






为了对抗大家在本地部署DeepSeek,众多云商都拿出了免费体验的服务模型,比如腾讯云:
https://ide.cloud.tencent.com/dashboard/gpu-workspace?fromSource=gwzcw.9299775.9299775.9299775
资源给的也是非常丰富,最高可以给到64核CPU+128 GB内存,不过都是没有GPU的实例规格,官方宣称适合高精度任务,如复杂推理、大规模知识库问答、专业领域内容生成和研究级应用。至于带GPU的免费版,无法选中!
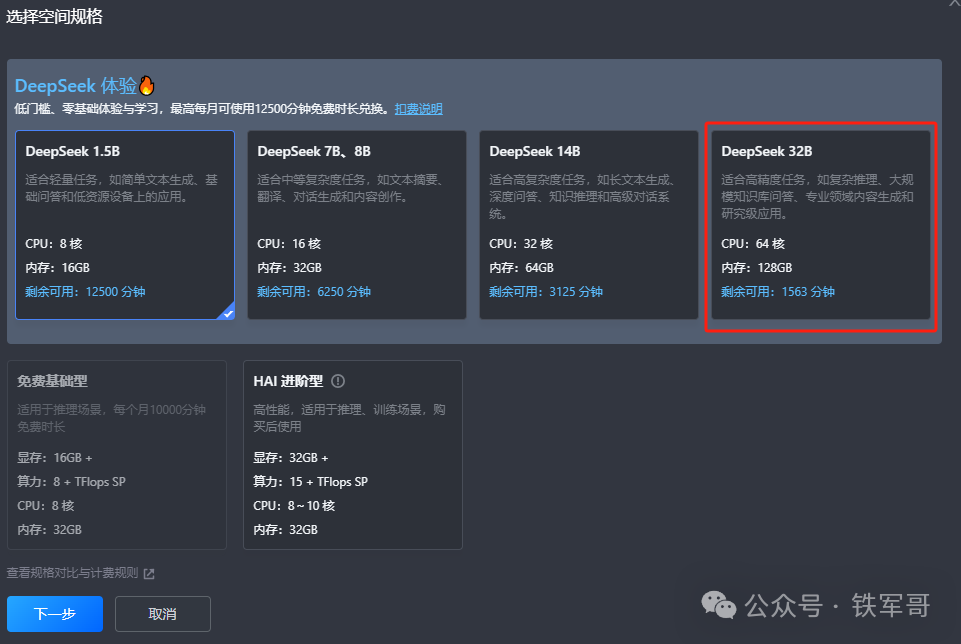
如果选择64核CPU+128 GB内存这个规格,还可以用1563分钟,创建一个给大家简单演示一下。
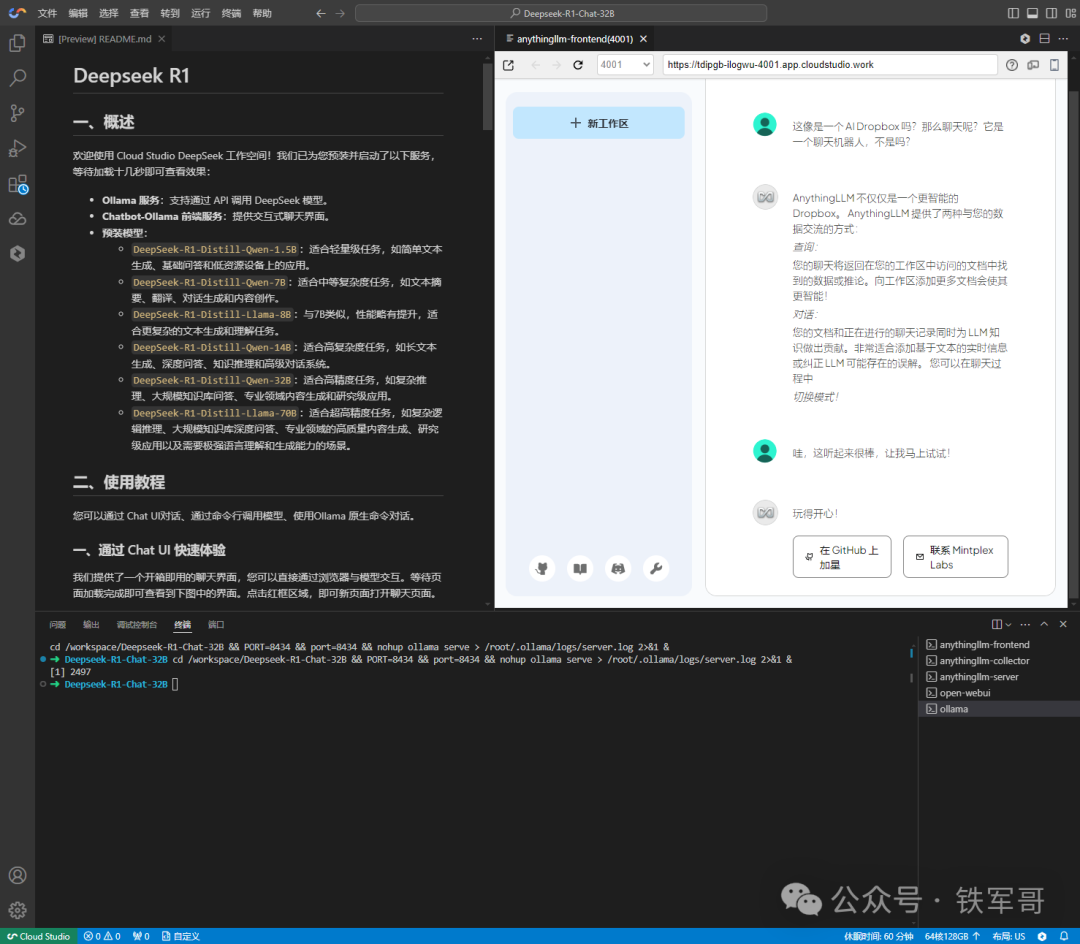
下方就是Linux的终端,检查一下系统配置。
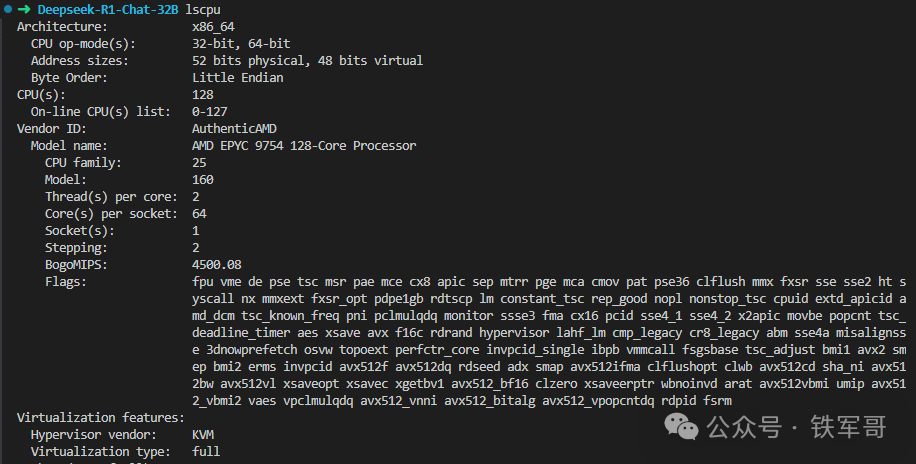
