






 SemEval2016的任务4聚焦于情感分析,包括消息极性分类、二分尺度推文分类、五分尺度推文分类、二分尺度推文量化和五分尺度推文量化。各子任务中,多数顶级团队采用了深度学习技术,如LSTM、CNN和词嵌入。在量化任务中,部分团队专门针对问题的量化特性进行了系统调整。
SemEval2016的任务4聚焦于情感分析,包括消息极性分类、二分尺度推文分类、五分尺度推文分类、二分尺度推文量化和五分尺度推文量化。各子任务中,多数顶级团队采用了深度学习技术,如LSTM、CNN和词嵌入。在量化任务中,部分团队专门针对问题的量化特性进行了系统调整。
SemEval2016 Sentiment Anaylisis
Introduction
区别概念
Ordinal Classification
对于此处的创新是将二分类问题变为三分类或者五分类问题Quantification
这里面的应用我们不限于对一个特定人的帖子进行情感分析,而是对于一个特定的话题来说,进行情感的分析
Task Definition(分问题的定义)
- Subtask A: Given
a tweet, predict whether it is ofpositive,negative, orneutralsentiment.- Subtask B: Given
a tweetknown to be about agiven topic, predict whether it conveys apositiveor anegativesentiment towards the topic.- Subtask C: Given
a tweetknown to be abouta given topic, estimate the sentiment it conveys towards the topic on afive-point scaleranging from HIGHLYNEGATIVE to HIGHLYPOSITIVE.- Subtask D: Given
a set of tweetsknown to be abouta given topic, estimate the distribution of the tweets in thePOSITIVEandNEGATIVEclasses.- Subtask E: Given
a set of tweetsknown to be about a given topic, estimate the distribution of the tweets across the five classes of afivepoint scale, ranging from HIGHLYNEGATIVE to HIGHLYPOSITIVE
Evaluation Measures
Participants and Results
- Subtask A (34 teams)
- Subtask B (19 teams)
- Subtask C (11 teams)
- Subtask D (14 teams)
- Subtask E (10 teams)
Subtask A: Message polarity classification
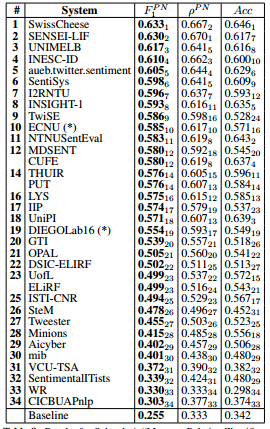
- The top-scoring team (SwissCheese1) used an
ensemble of convolutional neural networks,differing in their choice of filter shapes,pooling shapesandusage of hidden layers.Word embeddings generated viaword2vecwere also used, and theneural networks were trained by using distant supervision.- Out of the 10 top-ranked teams,
5teams(SwissCheese1, SENSEI-LIF2, UNIMELB3,INESC-ID4, INSIGHT-18) useddeep NNs of somesort, and 7 teams (SwissCheese1, SENSEI-LIF2,UNIMELB3, INESC-ID4, aueb.twitter.sentiment5,I2RNTU7, INSIGHT-18) used eithergeneral purposeortask-specificword embeddings,generated viaword2vecorGloVe.
Subtask B: Tweet classification according to a two-point scale
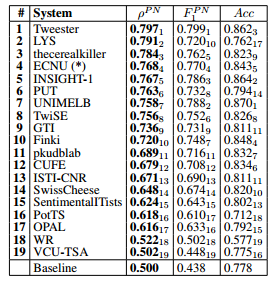
The top-scoring team (Tweester1) used a
combination of convolutional neural networks,topic modeling, andword embeddingsgenerated viaword2vec. Similar to Subtask A, the main trend among all participants is the widespread use of deep learning techniques.Out of the 10 top-ranked participating teams,
5 teams(Tweester1, LYS2, INSIGHT15, UNIMELB7, Finki10) usedconvolutional neural networks;3 teams(thecerealkiller3, UNIMELB7, Finki10) submitted systems usingrecurrent neural networks; and7 teams(Tweester1, LYS2, INSIGHT-15, UNIMELB7, Finki10) incorporated in their participating systems eithergeneral-purposeortask-specificword embeddings (generated via toolkits such as GloVe or word2vec).
