






一、推荐的概述
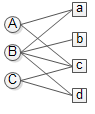
在推荐系统中,通常是要向用户推荐商品,如在购物网站中,需要根据用户的历史购买行为,向用户推荐一些实际的商品;如在视频网站中,推荐的则是不同的视频;如在社交网站中,推荐的可能是用户等等,无论是真实的商品,还是视频,再或者是用户,都可以假设成一种物品,如下图所示:
(图片来自参考文献)
在上图中,左侧的A,B,C表示的是三个用户,右侧的a,b,c,d表示的是四个商品,中间的连线表示用户与商品之间有过行为,或者是购买或者是打分,推荐的目的是从商品列表中向指定的用户推荐用户未行为过的商品。
推荐的算法有很多,包括协同过滤(基于用户的协同过滤和基于物品的协同过滤)以及其他的一些基于模型的推荐算法。
二、基于图的推荐算法PersonalRank算法
1、PersonalRank算法简介
在协同过滤中,主要是将上述的用户和商品之间的关系表示成一个二维的矩阵(用户商品矩阵)。
而在基于图的推荐算法中,将上述的关系表示成二部图的形式,为用户A推荐商品,实际上就是计算用户A对所有商品的感兴趣程度。
PersonalRank算法对通过连接的边为每个节点打分,具体来讲,在PersonalRank算法中,不区分用户和商品,因此上述的计算用户A对所有的商品的感兴趣的程度就变成了对用户A计算各个节点B,C,a,b,c,d的重要程度。
PersonalRank算法的具体过程如下(对用户A来说):
初始化:
PR(A)=1,PR(B)=0,⋯,PR(d)=0开始在图上游走,每次选择PR值不为 0 的节点开始,沿着边往前的概率为
α ,停在当前点的概率为 1−α :- 首先从A开始,从A到a和c的概率为 0.5 ,则此时a和c的PR值为: PR(a)=PR(c)=α×PR(A)×0.5 ,A的PR值变成了 1−α
- 此时PR值不为0的节点为A,a,c,则此时从这三点出发,继续上述的过程,直到收敛为止。
由此可以得出以下的PR计算方法:
PR(v)=⎧⎩⎨⎪⎪α×∑v′∈in(v)PR(v′)|out(v′)|(1−α)+α×∑v′∈in(v)PR(v′)|out(v′)| if v≠vu if v=vu
2、实验过程
2.1、实验结果:

根据最终的商品的打分,我们对其进行排序,由于A用户对商品c和商品a有过行为,因此根据打分,为用户A推荐商品d。
2.2、实验代码
#coding=utf-8
def PersonalRank(G, alpha, root, max_step):
rank = dict()
for x in G.keys():
rank[x] = 0
rank[root] = 1
for k in range(max_step):
print str(k)
tmp = dict()
for x in G.keys():
tmp[x] = 0
for i, ri in G.items():
for j, wij in ri.items():
if j not in tmp:
tmp[j] = 0
tmp[j] += alpha * rank[i] / (1.0 * len(ri))
if j == root:
tmp[j] += (1 - alpha)
# coverage
check = []
for k in tmp.keys():
check.append(tmp[k] - rank[k])
if sum(check) <= 0.0001:
break
rank = tmp
for n in rank.keys():
print "%s:%.3f \t"%(n, rank[n]),
print
return rank
if __name__ == '__main__' :
G = {'A' : {'a' : 1, 'c' : 1},
'B' : {'a' : 1, 'b' : 1, 'c':1, 'd':1},
'C' : {'c' : 1, 'd' : 1},
'a' : {'A' : 1, 'B' : 1},
'b' : {'B' : 1},
'c' : {'A' : 1, 'B' : 1, 'C':1},
'd' : {'B' : 1, 'C' : 1}}
items_dict = {'a':0,'b':0,'c':0,'d':0}
rank = PersonalRank(G, 0.85, 'A', 50)
for k in items_dict.keys():
if k in rank:
items_dict[k] = rank[k]
#sort:
result = sorted(items_dict.items(), key = lambda d: d[1], reverse=True)
print "\nThe result:"
for k in result:
print "%s:%.3f \t"%(k[0], k[1]),
print
参考文献
- 《推荐系统实践》















 7701
7701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









