







论文地址:arxiv
摘要
作者提出了一种新型的混合 Mamba-Transformer 主干网络。通过重新设计 Mamba 公式,增强了其高效建模视觉特征的能力。
此外,作者还通过对 ViT 与 Mamba 消融研究,实验结果表明了:在最后几层为 Mamba 架构配备几个自注意力模块,可以极大地提高捕获长程空间依赖关系的建模能力。
最后,作者根据他们的发现,设计了一系列具有层次结构的 MambaVision 模型,最终取得了最佳的性能。
正文
Transformer 模型在视觉领域中已经成为了标准架构,但是其计算成本很高。之后 Mamba 模型改进了这个问题,它实现了线性的时间复杂度,并在不同的领域中超越过匹敌 Transformer。
但是基于 Mamba 架构的骨干网络对于需要全局感受野的计算机视觉任务依然有着一定的问题:
- 图像像素是二维的,所以不存在与顺序数据相同的顺序依赖性。同时,由于图像是二维的,所以需要更并行与集成的方式考虑。作者认为这导致了在处理空间数据时的低效性。
- Mamba 这样的自回归模型是逐步处理数据的,这限制了其在一次前向传播中捕捉与利用全局上下文的能力。但是视觉任务通常需要在理解整体图像的基础上对局部区域做准确的预测。
针对以上的问题,提出了 MambaVision 模型,其核心思想是通过重新设计 Mamba 模块并结合 Transformer 模块,形成一种混合的架构,从而来提升视觉任务的性能。该模型包含多分辨率架构,并利用基于卷积神经网络的残差模块快速提取较大分辨率特征。
经过实验,这个模型在 ImageNet-1 k 数据集上效果很好。
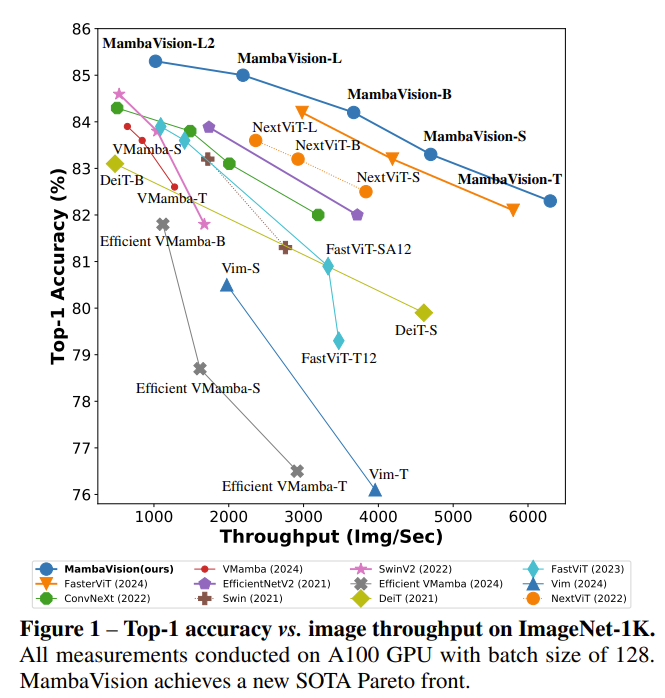
贡献
- 重新设计了更适合视觉的 Mamba 模块,提高了 Mamba 架构的准确性与图像吞吐量。
- 证明了在最后的阶段加入自注意力模块可显著提高模型捕捉全局上下文与长距离空间依赖的能力。
- 提出了 MambaVision 模型,这是一个混合了 Mamba 与 Transformer 的模型。
模型架构
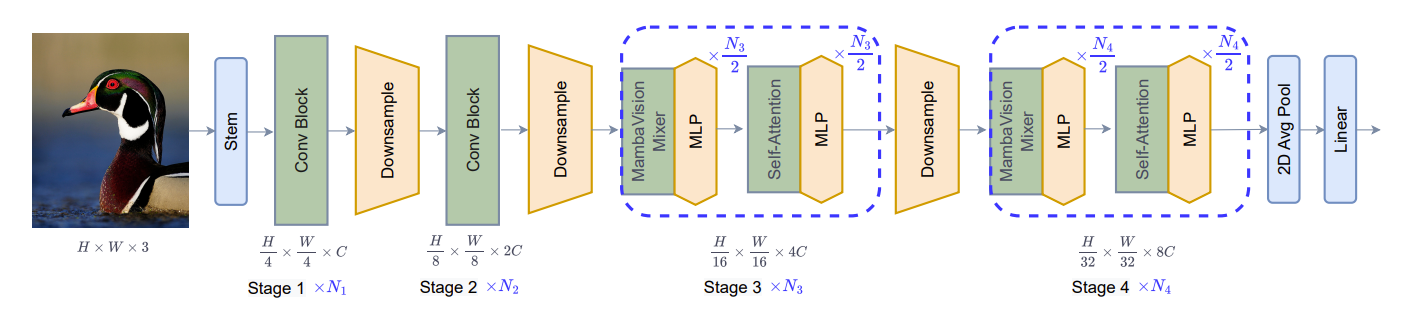
MambaVision 有四个不同的阶段组成,前两个阶段由基于 CNN 的层组成,用于在较高输入分辨率下的快速提取特征。而第三与第四阶段是由 MambaVision 与 Transformer 块组成。
对于尺寸为 H × W × 3 的图像,会先被转换为重叠的补丁,尺寸为 H/4 × W/4 × C,然后通过一个由两个连续的 3*3 的 CNN 层(步幅为 2)组成的 stem 投射到 C 维嵌入空间中。
下采样模块由一个批归一化的 3*3 的 CNN 层(步幅为 2)组成,可以将图像分辨率减半。
而 CNN 块采用以下残差块公式:
z
^
=
GELU
(
BN
(
Conv
3
×
3
(
z
)
)
)
\hat{z} = \text{GELU}(\text{BN}(\text{Conv}_{3 \times 3}(z)))
