






目录
一:深度置信网络
1.基本概念
深度置信网络是神经网络的一种。既可以用于非监督学习,类似于一个自编码机;也可以用于监督学习,作为分类器来使用。从非监督学习来讲,其目的是尽可能地保留原始特征的特点,同时降低特征的维度。从监督学习来讲,其目的在于使得分类错误率尽可能地小。而不论是监督学习还是非监督学习,深度置信网络的本质都是特征的过程,即如何得到更好的特征表达。

2.玻尔兹曼机:
(1)特点每个随机变量都是二值的0,1
(2) 所有节点都是全连接的
(3)两个节点之间的相互影响都是对称的
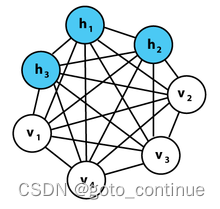
工作方式:
玻尔兹曼机在输入节点之间有连接。每个节点都连接到所有其他节点,无论它们是输入节点还是隐藏节点。这使他们能够在彼此之间共享信息并自行生成后续数据。只会测量可见节点上的内容,而不是隐藏节点上的内容。提供输入后,玻尔兹曼机器能够捕获数据之间的所有参数、模式和相关性。正因为如此,它们被称为深度生成模型,属于无监督深度学习。
作用:
玻尔兹曼机的主要目的是优化问题的解决方案。为此,它会优化与分配给它的特定问题相关的权重和数量。当主要目的是创建映射并从数据中的属性和目标变量中学习时,就会使用这种技术。如果寻求识别数据中的底层结构或模式,则该模型的无监督学习方法被认为更有用。
3.受限玻尔兹曼机

如图,在每一个隐藏节点,每个输入 x 都与对应的权重 w 相乘。也就是说,一个输入 x 会拥有 12 个权重(4 个输入节点×3 个输出节点)。两层之间的权重总会形成一个矩阵,矩阵的行数等于输入节点的个数,列数等于输出节点的个数。每个隐藏节点会接收 4 个与对应权重相乘的输入。这些乘积的和再一次与偏置相加,并将结果馈送到激活函数中以作为隐藏单元的输出。
如果这两层是更深网络的一部分,那么第一个隐藏层的输出会被传递到第二个隐藏层作为输入,从这里开始就可以有很多隐藏层,直到它们增加到最终的分类层。对于简单的前馈网络,RBM 节点起着自编码器的作用,除此之外,别无其它。
二:卷积神经网络
基本概念
卷积神经网络可以有数十层或数百层,每层都学习检测图像的不同特征。滤波器以不同的分辨率应用于每个训练图像,并且每个卷积图像的输出用作下一层的输入。滤镜可以从非常简单的特征(如亮度和边缘)开始,然后增加唯一定义对象的特征的复杂性。
1.CNN
CNN 由输入层、输出层和介于两者之间的许多隐藏层组成。这些层执行更改数据的操作,目的是学习特定于数据的特征。三个最常见的层是卷积、激活或 ReLU 和池化。
卷积
这个过程我们可以理解为我们使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
在具体应用中,往往有多个卷积核,可以认为,每个卷积核代表了一种图像模式,如果某个图像块与此卷积核卷积出的值大,则认为此图像块十分接近于此卷积核。如果我们设计了6个卷积核,可以理解:我们认为这个图像上有6种底层纹理模式,也就是我们用6中基础模式就能描绘出一副图像。
池化
池化通过执行非线性下采样来简化输出,从而减少网络需要学习的参数数量。池化层相比卷积层可以更有效的降低数据维度,这么做不但可以大大减少运算量,还可以有效的避免过拟合。
ReLU
整流线性单元 (ReLU) 通过将负值映射到零并保持正值,允许更快、更有效的训练。这有时称为激活,因为只有激活的功能才会传递到下一层。
激活
这个部分就是最后一步了,经过卷积层和池化层处理过的数据输入到全连接层,得到最终想要的结果。

2.RNN
基本概念
递归神经网络 (RNN) 是人工神经网络的两大类型之一,其特征在于其层之间的信息流方向。与单向前馈神经网络相比,它是一个双向人工神经网络,这意味着它允许某些节点的输出影响对相同节点的后续输入。它们使用内部状态(内存)处理任意输入序列的能力使它们适用于未分段、连接的手写识别或语音识别等任务。术语“递归神经网络”用于指具有无限脉冲响应的网络类,而“卷积神经网络”是指有限脉冲响应类。这两类网络都表现出时间动态行为。有限脉冲循环网络是可以展开并替换为严格前馈神经网络的有向无环图,而无限脉冲循环网络是无法展开的有向循环图。
算法
递归神经网络利用时间反向传播 (BPTT) 算法来确定梯度,这与传统的反向传播略有不同,因为它特定于序列数据。BPTT的原理与传统反向传播相同,其中模型通过计算从输出层到输入层的误差来训练自己。这些计算使我们能够适当地调整和拟合模型的参数。BPTT与传统方法的不同之处在于,BPTT在每个时间步对误差求和,而前馈网络不需要对误差求和,因为它们不在每个层之间共享参数。
常用激活函数
正如 Learn 关于神经网络的文章中所讨论的,激活函数确定是否应该激活神经元。非线性函数通常将给定神经元的输出转换为 0 到 1 或 -1 和 1 之间的值。

缺点
通过这个过程,RNN往往会遇到两个问题,称为梯度爆炸和梯度消失。这些问题由梯度的大小定义,梯度是损失函数沿误差曲线的斜率。当梯度太小时,它会继续变小,更新权重参数,直到它们变得不重要(即 0)。发生这种情况时,算法不再学习。当梯度太大时,会发生梯度爆炸,从而产生不稳定的模型。在这种情况下,模型权重将变得太大,最终将表示为 NaN。这些问题的一个解决方案是减少神经网络中隐藏层的数量,消除RNN模型中的一些复杂性。
