







主要参考文献及其收获
Unpaired image-to-image translation using cycle-consistent adversarial networks
Deep retinex decomposition for low-light enhancement,” in BMVC, 2018.分解网络
U-Net: Convolutional Net-works for Biomedical Image Segmentation U-net网络
1、使用LOL数据集训练分解网络比较合适
2、循环损失函数
3、增加实例验证实验结果的有效性,目前比较靠谱。
Abstract
摘要—由于基于视觉的感知方法通常建立在正常光线假设的基础上,因此将它们部署到弱光环境中会有严重的安全问题。最近,已经提出了基于深度学习的方法来通过惩罚弱光和正常光图像的像素级损失来增强弱光图像。然而,它们大多存在以下问题:1)需要对弱光和正常光图像进行训练,2)对暗图像的性能差,3)噪声放大。为了缓解这些问题,本文提出了一种两阶段无监督方法,将弱光图像增强分解为预增强和后细化问题。在第一阶段,我们用传统的基于视网膜的方法对弱光图像进行预增强。在第二阶段,我们使用通过对抗训练学习的细化网络来进一步提高图像质量。实验结果表明,在四个基准数据集上,我们的方法优于以往的方法。此外,我们表明,我们的方法可以显著提高特征点匹配和在弱光条件下的同时定位和映射。
总结:
1、无监督学习,不需要成对图像
2、增强分为预增强和后细化
3、增加实例,证明实验的有效性(特征点匹配 同时定位和映射)
introduction
写作方法:基于视觉的算法为机器人在各种任务上的感知带来了显著的进展,例如同时定位和映射(SLAM) [2]、对象识别[10]、深度估计[12]、[18]和语义分割[23]、[21]、[20]等。然而,这些算法是建立在假设图像是在良好的照明条件下捕获的基础上的。当将它们部署到现实世界的弱光环境中时,它引起了严重的关注。
基于深度学习的方法已经被不断地提出来增强弱光图像。这些方法以监督的方式学习具有成对的弱光和相应的正常光图像的卷积网络。虽然我们已经看到他们取得了很大的进步,但主要有三个问题阻碍了这些基于学习的方法在现实世界中的部署:
有监督学习所面临的问题:
1.首先,从真实场景中同时获取弱光图像及其对应的正常光线的图像是一项挑战。或者,研究人员引入使用合成的弱光图像,然而,由于域转换,从他们那里学习的模型不能直接部署到现实世界的场景中。
2.第二,光线极弱的情况很难处理。基于深度学习的方法已经证明了对于稍微弱光的图像的令人满意的性能,但是,它们对于暗图像表现不好。
3.此外,由于低信噪比,微光图像通常会受到强噪声的影响,这也给增强低照度图像带来了困难。同时增强照明和去噪是一个不小的问题,因为它们通常在不同的范式中进行表述和解决。增强亮度的同时会引起噪声放大。为了缓解上述困难,本文将弱光分解为增强前和细化后两个子问题,并提出了一种两阶段方法来更准确地增强弱光图像。具体来说,在第一阶段,我们基于视网膜理论增强从弱光图像分解的光照图。为此,我们采用了基于色调映射的方法[1]。在第二阶段,我们设计了一个细化网络,以进一步提高第一阶段获得的预增强图像的图像质量。我们设计了一个综合的损失函数,它结合了图像内容的损失、感知质量、总变化和对抗损失。这一阶段有助于改善图像质量,尤其是噪声抑制。我们的两阶段策略即使对于暗图像输入也表现出令人满意的性能,使用两阶段方法解决 增强亮度和噪声抑制。基于监督学习的方法已经在这项任务上取得了显著的进展,学习所需的弱光和正常光图像对使得它们难以应用于现实世界的场景。成对图像难以获取,人工的在转换的现实,场景效果差。
贡献:
出了一种简单的两阶段无监督方法,对弱光图像进行预增强和后细化增强。它优于最先进的方法,包括基于监督学习的方法和基于非监督学习的方法。此外,我们展示了我们的方法的两个应用,其中我们证明了它可以归档更精确的特征点匹配,并且可以进一步无缝地应用于弱光条件下的SLAM。
model
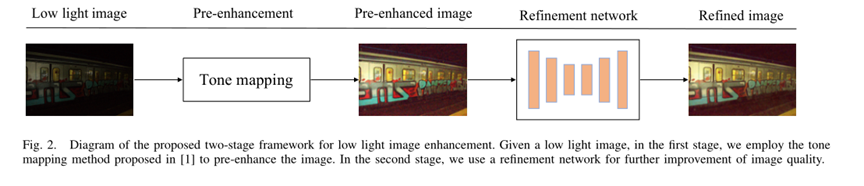
考虑到同时进行光照增强和去噪的困难,将弱光图像增强直接公式化为一个学习问题很难获得令人满意的性能。因此,我们提出了一个两阶段框架,执行预增强和后细化以获得更好的性能。提出的框架如图2所示。给定弱光图像,我们首先增强从弱光输入分解的照明图。然后,预增强的图像被输入到细化网络,以进一步抑制噪声并提高整体质量。我们两阶段方法的细节如下所示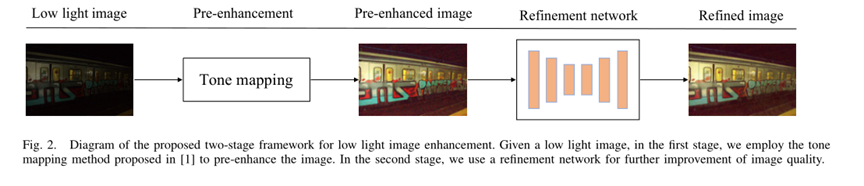
pre-enhancement
视网膜理论:![]()
我们采用自适应色调映射[1]来增强光照图
Y0表示来自X的预增强图像,Lw是X的灰度;lgi是全局适应输出,其计算公式如下:
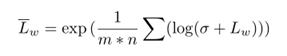
在光照增强方面,与许多基于深度学习的方法相比,预增强可以产生有竞争力的性能。然而,另一方面,它将极大地放大噪声,如图3的第二行所示。为了解决这个问题,我们使用了一个网络来进一步细化以提高图像质量。
Post-refinement-u-net网络
由于实际应用中很难获得弱光和正常光的成对图像,我们设计了一个综合损失函数,可以用来以无监督的方式训练网络。

