







 本文详述了ASRT语音识别系统在Windows上的部署和模型训练过程,包括CUDA和cuDNN的安装,Anaconda环境配置,数据集下载与解压,配置文件修改,模型训练参数调整以及模型训练与评估。
本文详述了ASRT语音识别系统在Windows上的部署和模型训练过程,包括CUDA和cuDNN的安装,Anaconda环境配置,数据集下载与解压,配置文件修改,模型训练参数调整以及模型训练与评估。
ASRT语音识别系统的部署以及模型训练(模型训练篇)
前言
ASRT是一个中文语音识别系统,由AI柠檬博主开源在GitHub上。
GitHub地址:ASRT_SpeechRecognition
国内Gitee镜像地址:ASRT_SpeechRecognition
文档地址:ASRT语音识别工具文档
本文主要是记录一下我在参考文章:教你如何使用ASRT训练中文语音识别模型 并完成部署和训练过程中的操作步骤。文章作者比较惜字如金,文中很多细节之处没有细讲,我在windows上进行部署的时候踩了比较多的坑,特此记录下。
本文适用对象:想要训练自己的语音识别模型(如:训练出可识别某些方言的模型)以搭建一个能够进行满足自定义需求的语音识别服务端。
先决条件
众所周知,跑神经网络,要用到英伟达的显卡。
本人硬件参数: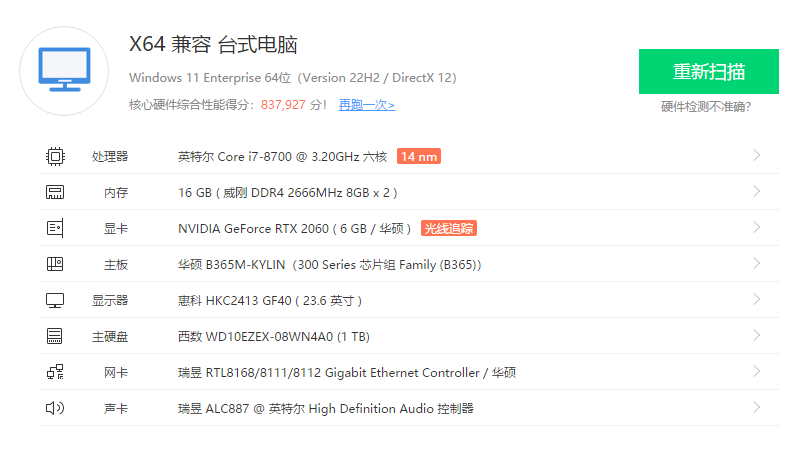
以下是官方配置建议,我的显卡肯定不达标,但我想着最多训练久一点[捂脸]。

下载源代码
按照如图所示步骤即可直接下载最新源代码压缩包。
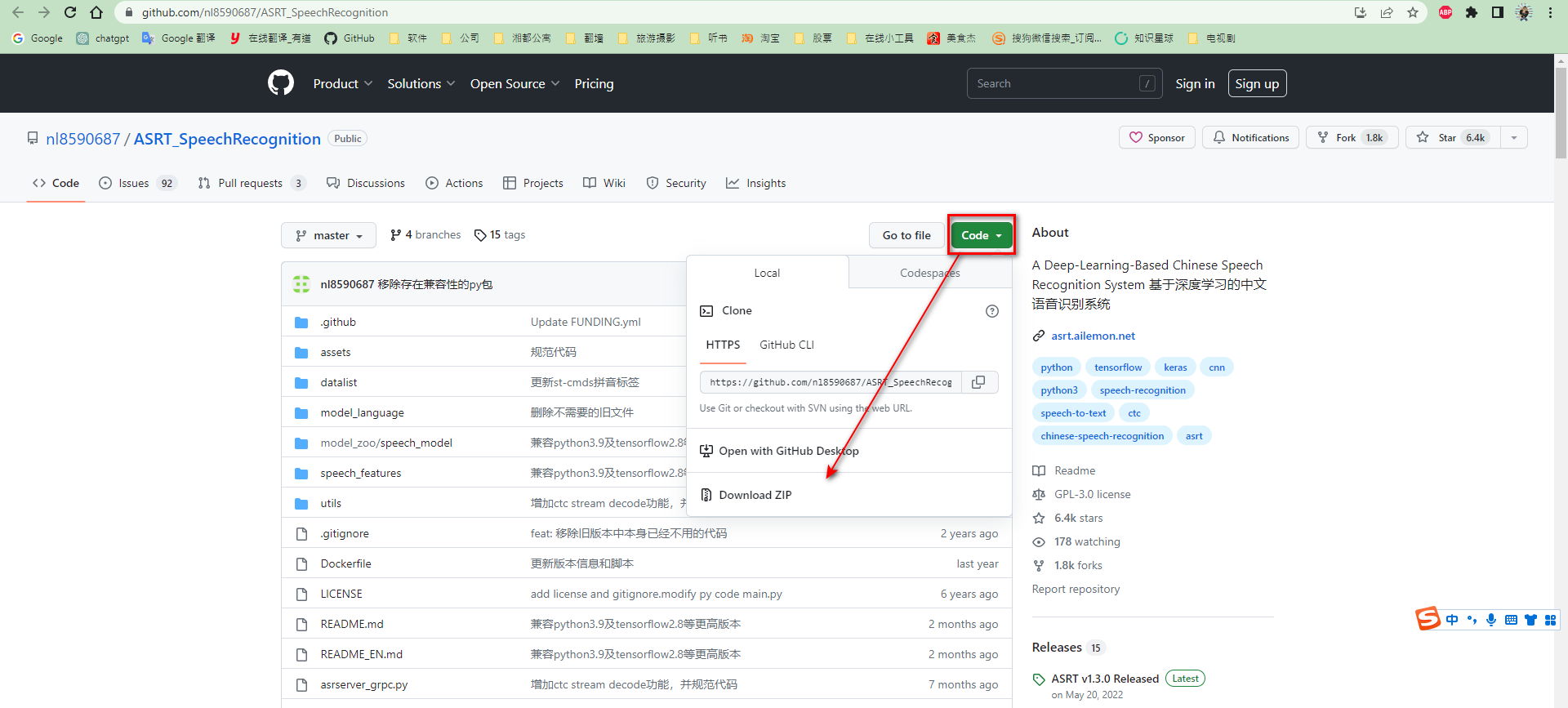
下载完成后,需要进行解压。之后,如果GitHub仓库上如果代码有更新,重复上述步骤即可。
我的解压路径:
cd C:\Users\Administrator\Documents\ftp\qianyuhui\src\ASRT_SpeechRecognition
操作系统安装CUDA、cuDNN
训练模型请安装好Nvidia GPU驱动和CUDA、cuDNN。
安装步骤
安装过程略过。参考文章:Windows 安装 CUDA/cuDNN
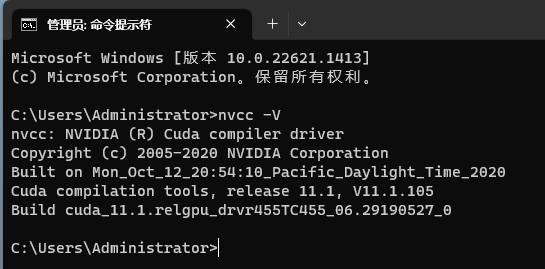
查看CUDA版本
nvcc -V
查看cuDNN版本