3.变体 RNN 架构
双向递归神经网络 (BRNN): 这些是RNN的变体网络架构。虽然单向 RNN 只能从以前的输入中提取来预测当前状态,但双向 RNN 会提取未来的数据以提高其准确性。如果我们回到本文前面的“感觉在天气下”的例子,如果模型知道序列中的最后一个词是“天气”,它可以更好地预测该短语中的第二个单词是“under”。
长短期记忆(LSTM):这是一种流行的RNN架构,由Sepp Hochreiter和Juergen Schmidhuber引入,作为梯度消失问题的解决方案。在他们的论文(PDF,388 KB)(链接位于IBM外部)中,他们致力于解决长期依赖性的问题。也就是说,如果影响当前预测的先前状态不是最近的过去,则RNN模型可能无法准确预测当前状态。举个例子,假设我们想预测以下斜体字,“爱丽丝对坚果过敏。她不能吃花生酱。坚果过敏的背景可以帮助我们预测不能吃的食物含有坚果。但是,如果该上下文是之前的几句话,那么RNN将很难甚至不可能连接信息。为了解决这个问题,LSTM在神经网络的隐藏层中具有“单元”,它们有三个门 - 输入门,输出门和遗忘门。这些门控制预测网络中输出所需的信息流。例如,如果性别代词(如“她”)在前面的句子中多次重复,则可以将其从单元格状态中排除。
门控循环单元 (GRU): 这种RNN变体类似于LSTM,因为它也可以解决RNN模型的短期记忆问题。它不是使用“单元状态”来调节信息,而是使用隐藏状态,而不是三个门,它有两个 - 一个重置门和一个更新门。与 LSTM 中的门类似,重置和更新门控制要保留的信息量和信息量。
三:案例实践---ResNet经典卷积神经网络
ResNet经典卷积神经网络是近几年来的经典图像分类网络,该系列网络有不同的层数,从低到高分别有resnet18、resnet34、resnet50、resnet101、resnet152等,本案例将使用renet18网络来实现手写数字识别。
1. 加载数据集
由于resnet18网络参数量比LeNet-5的要大,因此训练过程对显存就有更大的要求,我们可能无法将整个手写数字识别的6万个样本一次性加载进来进行训练,因此我们要分批次加载训练集进行训练。
使用torch.utils.data.DataLoader工具可以很简单将数据集构造为一个数据生成器,每次只取出一小批的数据,实现代码如下,详情请查看代码注释。
import os
import torch
from torchvision import datasets, transforms
mnist_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.Grayscale(3),
transforms.ToTensor(),
transforms.Normalize((0.1307, 0.1307, 0.1307), (0.3081, 0.3081, 0.3081)),
]) # 由于resnet系列网络要求图片输入的尺寸是3*244*244,而MNIST数据集图片的尺寸是1*28*28,所以我们要构造一个图像变换操作,将MNIST的图片变换成3*244*244
train_batch_size = 64 # 训练集的批次大小
test_batch_size = 256 # 测试集的批次大小
torch.manual_seed(0)
datasets_dir = '../datasets'
if not os.path.exists(datasets_dir):
os.makedirs(datasets_dir)
import moxing as mox
if not os.path.exists(os.path.join(datasets_dir, 'MNIST_data.zip')):
mox.file.copy('obs://modelarts-labs-bj4/course/hwc_edu/deep_learning/datasets/MNIST_data.zip',
os.path.join(datasets_dir, 'MNIST_data.zip'))
os.system('cd %s; unzip MNIST_data.zip' % (datasets_dir))
train_dataset = datasets.MNIST(os.path.join(datasets_dir, 'MNIST_data'), train=True, download=True, transform=mnist_transform) # 加载训练集
test_dataset = datasets.MNIST(os.path.join(datasets_dir, 'MNIST_data'), train=False, download=True, transform=mnist_transform) # 加载测试集
train_loader = torch.utils.data.DataLoader(train_dataset, shuffle=True, batch_size=train_batch_size) # 构造训练集批次生成器
