







第五章,K近邻算法
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法。
两个样本的距离可以通过如下公式计算,又叫欧式距离。
比如说,a(a1,a2,a3),b(b1,b2,b3),那么它们之间的欧氏距离就用下图方法计算:
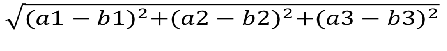
######K近邻算法API:sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)
####n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
####algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
k值取很小:容易受异常点影响
k值取很大:容易受K值数量(类别)波动

作业如下:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd
def knncls():
"""
作业:K-近邻预测鸢尾花类别
:return:None
"""
# 读取数据
li = load_iris()
#print(li.head(10))
x_train, x_test, y_train, y_test = train_test_split(li.data, li.target, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进行算法流程 # 超参数
knn = KNeighborsClassifier()
# fit, predict,score
knn.fit(x_train, y_train)
# 得出预测结果
y_predict = knn.predict(x_test)
print("预测的目标类别为:", y_predict)
# 得出准确率
print("预测的准确率:", knn.score(x_test, y_test))
return None
if __name__ == "__main__":
knncls()
测试:
预测的目标类别为: [2 0 2 0 1 0 0 1 2 2 0 0 1 2 0 0 1 2 0 2 1 2 0 2 0 2 2 0 1 2 0 1 1 2 1 2 1
0]
预测的准确率: 0.9210526315789473
进程已结束,退出代码0
每次运行之后的预测正确率好像不一样,原来是没有固定随机数种子,如果希望每次结果一样可以加上一段代码,放在主代码前面就行。具体看链接:
https://blog.csdn.net/qq_40177564/article/details/102809421















 1665
1665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









