







综述
因为我个人最近在从事可能是AI领域对性能挑战最大的方向,自动驾驶领域,所以对整个深度学习训练的优化尤为关注,最近一直在学习相关内容,谨以此篇文章做一个总结。
我一直很看好深度学习训练优化这个方向,因为从大的环境上来看,似乎大模型会成为未来的一个趋势,目前以Google、OpenAI、阿里等厂商为代表的一系列头部的AI研究机构,已经把模型尺寸做到十万亿参数级别,明年应该可以达到百万亿参数,总体呈指数倍增长态势。而核心计算芯片的性能,却无法保证指数倍增长。
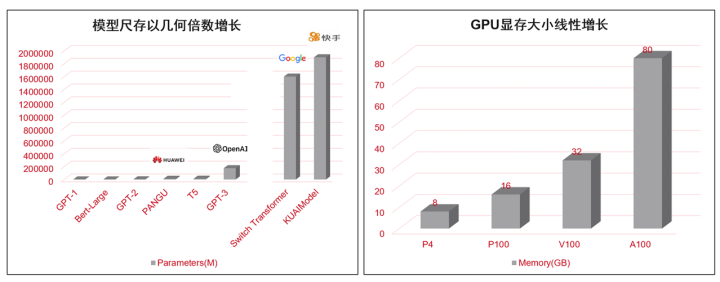
(上图因为制作时间较久,具体数字可能存在偏差)
所以,未来在人工智能领域所面对的一个主要矛盾就是指数倍增长的算力需求与线性增长的硬件计算能力的矛盾。而深度学习训练优化技术,是解决这样矛盾的一个关键。深度学习训练优化技术,又分为主观和客观性两个方面,有模型开发者的主动选择,用什么样的并行化模式,怎样处理通信算子,也有来自客观的优化,比如框架的编译优化。本文将尝试对常见的优化技术做一个概述。
具体结构如下:

分布式策略优化
前面介绍了在大模型时代,算力往往会成为短板,那么如何解决算力问题,比较好的方案就是并行化计算,或者说是分布式计算。分布式计算有许多种策略组成,常见的分布式策略有数据并行、模型并行、流水并行、算子并行。
1、数据并行[1]
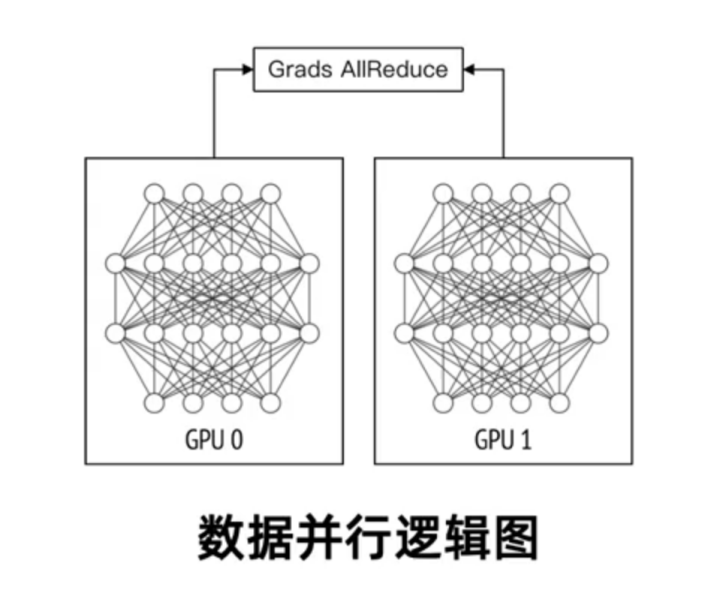
数据并行是比较常见的并行化计算逻辑,是将训练数据做打散和分片,然后每张GPU卡取一部分数据进行计算,每张GPU卡保存着全部的模型信息,通过All Reduce的方式进行梯度的更新,这里涉及到很多通信优化的方案,我们下一部分通信优化模块会介绍。数据并行经常跟模型并行、流水并行等模式一起使用。
开源的一些框架,比如Uber开源的Horovod对数据并行及其它并行方式提供了很好的支持。

2、模型并行(算子拆分)[2]
当一些模型的部分模块计算量明显高于其它模块的时候,会使用到算子并行的策略。举个例子,比如Resnet模型做图像分类,当分类器的类别极大,比如要做几十万类别的区分,那么全连接层会变得特别的大。如下图所示。