test_loader = torch.utils.data.DataLoader(test_dataset, shuffle=True, batch_size=test_batch_size) # 构造测试集批次生成器2. 两行代码定义Resnet18网络
torchvision中定义了很多常用的网络结构,直接调用即可完成网络结构的定义。需要注意的一点就是,在调用torchvision的类进行了网络结构的定义后,要修改网络的最后一层全连接层,将该层的输出节点数改成实际分类任务的类别数,具体代码如下所示,详情请查看代码注释。
import torchvision
from torch import nnnet = torchvision.models.resnet18(pretrained=True) # 一行代码实现resnet18的网络结构定义,pretrained=True表示将加载resnet18的官方预训练参数文件
net.fc = nn.Linear(net.fc.in_features, out_features=10) # net.fc就是指模型的最后一层全连接层,net.fc.in_features是指该层的输入节点数,out_features是指该层的输出节点数,也就是要分类的类别数,MNIST手写数字识别是十分类任务,因此填写为103. 定义评价函数
由于网络结构是使用封装好的类,因此我们需要在类外单独定义评价函数
由于训练集和测试集都是分批次进行预测,所以我们要先统计每个批次中预测正确的样本,最后等所有批次统计完成后才能计算准确率
def evaluate(pred_y, true_y):
# pred_labels = torch.argmax(pred_y, dim=1)
# acc = (pred_labels == true_y).float().mean()
pred_labels = pred_y.argmax(dim=1, keepdim=True)
correct_num = pred_labels.eq(true_y.view_as(pred_labels)).sum().item()
return correct_num4. 交叉熵损失函数
与上一节代码一致
import torch.nn.functional as F
loss_fun = F.cross_entropy5. 实现GPU训练的梯度下降算法
import torch.nn.functional as F
loss_fun = F.cross_entropy6. 实现训练函数
def train(net, train_loader, test_loader, max_epochs=100):
import gc
train_losses = []
test_losses = []
train_accs = []
test_accs = []
for epoch in range(1, max_epochs + 1):
net.train() # 切换为训练模式
train_loss = 0.0
train_correct_num = 0
for iter_idx, (train_x_batch, train_y_batch) in enumerate(train_loader):
train_x_batch, train_y_batch = train_x_batch.to(device), train_y_batch.to(device)
pred_y_train_batch = net.forward(train_x_batch) # 前向传播
current_train_loss = loss_fun(pred_y_train_batch, train_y_batch) # 计算损失
train_loss += current_train_loss.item()
train_correct_num += evaluate(pred_y_train_batch, train_y_batch)
# 计算梯度,更新权值
current_train_loss.backward()
optimizer.step()
optimizer.zero_grad()
if iter_idx % 50 == 0:
print('epoch: %d, iter_idx: %d, train_loss: %.4f' % (epoch, iter_idx, current_train_loss.item()))
train_loss /= len(train_loader.dataset)
train_acc = float(train_correct_num) / len(train_loader.dataset)
if (epoch == 1) or (epoch % 200 == 0):
net.eval() # 切换为评价模式,评价模式不计算梯度,计算更快
test_loss = 0.0
test_correct_num = 0.0
for iter_idx, (test_x_batch, test_y_batch) in enumerate(test_loader):
test_x_batch, test_y_batch = test_x_batch.to(device), test_y_batch.to(device)
pred_y_test_batch = net.forward(test_x_batch)