z^=GELU(BN(Conv3×3(z)))
z
=
BN
(
Conv
3
×
3
(
z
^
)
)
+
z
z = \text{BN}(\text{Conv}_{3 \times 3}(\hat{z})) + z
z=BN(Conv3×3(z^))+z
其中,GELU 为激活函数,BN 为批归一化。
层架构
如果输入 X ∈ R T ∗ C X \in R^{T*C} X∈RT∗C,其中序列长度为 T T T,嵌入维度为 C C C,则在阶段 3 与 4 中,第 n 层的输出可以通过以下公式计算:
X
^
n
=
Mixer
(
Norm
(
X
n
−
1
)
)
+
X
n
−
1
\hat{X}^n = \text{Mixer}(\text{Norm}(X^{n-1})) + X^{n-1}
X^n=Mixer(Norm(Xn−1))+Xn−1
X
n
=
MLP
(
Norm
(
X
^
n
)
)
+
X
^
n
X^n = \text{MLP}(\text{Norm}(\hat{X}^n)) + \hat{X}^n
Xn=MLP(Norm(X^n))+X^n
Norm 表示层归一化,而 Mixer 表示令牌混合。
MambaVision 混合模块
以下是其架构:
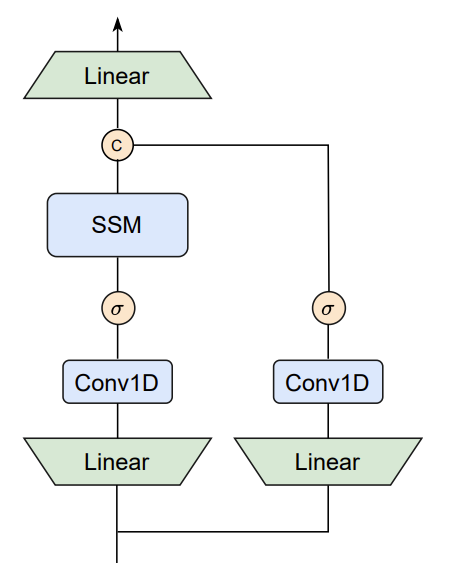
作者做了以下的改动:
- 使用常规的卷积代替了因果卷积(causal convolution)
- 增加了一个不含 SSM 的对称分支,这个分支由一个额外的卷积与 SiLU 激活函数(用于补偿由于 SSM 的顺序约束而丢失的内容)。
- 将两个分支的结果使用 Concat 连接并使用线性层投影(可以最终的特征表示结合了顺序与空间信息,利用两个优势)。
以下是公式的表示:
X
1
=
Scan
(
σ
(
Conv
(
Linear
(
C
,
C
2
)
(
X
in
)
)
)
)
X_1 = \text{Scan}(\sigma(\text{Conv}(\text{Linear}(C, \frac{C}{2})(X_{\text{in}}))))
X1=Scan(σ(Conv(Linear(C,2C)(Xin))))
X
2
=
σ
(
Conv
(
Linear
(
C
,
C
2
)
(
X
in
)
)
)
X_2 = \sigma(\text{Conv}(\text{Linear}(C, \frac{C}{2})(X_{\text{in}})))
X2=σ(Conv(Linear(C,2C)(Xin)))
X
out
=
Linear
(
C
2
,
C
)
(
Concat
(
X
1
,
X
2
)
)
X_{\text{out}} = \text{Linear} \left(\frac{C}{2}, C\right)(\text{Concat}(X_1, X_2))
Xout=Linear(2C,C)(Concat(X1,X2))
其中,
L
i
n
e
a
r
(
C
i
n
,
C
o
u
t
)
(
.