分类数为10 W时,ResNet50部分的模型权重大小89.6 MB,全连接层FC(Fully Connected Layer)部分的模型权重大小为781.6 MB,是前者的8.7倍。当采用数据并行进行分布式训练时,在后向阶段(Back Propagation过程),FC部分计算得到梯度后,立刻通过AllReduce进行梯度同步,同时ResNet50部分的梯度会继续进行后向计算。然而由于FC部分同步的梯度过大,当ResNet50部分的梯度计算完成时,FC部分的梯度通常还在通信过程中。因此,FC部分的梯度同步无法良好地与ResNet50的后向计算Overlap,导致整轮迭代过程中的通信占比十分高,性能低下。
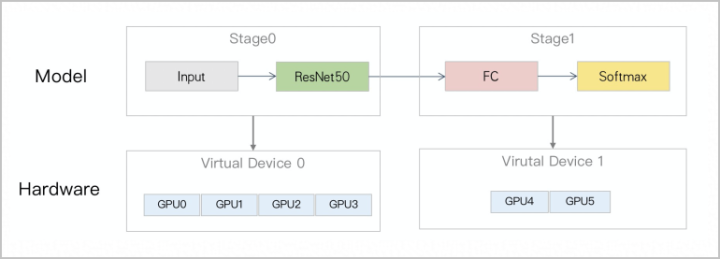
针对ResNet50的大规模分类任务,将模型分为两个Stage。将Stage 0的ResNet50部分通过数据并行策略复制N份至不同的卡中,进行数据并行。将Stage 1的FC和Softmax部分通过算子拆分策略分片至不同卡中,进行模型并行。假设共六张卡(GPU0、GPU1、GPU2、GPU3、GPU4及GPU5),将GPU分为两组,分别进行数据并行和算子拆分,如下图所示。
3、流水并行[3]
上面介绍了模型并行,在执行模型并行的过程中极容易出现GPU等待的问题。比如一部分模型还在做梯度更新,而另一部分的模型这一轮已经更新好了。在Bert类模型经常容易出现这样的状况。
比如把Bert模型进行拆分,不同GPU处理模型的不同模块:
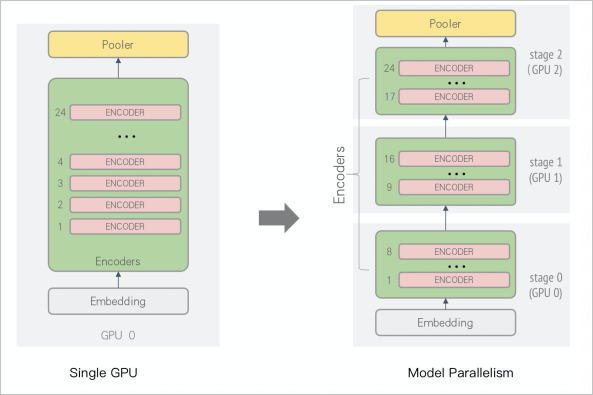
模型并行计算过程中会出现闲时等待问题,如下图所示。
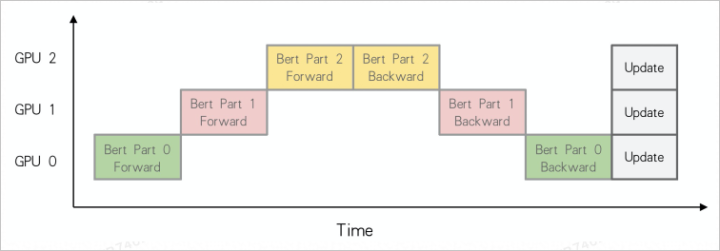
可以看到同一个时间段只有一张卡在做前向或者是后向的训练。流水并行要解决的问题是,当一张卡训练完之后马上通知下一张卡进行训练,让整个计算过程像流水线一样连贯,流水并行在大模型场景会大大提升计算效率,减少GPU的等待时间。

无论是模型并行还是流水并行,这些并行模式通常会混合使用,也就是说混合并行计算。业内有许多开源的框架可以实现上述能力,比如微软开源的DeepSpeed可以提供模型并行和流水并行的能力。DeepSpeed项目地:https://github.com/microsoft/DeepSpeed
通信优化