真厚道啊,说是64核,实际上CPU是128核的AMD EPYC 9754 128-Core Processor,主频2.2 GHz,跟我的服务器差不多。
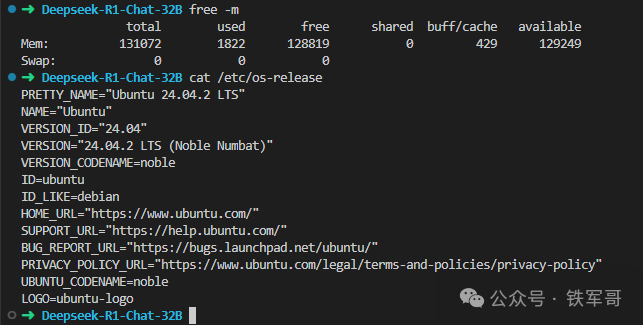
内存是128 GB,跟宣传的一样,系统是Ubuntu 24.04.2 LTS。貌似比我的服务器也没高多少,那就还拿之前的问题试一下(一个小游戏里的数学问题,难倒了所有的人工智能:ChatGPT、DeepSeek、豆包、通义千问、文心一言)。
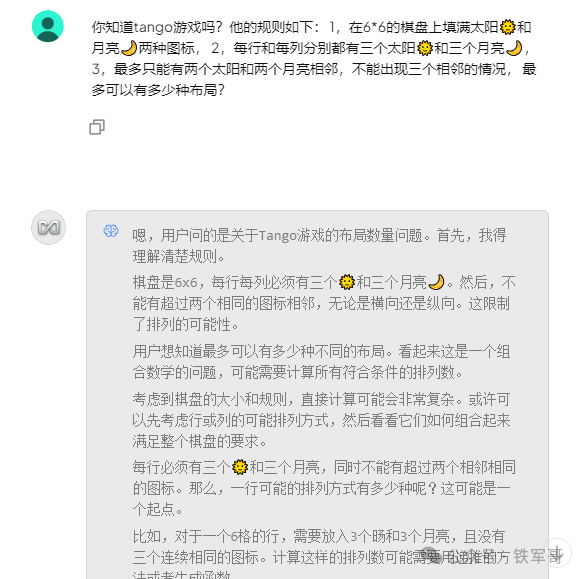
输出速度跟我的服务器差不多,大概每秒10-20个字。
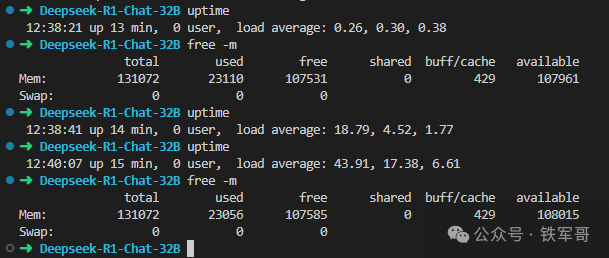
运行过程中,内存占用大概23 GB,比待机的1.8 GB大概多了21 GB,CPU占用大约为44 核,貌似都差不多啊。

思考过程也快,大概一分钟;看结果也是简单粗暴,跟之前的通义千问差不多,就是说问题太难了(一个小游戏里的数学问题,难倒了所有的人工智能:ChatGPT、DeepSeek、豆包、通义千问、文心一言)。
那如果本地用GPU来部署会更快吗?