Subtask C: Tweet classification according to a five-point scale
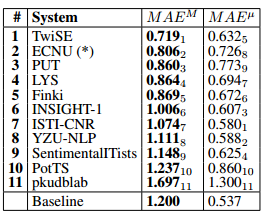
- The top-scoring team (TwiSE1) used a
singlelabel multi-class classifierto classify the tweets according to their overall polarity. In particular, they usedlogistic regressionthat minimizes the multinomial loss across the classes, with weights to cope with class imbalance. Note that they ignored the given topics altogether.- Only
2 of the 11participating teams tuned their systems toexploit the ordinal (as opposed to binary, or single-label multi-class) nature of this subtask. The two teams who did exploit the ordinal nature of the problem arePUT3, which uses an ensemble of ordinal regression approaches, andISTI-CNR7, which uses atree-based approach to ordinal regression. All other teams used general-purpose approaches for single-label multi-class classification, in many cases relying (as for Subtask B) onconvolutional neural networks,recurrent neural networks, andword embeddings
Subtask D: Tweet quantification according to a two-point scale
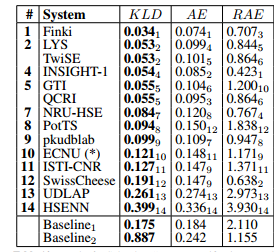
- The top-scoring team (Finki1) adopts an approach based on
“classify and count”,aclassification oriented(instead of quantification-oriented) approach, usingrecurrentandconvolutional neural networks, andGloVe word embeddings.- Indeed, only
5 of the 14participating teams tuned their systems to the fact that it deals withquantification(as opposed to classification). Among the teams who do rely on quantification-oriented approaches, teamsLYS2andHSENN14used an existingstructured prediction methodthat directly optimizesKLD; teamsQCRI5andISTI-CNR11useexisting probabilistic quantification methods; teamNRU-HSE7uses an existingiterative quantification methodbased oncost-sensitive learning. Interestingly, teamTwiSE2uses a “classify and count” approach aftercomparing it witha quantification oriented method (similar to the one used by teams LYS2 and HSENN14) on the development set, and concluding that the former works better than the latter.
All other teams used“classify and count” approaches, mostly based onconvolutional neural networksandword embeddings
Subtask E: Tweet quantification according to a five-point scale
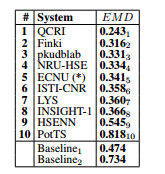
- Only
3 of the 10 participantstuned their systems to the specific characteristics of this subtask, i.e., to the fact that it deals withquantification(as opposed to classification) and to the fact that it has an ordinal (as opposed to binary) nature.- The top-scoring team (QCRI1) used a
novel algorithmexplicitly designed for ordinal quantification, that leverages an ordinal hierarchy of binary probabilistic quantifiers.- Team NRU-HSE4 uses an
existing quantification approachbased on cost-sensitive learning, and adapted it to the ordinal case.- Team ISTI-CNR6 instead used
a novel adaptation to quantification of a tree-based approachto ordinal regression.- Teams LYS7 and HSENN9 also used an
existing quantification approach, but did not exploit the ordinal nature of the problem.- The other teams mostly used approaches based on
“classify and count”(see Section 5.4), and viewed the problem assingle-label multi-class(instead of ordinal) classification; some of these teams (notably, team Finki2) obtained very good results, which testifies to the quality of the (general-purpose) features and learning algorithm they used.
Conclusion
值得研读的Paper:
每个任务的最高得分
* A:SwissCheese(Deriu et al., 2016)
* B:Tweester(Palogiannidi et al., 2016)
* C:TwiSE(Balikas and Amini, 2016)
* D:Finki(Stojanovski et al., 2016)
* E:QCRI(Da San Martino et al., 2016)
独具一格
* PUT3(Lango et al., 2016)
* ISTI-CNR(Esuli, 2016)
* LYS(Vilares et al., 2016)
* QCRI5(Da San Martino et al., 2016)
* NRU-HSE(Karpov et al., 2016)虽然相关的论文很多但是值得深入的不多,基本方法都是运用深度学习,在构建网络的时候不同。

















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