进入 cuda 的安装路径, C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include,找到 cudnn_version.h 选中,以记事本方式打开。
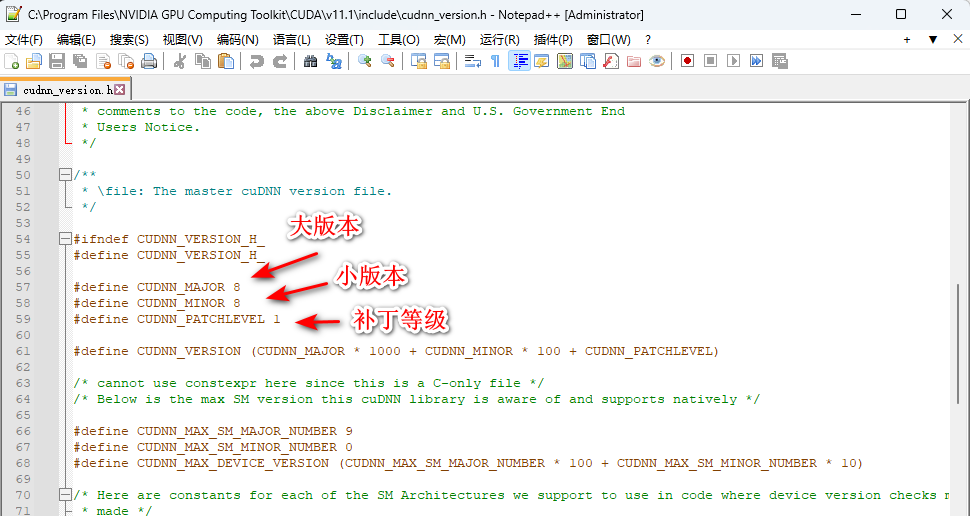
这里,我的是8.8.1
安装Anaconda
安装步骤
安装步骤略过,参考文章:anaconda的安装和使用
查看conda版本信息
Anaconda PowerShell控制台中输入以下命令:
conda info
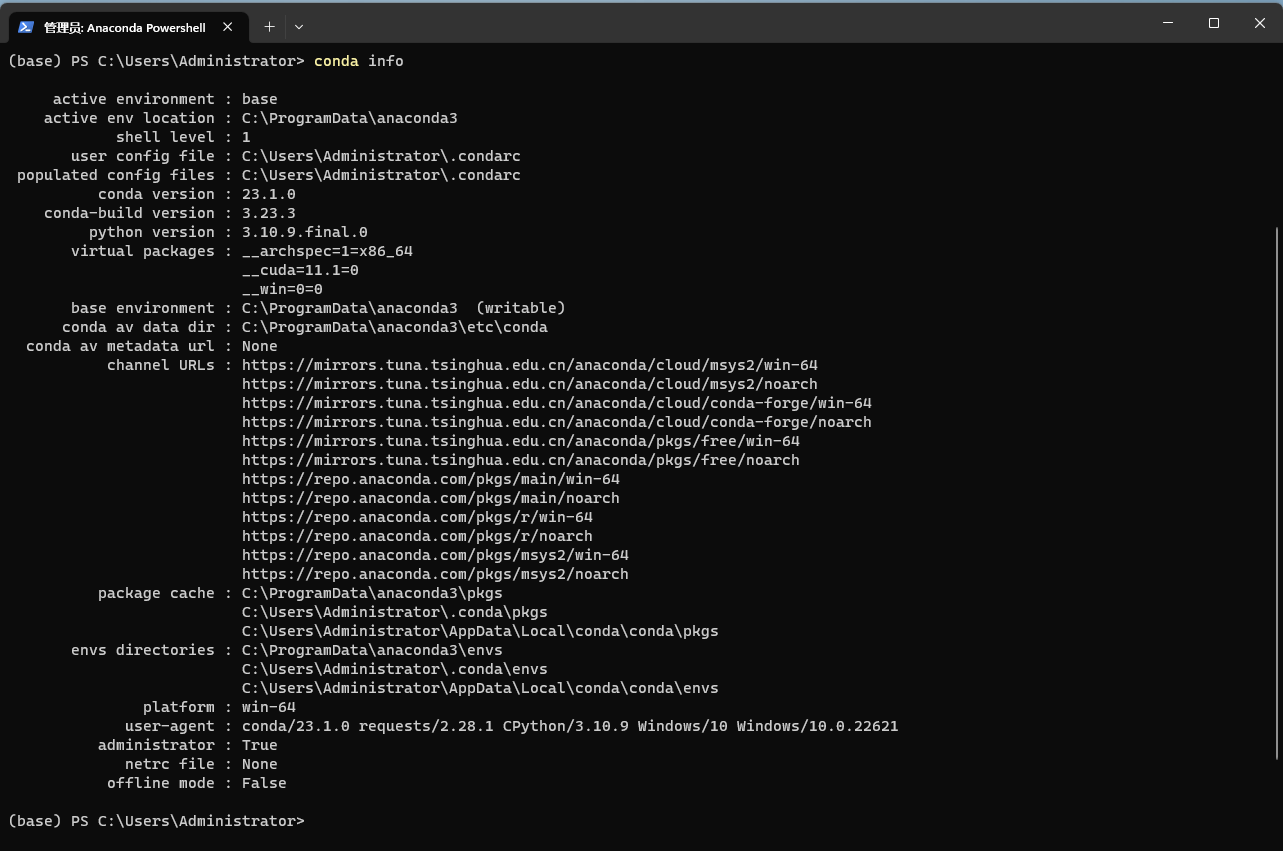
我的conda版本是23.1.0
conda创建python虚拟环境
首先请确保Anaconda 创建python3.10的虚拟环境。
操作步骤
我给asrt单独创建了一个名为:asrt_env的虚拟环境:
Anaconda PowerShell控制台中输入以下命令:
conda create -n asrt_env python=3.10
查看虚拟环境基本信息
Anaconda PowerShell</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