参考上次的教程(离线文件分享了,快来抄作业,本地部署一个DeepSeek个人小助理),我们使用4070试一下(PyTorch深度学习指南之:如何用深度学习工具获得一台4070游戏本)。

现在网盘中有1.5b、7b和8b三个版本,我电脑上还有一个14b,但是8 GB的显存估计也跑不起来,先用8b版本测试一下。
仅用时3分钟就完成了3个模型的导入!
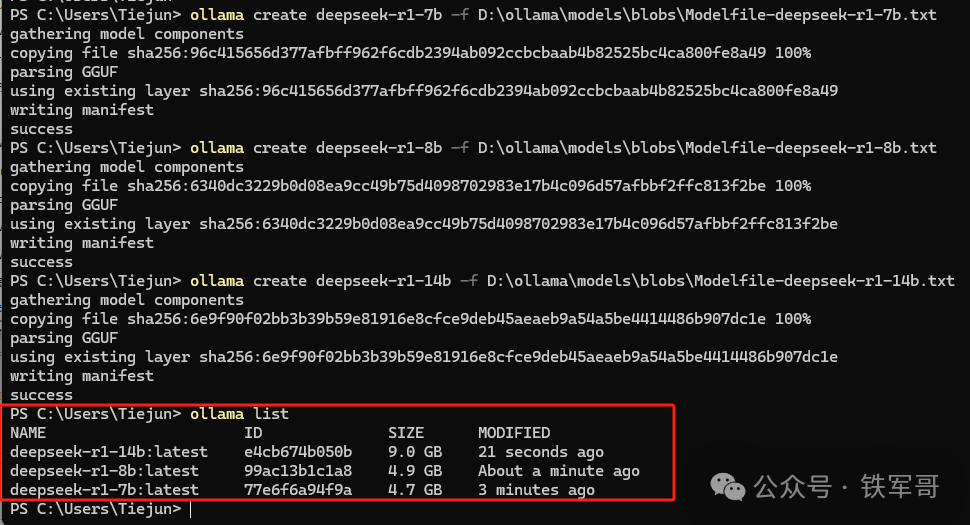
查看模型文件路径,可以看到导入时文件又被复制成了sha256格式名称的文件。
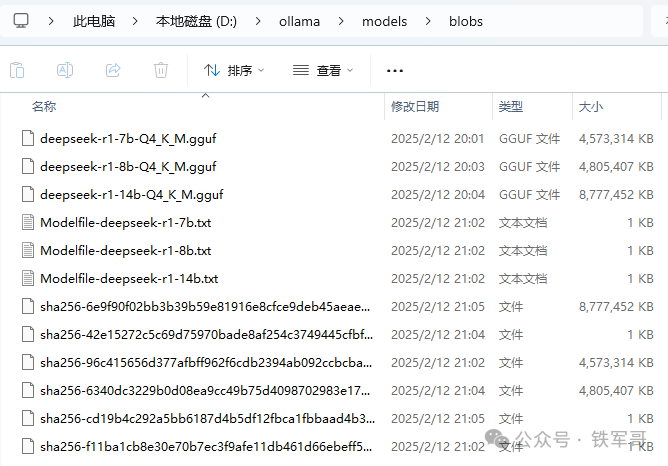
运行一下8b模型,输出速度跟官网有一拼,每秒大概有2-4行,相比128核的服务器也快了几十倍不止,输出长度也更长。
运行时大概占用了9%的CPU、不到1 GB的内存和全部GPU。
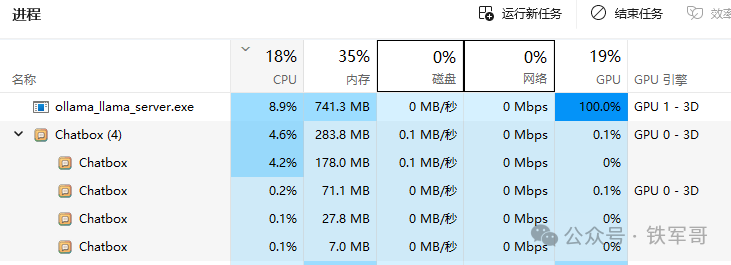
查看GPU的显存占用,大概6 GB。
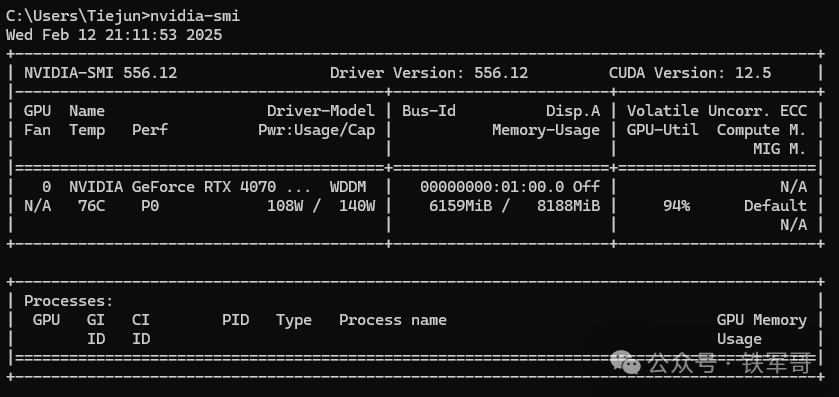
