






 超级会员免费看
超级会员免费看

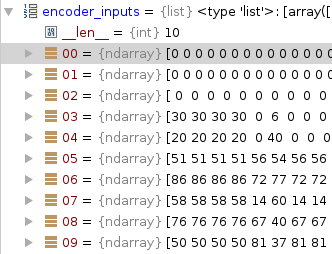
50是“但”
76是“等了”
58是 “五年”
之所以有多个50 50 50 50是因为batchsize比数据量大
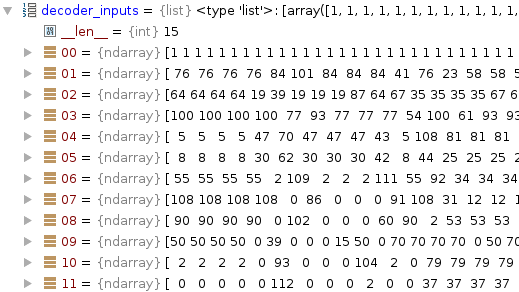
1是开始
2是句子结束
可见 竖列 前四个也是一样的
76是 “but”
64是 “waited”
100是 “5”
5是 “years”

可见00-09的前4竖列是1,对应decoder_inputs的长度

 该博客探讨了在使用seq2seq模型进行翻译任务训练时,输入数据的构成。重点提到了batchsize大于数据量导致的重复现象,以及如何表示开始、结束标志和具体单词,例如'but'、'waited'、'5 years'。
该博客探讨了在使用seq2seq模型进行翻译任务训练时,输入数据的构成。重点提到了batchsize大于数据量导致的重复现象,以及如何表示开始、结束标志和具体单词,例如'but'、'waited'、'5 years'。
50是“但”
76是“等了”
58是 “五年”
之所以有多个50 50 50 50是因为batchsize比数据量大
1是开始
2是句子结束
可见 竖列 前四个也是一样的
76是 “but”
64是 “waited”
100是 “5”
5是 “years”
可见00-09的前4竖列是1,对应decoder_inputs的长度
 1635
1442
1635
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























