







 本文详细介绍了MindSpore中自定义数据集的使用,包括Mappable和Iterable两种方式,以及性能优化和常见问题。建议优先使用Mappable方式,支持多进程/多线程模式,并给出了内存上涨和卡死问题的解决方案。
本文详细介绍了MindSpore中自定义数据集的使用,包括Mappable和Iterable两种方式,以及性能优化和常见问题。建议优先使用Mappable方式,支持多进程/多线程模式,并给出了内存上涨和卡死问题的解决方案。
一、数据集介绍
用户数据集/开源数据集是多种多样的,对于种类繁多的数据集如何更好的支持,在提供高性能加载的同时需要有充足的灵活性。因此,MindSpore提供了灵活的数据集加载方法,主要分为三类:常用数据集、标准数据格式数据集、自定义数据集。
1. 常用数据集,可以直接使用MindSpore内置的API接口进行加载,其主要是基于C++实现,性能高。
MindSpore提供了CelebADataset、Cifar10Dataset、CocoDataset、ImageFolderDataset、MnistDataset、VOCDataset等常用数据集加载接口,在保证性能的同时,能够让用户开箱即用。常用数据集接口链接如下:
2. 标准数据格式数据集,需要预先将数据集转换成标准数据格式然后再读取,基于C++实现,性能高。
MindSpore提供了MindSpore数据格式,即MindRecord,用户可以使用 FileWriter 接口很方便的将现有数据集转换成 Mindrecord格式数据集,然后通过 MindDataset 接口进行加载并做数据处理后用于训练。同时,也提供诸如 TFRecord、CSV 格式数据集的一键加载接口。标准数据格式数据集接口链接如下:
3. 自定义数据集,方便集成用户现有数据集读取代码,基于Python实现,性能中。
如果以上两种方式满足不了用户对于数据集的加载,那可以通过Python编写自定义数据集读取类,再使用 GeneratorDataset 接口进行数据集加载。该方式优点是可以快速集成用户现有数据集读取代码,但由于数据集读取代码是Python Runtime,需要额外关注数据加载性能。自定义数据集接口链接如下:
下文主要对自定义数据集实现及用法做重点说明。
二、自定义数据集介绍
自定义数据集提供非常灵活的数据集加载方式,用户通过该方式,定义自定义加载类,然后将该类传递给 GeneratorDataset,使得框架从自定义加载类中读取数据,因为其灵活性,这也是自定义方式如此受欢迎的原因,但是因为其灵活性,自定义加载类的多变性,使用过程中会出现 性能慢、内存上涨、卡死、数据条数不对应 等问题。
下面从 内部设计、自定义数据集类用法、适用场景、常见问题 等角度来一步步说明。
内部设计
MindSpore Dataset runtime层是在C Layer,支持的自定义能力均是通过 C++ 调用 python函数的方式实现,如下图:
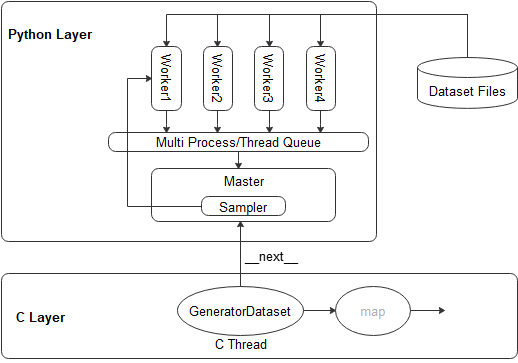
GeneratorDataset 在 C Layer是单线程执行,与Python的交互是调用 python自定义类的 __next__ 方法,基于此方式,实现C++调用python逻辑;
在Python层,Master线程(与C Layer属同一线程)负责拉起多进程 / 多线程 Worker,每个Worker根据Sampler逻辑接收Sample ID,然后根据Sample ID读取对应的 Dataset Files,读取成功后返回给 Master,最后由Master传递给GeneratorDataset。其中的Master 与 Worker的通信是通过 queue.Queue(多线程模式) 或者 multiprocessing.Queue(多进程模式) 来实现。
从上图可以看到,中间的数据传递主要有:
C层将Sample ID传递给 Python层;
Master将Sample ID传递 通过Queue传递给 Worker,所有Worker分别独立并发运行;
Worker在完成Dataset Files Load后,将Numpy Tensor通过Queue传递给Master;
Master将Numpy Tensor传递给 C层。
同时,对于上图中 Worker 是支持多进程模式 / 多线程 模式的,用户仅需要通过 GeneratorDataset(python_multiprocessing=True/Flase)来控制是启动 多进程模式 / 多线程模式,且通过 GeneratorDataset(num_parallel_workers) 来控制多进程 / 多线程 的个数,以保证并发数据加载效率。