)
Linear(C_{in},C_{out})(.)
Linear(Cin,Cout)(.) 表示输入与输出维度分别为
C
i
n
C_{in}
Cin 与
C
o
u
t
C_{out}
Cout 的线性层。
S
c
a
n
Scan
Scan 是选择性扫描操作,
σ
\sigma
σ 表示 sigmoid 激活函数(SiLU)。Conv 表示一维卷积,Concat 表示连接操作。
我认为作者计算 X o u t X_{out} Xout 的公式写错了,应该是 X out = Linear ( C , C ) ( Concat ( X 1 , X 2 ) ) X_{\text{out}} = \text{Linear} \left(C, C\right)(\text{Concat}(X_1, X_2)) Xout=Linear(C,C)(Concat(X1,X2))
自注意力
使用通用自注意力机制,其公式为:
Attention
(
Q
,
K
,
V
)
=
Softmax
(
Q
K
T
d
h
)
V
\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_h}}\right)V
Attention(Q,K,V)=Softmax(dhQKT)V
Q
Q
Q,
K
K
K,
V
V
V 分别表示查询,键,值,
d
h
d_h
dh 是注意力头的数量。
模型评估
图像分类
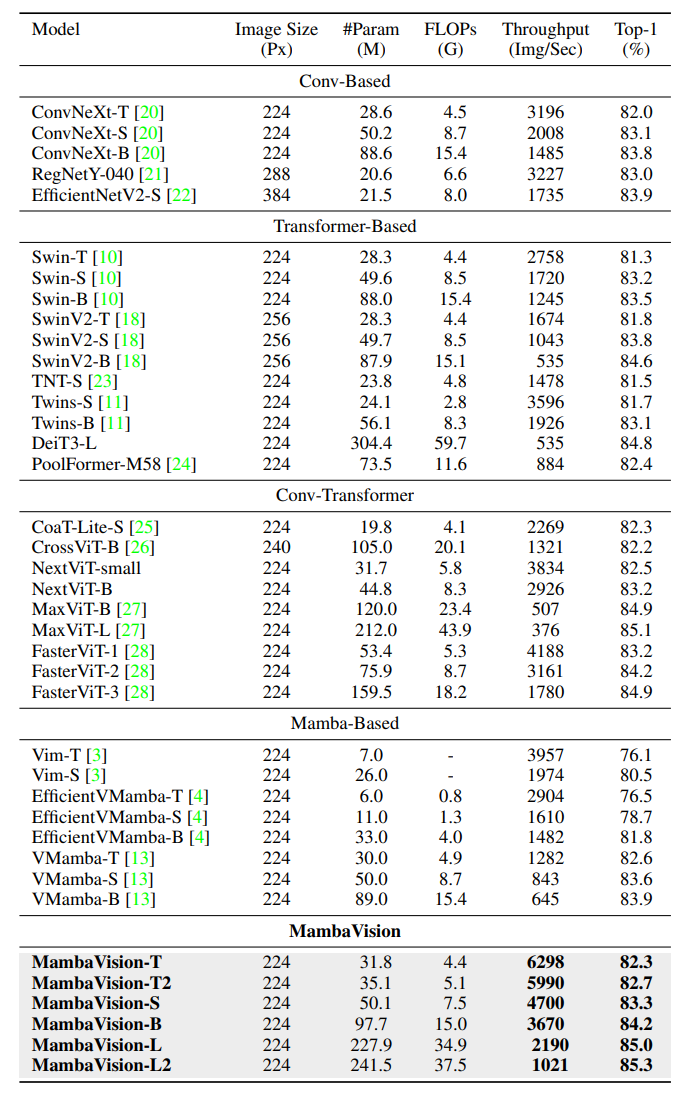