通信优化有很多方面,比如通信系统优化、通信模式优化和通信内容优化。接下来逐一介绍下这些通信优化领域的基础概念。
1、通信系统优化[5]
通信系统可以分为两个大的类别,一种是Allreduce结构,目前更常用的是Ring-Allreduce。另一种是PS,也就是Parameter Server参数服务器结构。
1.1、PS框架[6]
首先介绍下PS架构,在这种架构下,通常将计算节点分为PS节点和Worker节点两个类型。其中PS节点主要用来存放参数,Worker节点负责计算梯度,Worker计算好的梯度数据传输给PS节点,由PS节点聚合后再反馈给各个Worker进行下一步训练。
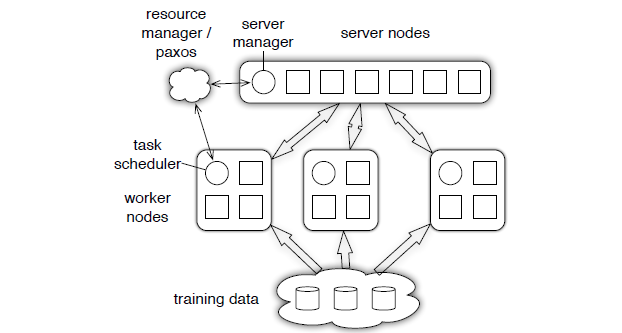
但是随着模型逐渐增大,导致每次PS节点和Worker节点需要传输的数据越来越多,PS的通信结构使得PS节点的带宽成为通信瓶颈,并不一定适合于超大规模的分布式深度学习训练,于是便有了下文提到的,Ring Allreduce通信结构。
1.2 、Ring-Allreduce框架[7]
关于Ring-Allreduce,我之前写过相关文章,这里直接引用,Ring-Allreduce主要解决两方面问题。
问题一,每一轮的训练迭代都需要所有卡都将数据同步完做一次Reduce才算结束。如果卡数比较少的情况下,其实影响不大,但是如果并行的卡很多的时候,就涉及到计算快的卡需要去等待计算慢的卡的情况,造成计算资源的浪费。
问题二,每次迭代所有的计算GPU卡多需要针对全部的模型参数跟Reduce卡进行通信,如果参数的数据量大的时候,那么这种通信开销也是非常庞大,而且这种开销会随着卡数的增加而线性增长。
为了解决这样的问题,就引入了一种通信算法Ring Allreduce,通过将GPU卡的通信模式拼接成一个环形,从而减少随着卡数增加而带来的资源消耗,如下图所示:
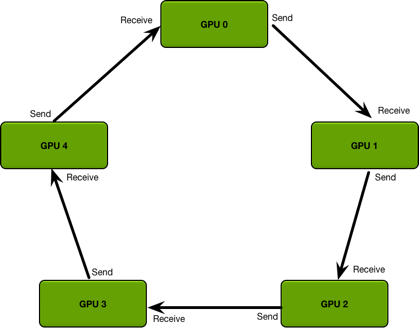
将GPU卡以环形通信之后,每张卡都有一个左手卡和右手卡,那么具体的模型参数是如何传递的呢,可以看下图:

因为每张卡上面的网络结构是固定的,所以里面的参数结构相同。每次通信的过程中,只将参数send到右手边的卡,然后从左手边的卡receive数据。经过不断地迭代,就会实现整个参数的同步,也就是reduce。形成以下这张图的样式:

通过Ring Allreduce的方式,基本上可以实现当GPU并行卡数的增加,实现计算性能的线性增长。
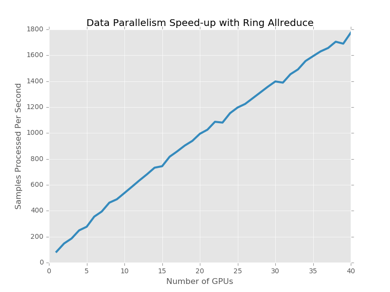
通过上图不难发现,Ring-Allreduce通信框架在数据并行方面有着是否优异的效果。
2、通信模式
除了通信系统架构,通信模式也对性能有较大影响。通信模式通常分为异步通信和同步通信两种。在PS架构中通常会涉及到通信模式的问题。同步通信是比较低效的一种方案,指的是利用PS节点做参数的存储和Reduce,每次PS会等所有的worker都计算完梯度,才做一次梯度的平均,然后分发给各个worker进行更新。这种模式很容易造成堵塞,当PS和worker的通信阻断了,整个训练就无法进行下去,当然如果增加PS节点来缓解阻断问题,又会增加整个系统的负责度。
异步更新会比同步更新机制更完善,指的是PS节点不必每次都等所有worker计算完再做梯度更新,当PS节点收到worker的梯度更新请求后,立刻进行梯度的下发。当然,异步更新也会引出新的问题需要优化,就是每一轮更新的梯度可能是几轮以前计算出来的,另外如果参数读取未加锁,有可能worker会从ps读取到刚更新一般的参数。
3、通信内容优化[8][9]
以上介绍的都是通信的架构和模式,那么通信管道的内容也是有优化空间的。比如稠密通信可以做信道合并,稀疏通信可以数据存储和格式转换的优化。
通常做深度学习训练的时候,使用的数据都是TFrecord类型,protobuf格式的文件,或者是hdf5、pickle,这种文件都是行存,每次读取数据都需要获取全量字段。但是很多场景,可能每次读取只需要一个字段的数据,这样列存的数据IO模式就比较高效,自动驾驶就是这样的场景。举个例子区分行存和列存,
以下是行存数据结构:
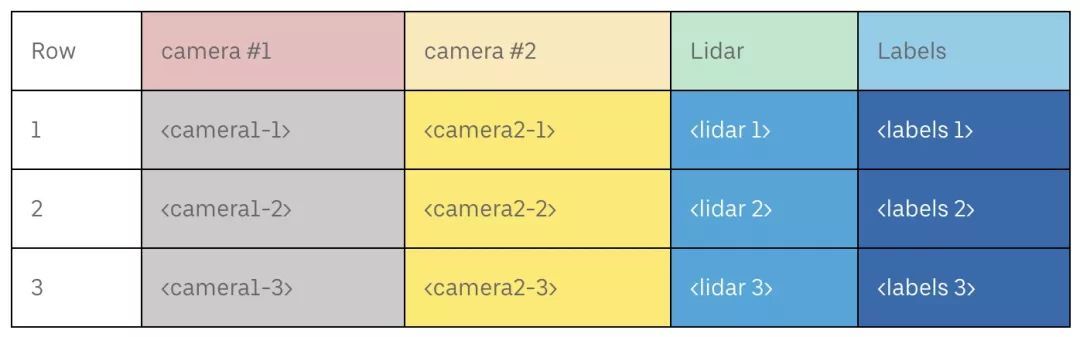
下图是列存的数据结构:
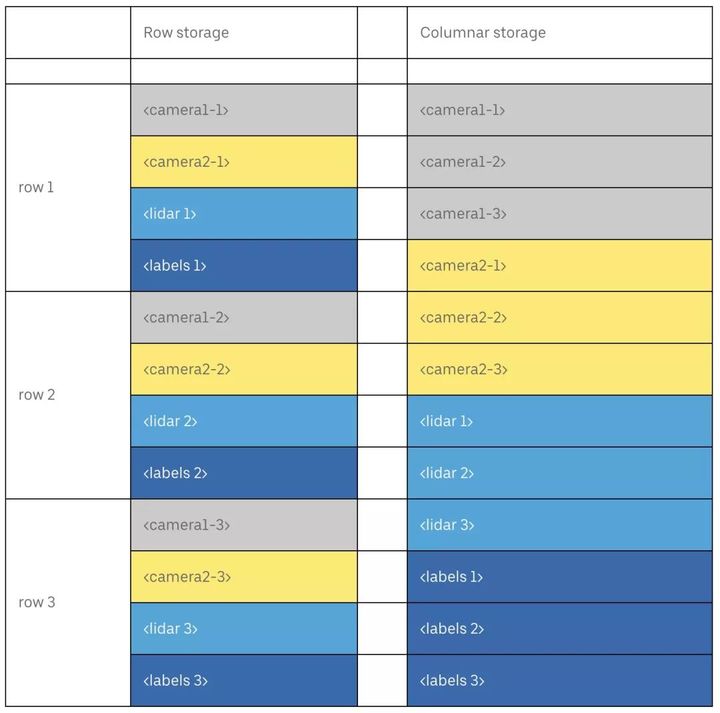
列存允许用户在训练过程中加载列子集,从而节约通信信道的带宽。列存通常会使用Parquet格式,uber开源了一个工作叫做Petastorm ,可以在TensorFlow、Pytorch等框架支持Parquet数据格式。