最后,因为 Master 与 Worker 之间数据传递均是基于 Queue 实现,在多进程模式下,如果 Worker 传递给 Master的数据比较大(MB级别,有时甚至达几百MB),Python提供的 multiprocessing.Queue 效率会很低,故:Dataset模块实现了一种更高效的 _SharedQueue(共享内存方式),用于加速 Worker至Master 的数据传递,这个_SharedQueue的默认大小是 6M,体现为 GenenratorDataset(max_rowsize=6) 参数。即:该默认值在Worker至Master的数据小于6M时,是高效的,如果 Worker至Master的数据大于6M,会有日志 Using shared memory queue, but rowsize is larger than allocated memory ... 提示,此时,需要用户根据日志提示将 GenenratorDataset(max_rowsize=xx) 调大来保证 Worker至Master 数据传递的高效。
自定义数据集用法
根据自定义数据集类写法的不同,分成两种类型:Mappable 和 Iterable。Mappable类型因为其类方法有 __getitem__ 方法,可以支持随机访问,即:支持类对象通过下标方式访问其中的指定index的数据,而Iterable类型因为是纯迭代方式,整个数据集是以顺序的方式加载,不支持随机(即:下标方式)访问。
所以,基于以上原因,Mappable方式的自定义数据集类可以支持 多进程/多线程 并发加载,每个进程/线程只加载数据集的一部分,实现高效加载,而Iterable方式的自定义数据集类,因为其只能以顺序的方式加载,所以不支持多进程/多线程并发加载逻辑。
故:建议用户优先使用 Mappable方式 的定义数据集类,通过Mappable实现不了的,再通过 Iterable方式 定义数据集类。
具体自定义数据集的用法及举例如下:
2.1 Mappable类型自定义方式,支持Python多进程/多线程模式
Mappable类型自定义方式,类必须包含 __init__(类成员初始化),__getitem__(按特定index加载数据,也是按下标方式访问数据的接口),__len__(定义数据集的总样本数),举例如下:
class UDFDataset: # 该自定义数据集每个样本包含2列,分别为:data和label
def __init__(self): # 类成员初始化
self._data = np.random.sample((5, 2))
self._label = np.random.sample((5, 1))
def __getitem__(self, index): # 按特定index加载数据,也是按下标方式访问数据的接口
return self._data[index], self._label[index]
def __len__(self): # 数据集的总样本数
return len(self._data)将 UDFDataset 类对象,传递给 GeneratorDataset,即可以实现数据集的加载。同时,通过 python_multiprocessing=True/Flase,num_parallel_workers=xx,max_rowsize=xx三个参数来实现 多进程/多线程、并发数 和 _SharedQueue(共享内存方式)大小,以实现最高效的数据加载。
data = UDFDataset()
dataset = GeneratorDataset(source=data, column_names=["data", "label"]) # source传入用户自定义数据集类对象,column_names指定每个样本的列名,与 `__getitem__` 中return的列数相等,该列名主要是用于后续的 `dataset.map(...)` 数据增强阶段使用
for item in dataset.create_dict_iterator(output_numpy=True): # 通过 create_dict_iterator 接口迭代循环输出数据集数据
print(item)下面以ImageNet数据集为例,验证 python_multiprocessing=True/Flase,num_parallel_workers=xx,max_rowsize=xx 三个参数对数据集加载效率的影响:
注意: 其中使用 time.sleep(0.2) 代表耗时操作,整个加载类模拟IO密集型任务。
import mindspore.dataset as ds
from mindspore.dataset import GeneratorDataset
import time
import os
import numpy as np
import cv2
# ds.config.set_enable_sha 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2219
2219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









