







目录
线性回归
y =

偏置是指当所有特征都取值为0时,预测值应该为多少。
线性模型可以看做 单层神经网络

损失函数
(loss function)能够量化目标的实际值与预测值之间的差距。 通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。
其中的 1/2 不会带来本质的差别,但这样在形式上稍微简单一些 (因为当我们对损失函数求导后常数系数为1)
预测结果y^ (通常使用“尖角”符号表示y的估计值)
梯度下降
通过不断地在损失函数递减的方向上更新参数来降低误差。
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值) 关于模型参数的导数(在这里也可以称为梯度)
表示学习率(learning rate)
超参数(hyperparameter)可以调整但不在训练过程中更新的参数.(训练完后,人为指定)
调参(hyperparameter tuning)是选择超参数的过程。 超参数通常是我们根据训练迭代结果来调整的, 而训练迭代结果是在独立的验证数据集(validation dataset)上评估得到的。

独热编码
分类数据的简单方法:独热编码(one-hot encoding)。 独热编码是一个向量,它的分量和类别一样多。 类别对应的分量设置为1,其他所有分量设置为0。
在我们的例子中,标签y将是一个三维向量, 其中(1,0,0)对应于“猫”、(0,1,0)对应于“鸡”、(0,0,1)对应于“狗”:

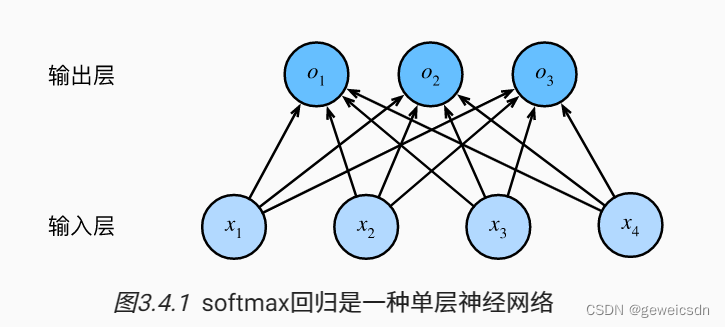
softmax回归
softmax回归也是一个单层神经网络。 由于计算每个输出O1、O2和O3取决于 所有输入X1、X2、X3和X4, 所以softmax回归的输出层也是全连接层。
softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持 可导的性质。 为了完成这一目标,我们首先对每个未规范化的预测求幂,这样可以确保输出非负。 为了确保最终输出的概率值总和为1,我们再让每个求幂后的结果除以它们的总和。如下式:

softmax运算不会改变未规范化的预测O之间的大小次序,只会确定分配给每个类别的概率。
实现softmax由三个步骤组成:

交叉熵损失函数
深度学习中最常见的损失函数,交叉熵采用真实标签的预测概率的负对数似然。
创建一个数据样本y_hat,其中包含2个样本在3个类别的预测概率, 以及它们对应的标签y。 有了y,我们知道在第一个样本中,第一类是正确的预测; 而在第二个样本中,第三类是正确的预测。 然后使用y作为y_hat中概率的索引, 我们选择第一个样本中第一个类的概率和第二个样本中第三个类的概率。
y = torch.tensor([0, 2]) # 标签y 表示第一类和第三类
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y_hat[[0, 1], y] # 选择第一个样本中第一个类的概率和第二个样本中第三个类的概率tensor([0.1000, 0.5000])















 3128
3128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