损失函数:第一项是重建损失,它使图像的像素损失最小化。它确保了细化图像和预增强图像之间图像内容的一致性。第二项感知损失来约束VGG [30]的特征空间中的损失(经常使用),其表示为:

抑制噪声:TV损失,ltv有助于降低噪声,但也会导致图像结构的模糊效应。因此,我们使用一个对抗性的损失来鼓励精细的图像像清晰的正常光图像一样接近。

ltv有助于降低噪声,但也会导致图像结构的模糊效应。因此,我们使用一个对抗性的损失来鼓励精细的图像像清晰的正常光图像一样接近。在[14]之后,我们使用相对论鉴别器结构[15]作为鉴别网络,它是完全卷积的,可以处理任何大小的输入。那么对抗损失由下式给出:
![]()

EXPERIMENTS
考虑到同时进行光照增强和去噪的困难,将弱光图像增强直接公式化为一个学习问题很难获得令人满意的性能。因此,我们提出了一个两阶段框架,执行预增强和后细化以获得更好的性能。提出的框架如图2所示。给定弱光图像,我们首先增强从弱光输入分解的照明图。然后,预增强的图像被输入到细化网络,以进一步抑制噪声并提高整体质量。我们两阶段方法的细节如下所示。
A. Retinex decomposition network 视网膜分解
图像被分解成反射率R和照度I两部
R:反射率:这部分有图像的颜色信息。这是一个3通道图像,其尺寸与原始图像相似。我们假设这一部分在单个场景/对象的不同照明条件下是一致的。
照明I:这是一个单通道图像,代表一个图像的照明效果。
定义 从S-low到S-high 的网络为G
定义 从S-high到S-low 的网络为F
深度视网膜分解网络。G1和f1都是使用LOL数据集[19]训练的,该数据集由光线充足和光线不足的彩色图像对组成。
注:分解需要光照不同变化,所以LOL数据集特别适合。

增强是使用神经网络完成的。该架构的灵感来自于U-Net ,其对U-Net的修改见表1。
该CNN以R和I的串联作为输入(不同于U-Net)。这将输出光照图(照明地图的增强版本)。由于很难找到具有低照度和良好照度图像对的数据集,使用成对数据集学习技术来训练增强网络是不实际的。因此,我们使用一个不成对的数据集和一个生成对抗网络来训练增强网络。

循环一致性:
为了增强训练过程,我们使用了两个GANs [4],它们将从弱光图像生成明亮的图像,反之亦然。我们使用如图1所示的这些GANs,通过对抗损失来保持周期的一致性[21]。这减小了生成的图像和预期图像分布之间的距离。
G1、G2、f1和F2是可训练组件(基于UNet架构),而G3和F3是不可训练组件

损失函数的想法:
第一部分:考虑正向反向的周期一致性损失-
从low-high-low 正向
从high-low-high 反向

第二部分:考虑反射图都是一样的
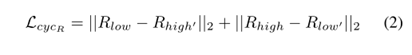
总的损失函数:

RESULTS AND DISCUSSION
A.性能指标 SSIM NIQE
B. Retinex decomposition
R-low 和R-high可反映效果
C. GAN based illumination enhancement
与普通的GAN 网络来说CycleGAN
产生更好的照明增强是显而易见的
四种不同的GAN 网络
G -a普通的GAN 网络
G-b 监督数据,使用retinexnet
G-ca 使用retinex aware GAN pipeline.
G使用视网膜感知CycleGAN管道增强弱光图像

1行:弱光输入图像。
第2行:光线充足的地面真相。
第3行:GAN增强图像。
第4行:Retinexnet增强图像。
第5行:基于retinex的GAN增强图像。
第6行:基于视网膜的CycleGAN(我们的)增强图像

结论
通过不成对、成对数据集训练网络
结合CNN 和 GAN
未来展望:
对于不同的网络,使用了单一的数据集进行训练,可以结合起来一同训练















 1002
1002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









