A的转置的数值分布显然是有差异的,这个差异导致网络可以收敛。那为什么差异存在确无法分类?
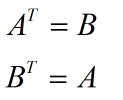
一个可能的解释是,A的转置的转置是A,也就是由A变化到A的转置,和由A的转置变化到A的操作是一样的。
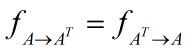
A和A的转置的训练集之间虽然存在差异,但这种差异表达的是同一种操作。让神经网络分类A和A的转置就意味这分类到底是由A转置为A的转置,还是由A的转置转置为A。这两种操作是一样的,所以不可被分成两类,或者表达为分成两类的概率相同,所以分类准确率是50%,形成双重态。
所以如果训练集之间的差异表达的是分类对象之间的相互关系,则两个分类对象之间的相互关系可以有三种
| 不可收敛 | 不可分类 | 相同的两个对象 | |
| 可收敛 | 不可分类 | 双重态 | |
| 可收敛 | 可分类 | 不同的两个对象 | |
















 54
54











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











