







常规的全连接神经网络中,每个神经元连接上一层所有神经元的输出,卷积神经网络只连接上一层神经元的一部分输出
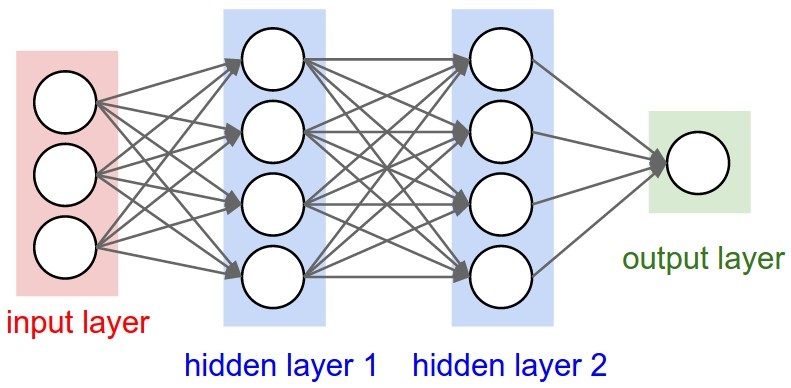
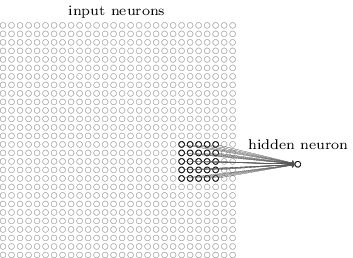
一个完整的卷积结构如下图所示
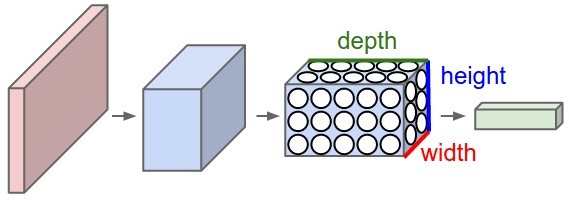
卷积网络两大特性:
-
局部连接(local connectivity)
举例说明,一幅227x227x3的输入图像,卷积层的每个神经元不是与整幅图像连接而只是与其中的11x11大小的区域连接,这个区域称作local receptive field;值得注意的是一般只在width,height两个方向上进行局部连接,而在depth则是全连接(lenet-5不是这样做的)。
比如:输入32x32x3大小的图像,receptive field为5x5,那么总共有5x5x3=75个连接
卷积层的输出(feature map)大小由三个参数决定,depth, stride, zero-padding
depth:也就是 卷积层的神经元个数,同时也是卷积核的个数,决定了卷积层输出有多少个feature map
stride::控制每个receptive field 在width,heigh上的重叠程度,如果stride 为1,那么相邻receptive field之间的只有一行或一列不同,stride越大相邻receptive field之间的重叠区域越小
zero-padding:一方面可以控制feature map 大小,另一方面可以确保图像边缘的特征在后边卷积的时候仍然处在receptive field的中间位置
一般用F表示receptive field大小,P表示zero-pading大小,S表示stride大小,K表示depth。如果输入图像为W,则卷积层输出feature map大小为(W-F+2*P)/S + 1,总共有K个这样大小的feature map组合组合成一个三维矩阵,每一个feature map占据矩阵中的一个通道
例子:输入图像:227x227x3,receptive field: 11x11, strdie: 4, zero-padding:0, depth: 96
输出一个feature map大小w, h:(227-11+2*0)/4 +1 = 55, 所有输出为:55x55x96大小的矩阵 -
参数共享(parameter sharing)
参数共享可以大幅度减小模型中的参数,另外更重要的是图像中不同的区域存在相同类型的特征,使用相同的参数可以提取到这些特征。仍然以前一个例子说明:
no paramerter sharing: 55x55x(11x11x3+1)x96 = 105705600
parameter sharing: (11x11x3+1)x96 = 34848
输出feature map中的点称为unit,同一个feature map 中所有的unit共享同一组参数(称为一个卷积核,大小为11x11x3),不同的feature map中的unit使用不同的参数,共有96组不同的参数。
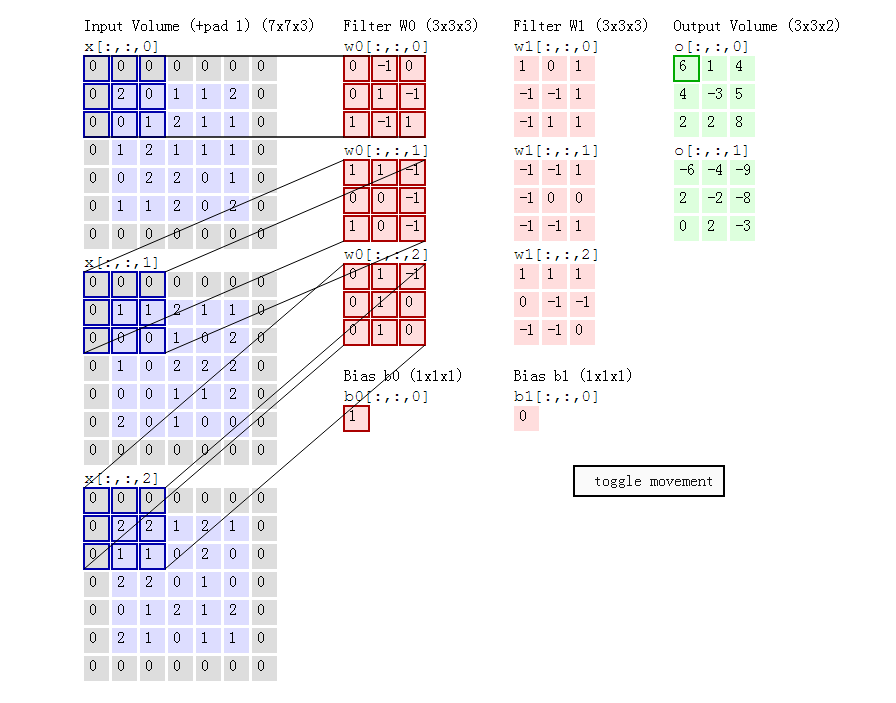
下图是一个卷积的例子,输入是7x7x3的图像,有两组卷积核filter0和filter1,大小都是3x3x3, stride 2, zero-padding 1,输出feature maps :3x3x2
卷积的实现:
卷积的原理是卷积核与图像中对应的block做点积,实现的时候一般转化为矩阵乘积:
还以227x227x3的图像为例,一个receptive field对应的一个卷积block 为 11x11x3,把每个block拉伸为一个列向量,形成一个363x3025大小的图像矩阵X, 同时把每个卷积核拉伸称为一个363x1的行向量,所有卷积核组成一个96x363大小的参数矩阵W,卷积操作转化为W*X
这样做缺点在于需要更多的内存,有点是矩阵相乘可以借助现有的一些矩阵运算库加快运算速度。
增加动图,以主理解
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