以下是在 ImageNet-1 k 上的结果。实验表示模型大幅度超过了之前的研究。也可以看出来,在准确的同时,计算量也比同等大小的模型低很多。
目标检测与分割
以下展示了 MS COCO 数据集上的目标检测与实例分割结果
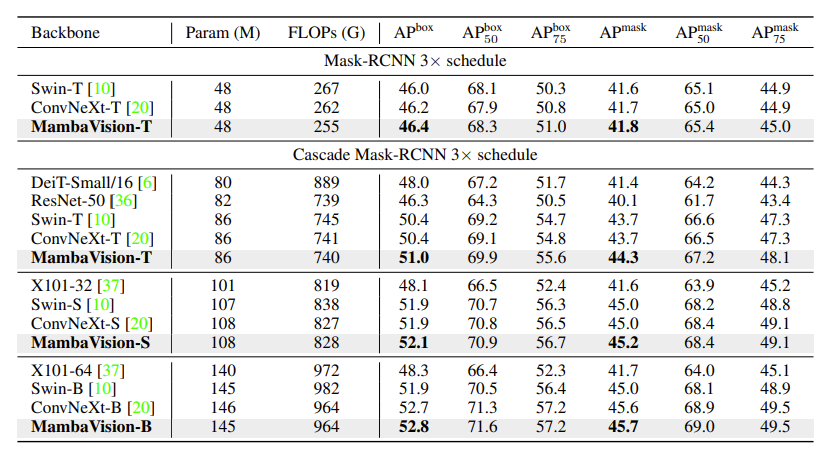
该实验验证了这个视觉骨干的有效性。
以下是在 ADE 20 K 数据集上进行的语义分割测试。
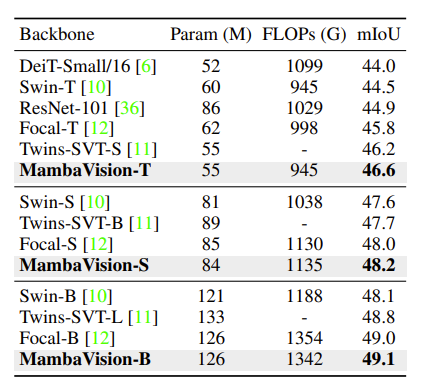
以上实验表明:MambaVision 作为不同视觉任务的骨干是可行的,尤其是在高分辨率下。
消融实验
Token Mixer 的设计
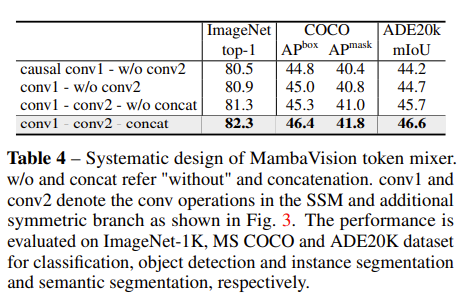
测试了以下的情况:
- 原始公式:SSM 分支中为因果卷积(casual Conv),无额外分支
- 将因果卷积换为普通的卷积
- 添加额外分支,使用与 Mamba 相同的门控机制
- 添加额外分支,使用连接(模型中使用的方法)
准确率不断提高。
混合模式

通过对 MambaVision 模块与 transformer 模块的不同排列测试,可以发现,前一半全是 MambaVision 模块,后一半全是 transformer 模块的准确率最高。















 7664
7664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