test_loss += loss_fun(pred_y_test_batch, test_y_batch).item()
test_correct_num += evaluate(pred_y_test_batch, test_y_batch)
test_loss /= len(test_loader.dataset)
test_acc = float(test_correct_num) / len(test_loader.dataset)
print('epoch %d, train_loss %.4f, test_loss %.4f, train_acc: %.4f, test_acc: %.4f' % (epoch, train_loss, test_loss, train_acc, test_acc))
return train_losses, test_losses, train_accs, test_accs7. 开始训练
代码基本与上一节一致,只是将max_epochs改成了1
import time
start_time = time.time()
max_epochs = 1
train_losses, test_losses, train_accs, test_accs = train(net, train_loader, test_loader, max_epochs=max_epochs)
print('cost time: %.1f s' % int(time.time() - start_time))从上面的输出结果,可以看到ResNet18模型仅训练一个epoch,耗时仅150秒左右,就在手写数字识别任务的测试集上达到了0.99以上的准确率。
该准确率可以达到应用水平,下面将保存模型、并加载模型进行批量图片预测,看看真实的预测效果如何。
8. 保存模型
torch.save(net, './resnet18_mnist.pth')9. 加载模型
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
resnet18_mnist = torch.load('./resnet18_mnist.pth', map_location=device)10. 进行批量图片预测
模型训练时,对训练图片进行了图像转换操作,加载图片进行测试时,也需要同样的转换操作,下面的代码直接本案例开头第一步中的代码
from torchvision import transforms
mnist_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.Grayscale(3),
transforms.ToTensor(),
transforms.Normalize((0.1307, 0.1307, 0.1307), (0.3081, 0.3081, 0.3081)),
]) # 由于resnet系列网络要求图片输入的尺寸是3*244*244,而MNIST数据集图片的尺寸是1*28*28,所以我们要构造一个图像变换操作,将MNIST的图片变换成3*244*244import os
import numpy as np
from glob import glob
from PIL import Image
datasets_dir = '../datasets'
test_img_dir = os.path.join(datasets_dir, 'MNIST_data/test_imgs')
files = glob(os.path.join(test_img_dir, '*.jpg'))
resnet18_mnist.eval() # 将模型转换为评价模式
pred_labels = []
show_img = np.zeros((28, 1), dtype= np.uint8)
for file_path in files:
src_img = Image.open(file_path) # 加载单张图片
img = mnist_transform(src_img) # 对图片进行图像转换
img = img.unsqueeze(0)
img = img.to(device)
pred_y = resnet18_mnist.forward(img)
pred_label = torch.argmax(pred_y)
pred_labels.append(pred_label.item())
show_img = np.hstack((show_img, np.array(src_img)))
print(pred_labels) # 打印预测结果
Image.fromarray(show_img) # 显示预测图片[4, 6, 9, 0, 2, 9, 9, 4, 0, 6, 6, 8, 2, 8, 1, 9, 1, 1, 5, 3]
从上面的结果可以看到,20张图片中,仅一张手写不太规范的数字“9”被识别成了“4”,其他图片全部预测正确。














 1298
1298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