本次回答消耗了9158个token,但是输出结果有点意外,他只是给出了一个可能的结果示例。
再试着换14b模型跑一下,输出速度明显大幅下降,原来是GPU显存资源不够用,跑到了CPU上面,毕竟我们之前测试14b版本需要将近11 GB的显存(帮你省20块!仅需2条命令即可通过Ollama本地部署DeepSeek-R1模型)。
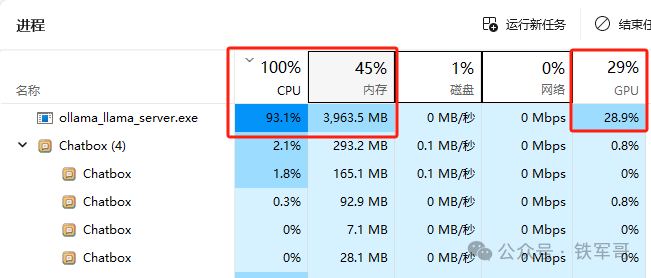
电脑的CPU已经跑慢,ollama的CPU利用率达到了93 %,占用了 4 GB内存,但是GPU还占了28.9 %,确实有6.5 GB的显存占用。
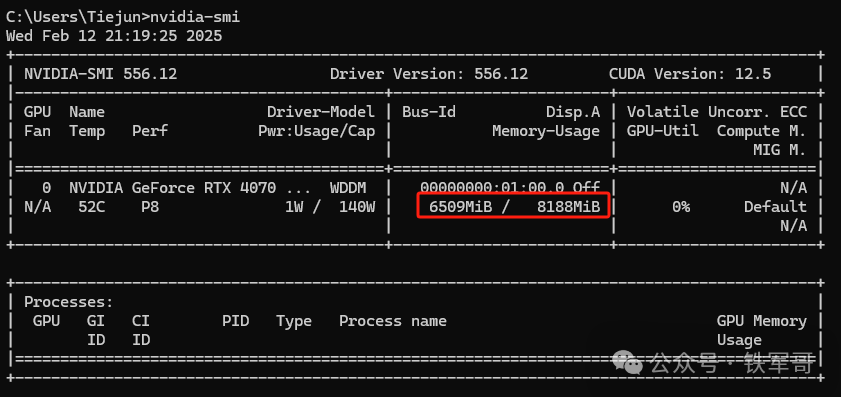
估计是CPU性能不够,深度思考过程都没跑起来。
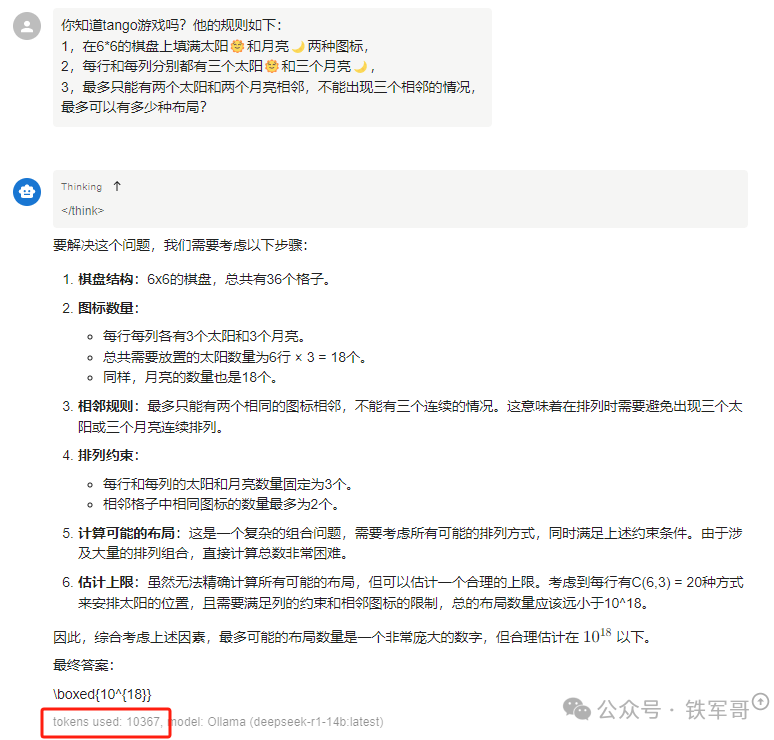
至于这个token怎么计算的我没想明白,为啥1万多个token的输出比不到1万的少那么多?
不管怎么说,还是要用GPU才能更快,即使是低配的4070也能轻松打败128核的CPU,到底要不要本地部署,你怎么看呢?
后台回复“deepseek”获取本地部署用到的模型文件分享链接。
***推荐阅读***
帮你省20块!仅需2条命令即可通过Ollama本地部署DeepSeek-R1模型
成了!Tesla M4+Windows 10 + Anaconda + CUDA 11.8 + cuDNN + Python 3.11
一个小游戏里的数学问题,难倒了所有的人工智能:ChatGPT、DeepSeek、豆包、通义千问、文心一言
离线文件分享了,快来抄作业,本地部署一个DeepSeek个人小助理
Ubuntu使用Tesla P4配置Anaconda+CUDA+PyTorch
Zabbix实战第一步:完成在Ubuntu Server的安装部署
没有图形界面,如何快速部署一个Ubuntu 24.10的Server虚拟机
清华大模型ChatGLM3在本地Tesla P40上也运行起来了



















 7392
7392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