地址:https://github.com/uber/petastorm
显存优化
首先分析下GPU中占用显存的元素有哪些,神经网络占据显存的部分主要是模型自身的参数以及模型的输出[10]。从模型角度分析,只有有参数的层才会占用显存,比如卷积、全连接、Embedding,那些没有参数的层其实不占用显存,比如激活、池化、dropout。从模型输出角度分析,基本上batch-size越大,显存占用越大。总结下,降低显存的占用的方案是降低batch-size,或者减少全连接层这种参数较多的神经网络结构。
另外在系统工程层面也有显存优化的方案,可以分为分时复用和合并共享两种模式。
1、分时复用[11]
从工程层面,如果能让GPU的显存一直100%的被占用,其实是最大限度地利用了GPU的显存资源。分时复用的原理是将GPU的显存实现某种层面的资源隔离,利用Schedule的能力,将任务合理的分配到不同时间段内。
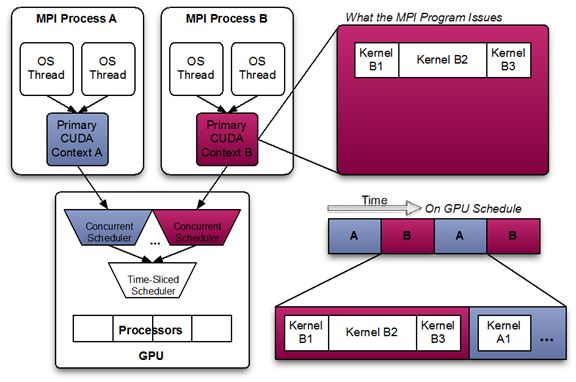
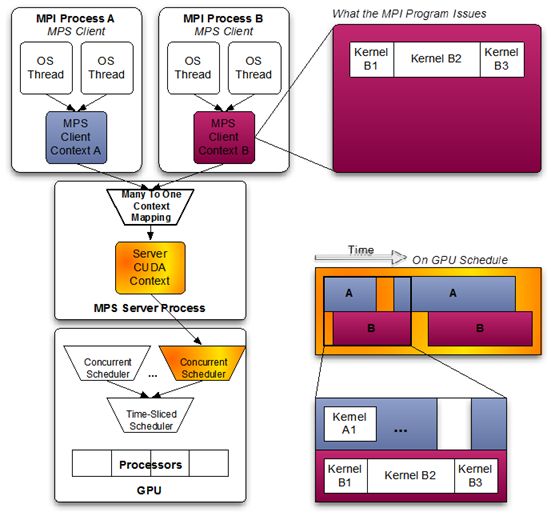
2、合并共享[11]
合并共享是指多个任务合并成一个上下文,因此可以共享GPU资源,同时发送kernel到GPU上,也共同使用显存。NV提供了这样的一套能力,叫做MPS(CUDA_Multi_Process_Service),感兴趣通信可以看下文章的引用信息和NV的官方文档:Multi-Process Service
整体上MPS的内存合并共享机制架构图如下:
编译优化
框架的编译优化是比较底层的一种优化手段,传统的编译器优化依赖于工程师手动的去优化算子,那么计算框架的编译优化希望通过一种偏自动化的方式去实现算子在各种硬件设备层面的编译优化。为什么要做框架的编译优化[12],核心问题是人的精力是有限的,不可能基于无数可被优化的算子做人肉的优化。
编译器将深度学习框架描述的模型在各种硬件平台上生成有效的代码实现,其完成的模型定义到特定代码实现的转换将针对模型规范和硬件体系结构高度优化。目前主流的编译器对于环境的支持情况如下:
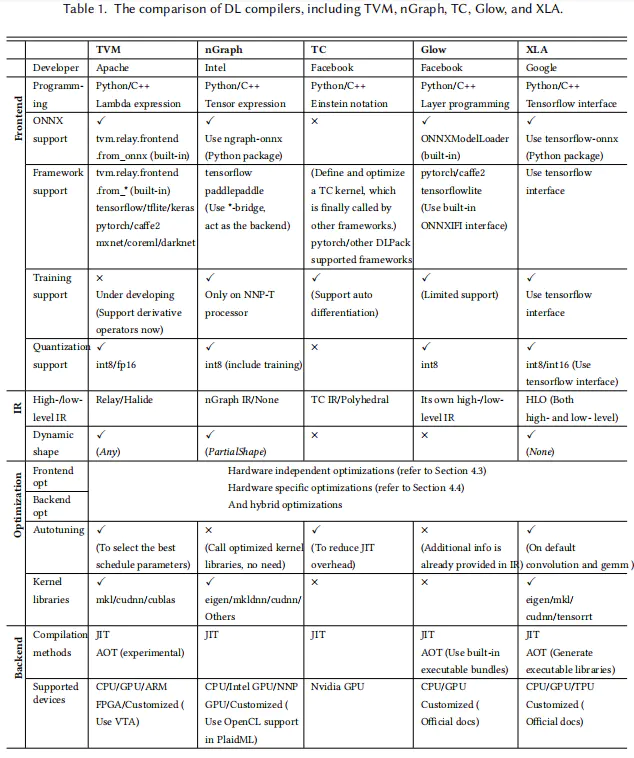
在论文”The Deep Learning Compiler: A Comprehensive Survey“中,还给出了深度学习编译器的整体架构,如下图所示:
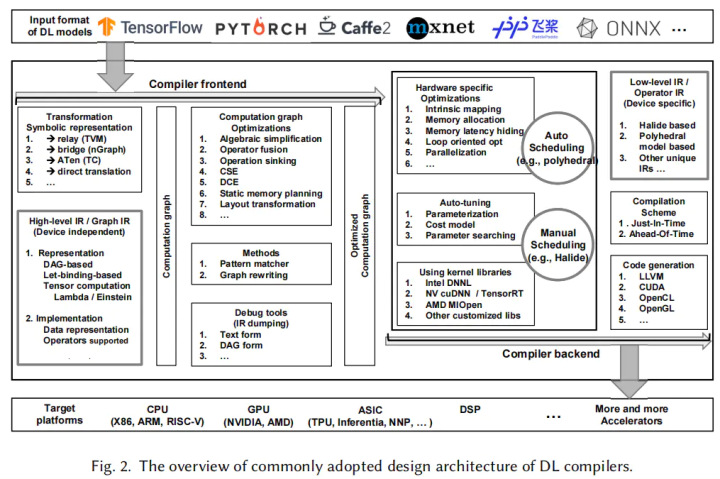
在编译器中可以分为三个主要部分[14],前端计算图和后端以及IR(Intermediate Representation)。通常IR是程序的抽象,用于程序优化。具体地说,DL模型在DL编译器中被转换成多级IR,其中高层IR驻留在前端,而底层IR驻留在后端。编译器前端基于高层IR,负责与硬件无关的转换和优化。基于底层IR,编译器后端负责特定于硬件的优化、代码生成和编译。
整个优化分为前端图级别的优化以及后端优化,接下来分别介绍下这两个优化方向。
1、前端图优化
前端图优化总体上是通过输入的神经网络图结构,找到其中可以优化的模块并重新构造图。图优化可以分为节点优化、块优化、数据优化。
其中节点优化是消除不必要的节点,比如A是零元张量,B是常数张量,A+B的计算就可以替换成B,这样就减少了图的复杂度。块优化可以实现一些运算符层面的简化,比如A*B+A*C是三次计算,(B+C)*A就变成了两次计算,这样就通过一些算子的融合机制实现了计算的精简。数据全局优化,是通过全图链路精简计算复杂度,比如一个数值A已经计算过,那么接下来就不用重复计算,直接使用。
2、后端优化
后端优化包含指定硬件优化、自动调优技术以及内核库优化。指定硬件优化指的是将底层IR转化为LLVM IR,利用LLVM基础结构生存适配CPU或者GPU的代码,提高逻辑执行效率,这个过程叫做Codegen。
自动调优技术指的是合理设定每个计算单元在硬件层面的参数,因为每个计算都需要设定共享内存、寄存器大小等参数。利用自动调优技术,建立Cost model,可以自动判定参数,提升计算效率。
优化内核库技术指的是把数据自动转换成适配英特尔的DNNL(以前是MKL-DNN)、NVIDIA的cuDNN和AMD的MLOpen的数据结构和格式,使得代码可以直接使用到这些底层的优化内核库。
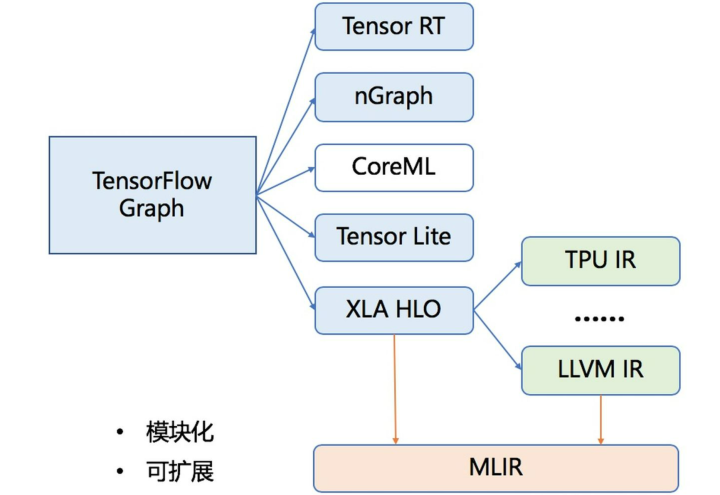
3、MLIR[15]
最后介绍下什么是MLIR,前面说了IR是计算逻辑在编译层面的一种抽象表示。深度学习在编译过程中,需要将high-level的IR转换成low-level的IR去适配不同硬件环境。如下图:

这种做法就造成了系统的复杂性,MLIR希望提供一种框架标准,使得不同IR可以模块化,并且统一标准去适配各种硬件条件,从而减少系统复杂性。
总结
本文是我个人在学习深度学习优化技术过程中的一个总结,覆盖了分布式策略、显存、通信、编译各个维度的优化基础概念,这些概念的学习来自于下方引用部分的小伙伴的分享,感谢大家。有不准确的地方望大家指正,我会修改。整个深度学习优化内容负责,种类繁多,后续需要不断学习和进步。
引用:
[1]分布式计算策略:PAI视频内容
[2]算子拆分:大规模分类的分布式训练(算子拆分) - 机器学习PAI - 阿里云
[3]流水并行:BertLarge分布式训练(流水并行) - 机器学习PAI - 阿里云
[4]DeepSpeed:https://github.com/microsoft/DeepSpeed
[5]PS&RingAllReduce[深度学习] 分布式模式介绍(一)_小墨鱼的专栏-CSDN博客
[6]PS:https://zhuanlan.zhihu.com/p/50116885
[7]Ring-Allreduce:ring allreduce和tree allreduce的具体区别是什么? - 知乎
[8]通信内容:分布式深度学习训练中的通信优化有哪些主流的研究方向? - 知乎
[9]Parquet:https://zhuanlan.zhihu.com/p/45364584
[10]显存优化:科普帖:深度学习中GPU和显存分析 - 知乎
[11]分时复用、共享复用:It - 收藏夹 - 知乎
[12]编译器的必要性:深度学习编译技术的现状和未来 - 知乎
[13]编译器概述:https://zhuanlan.zhihu.com/p/139552817
[14]The Deep Learning Compiler: A Comprehensive Survey翻译:翻译《The Deep Learning Compiler: A Comprehensive Survey》综述翻译 - 简书
[15]MLIR说明:https://zhuanlan.zhihu.com/p/101879367















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









