







2021李宏毅机器学习笔记--19 unsupervised learning--Deep Auto-encoder
摘要
文本介绍了自编码器的基本思想,自编码器就是将数据进行自我压缩和解码的过程。并且介绍了与PCA(主成分分析)的联系,对数据做PCA以后可以得到数据的主成分信息,这部分信息可以很好的还原原数据,对应到自编码器其实就是编码和解码的过程。自编码器可以被应用于文字检索,每一篇文章都表示成向量空间中的一个向量,把要查询的词汇也变成一个点,然后计算点之间的余弦相似度可以检索文章。自编码器也可以用于相似图像检索,先用自编码器对图像进行降维和特征提取,然后再计算所要查询的图像的像素与图库中的像素的相似度进行检索。当有大量没有标注的数据时,可以用自编码器做预训练来找到比较好的参数初始化值。CNN用于图像处理的思想就是交替使用卷积层和池化层,让图像越来越小,类似于编码,那么解码的过程就是去卷积层和去池化层。
一、Auto-encoder简介
Auto-encoder本质上就是一个自我压缩和解压的过程,我们想要获取压缩后的code,它代表了对原始数据的某种紧凑精简的有效表达,即降维结果,这个过程中我们需要:
1、Encoder(编码器),它可以把原先的图像压缩成更低维度的向量
2、Decoder(解码器),它可以把压缩后的向量还原成图像
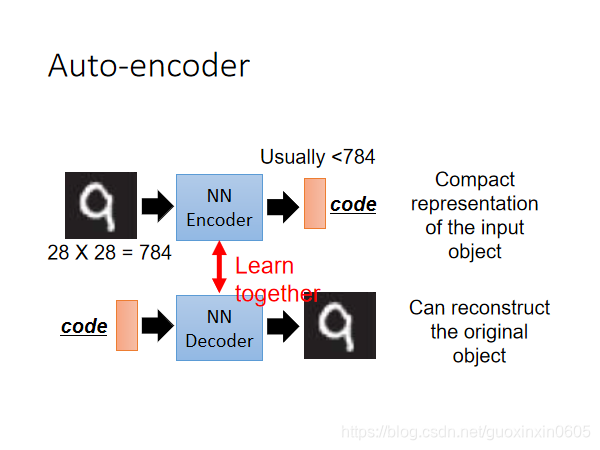
注意到,Encoder和Decoder都是Unsupervised Learning,由于code是未知的,对Encoder来说,我们手中的数据只能提供图像作为NN的input,却不能提供code作为output;对Decoder来说,我们只能提供图像作为NN的output,却不能提供code作为input。
因此Encoder和Decoder单独拿出一个都无法进行训练,我们需要把它们连接起来,这样整个神经网络的输入和输出都是我们已有的图像数据,就可以同时对Encoder和Decoder进行训练,而降维后的编码结果就可以从最中间的那层hidden layer中获取
二、与PCA的联系
主成分分析算法(PCA)是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的信息量最大(方差最大),以此使用较少的数据维度,同时保留住较多的原数据点的特性。
实际上PCA用到的思想与之非常类似,PCA的过程本质上就是按组件拆分,再按组件重构的过程。
在PCA中,我们先把均一化后的x根据组件W分解到更低维度的c ,然后再将组件权重乘上组件的反置 W T W^T WT得到重组后的 x ^ \widehat x x
,同样我们期望重构后的 x ^ \widehat x x
与原始的x越接近越好。

如果把这个过程看作是神经网络,那么原始的x就是input layer,重构 x ^ \widehat x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









