






由于我使用的环境数据并不是大部分人常用的worldclim上下载的气候数据,而是使用不同的四类环境数据,分别包括:降雨数据、气温数据、氮沉降数据和大气CO2浓度数据,数据需要分别从不同的网站下载,因此并不能得到非常一致的数据文件,导致MaxEnt运行时出现了各种各样的错误。我遇到的错误类型主要包括以下3种:
1、地理维度不一致
这种问题最常遇到,要求参与运算的环境变量必须具有同样的坐标系、分辨率与行列号,最好在一开始就严格统一,可以很大程度上减少各种问题出现。
为操作简便,可在一开始就在【地理处理】的【环境】中将坐标系、分辨率和行列号固定,参考文章:
(8条消息) ArcGIS:栅格对齐并保持行列号一致,方法2_智野空间的博客-CSDN博客
如果还是出现这类问题的提示,可能是由于栅格边界不一致,虽然大致看起来栅格是重合的,但是放大后你可能会发现两幅栅格还是出现了偏差。所以在裁剪栅格或掩膜提取时,一定要以其中一个环境变量的边界为基准,提取其他栅格的边界。
划重点:坐标系、分辨率(像元大小)、行列号、边界范围必须完全一致!!
2、计算文件时突然中止

出现上图所述的问题时,检查环境变量是否具有相同的行列号。
由于我在最开始做实验时没有考虑到行列号问题,导致文件无故结束的现象。
网络上有人给出用notepad++的方法,说可以将开头几行的行列号大小改成一致的,即下图我框选出的几行。

但这种方法对我无效,原因在于:
(1)检查ASCII文件,即使开头行列号数字被修改,但实际的数据仍然是原来的行列数,文件无法正常运算
(2)行列号修改,原始数据也被修改,发生扭曲变形,最终得到的MaxEnt结果图就是残缺的,如下图所示,并且在运行过程中也会提示数据缺失,这是因为采样点和栅格位置不能很好地匹配
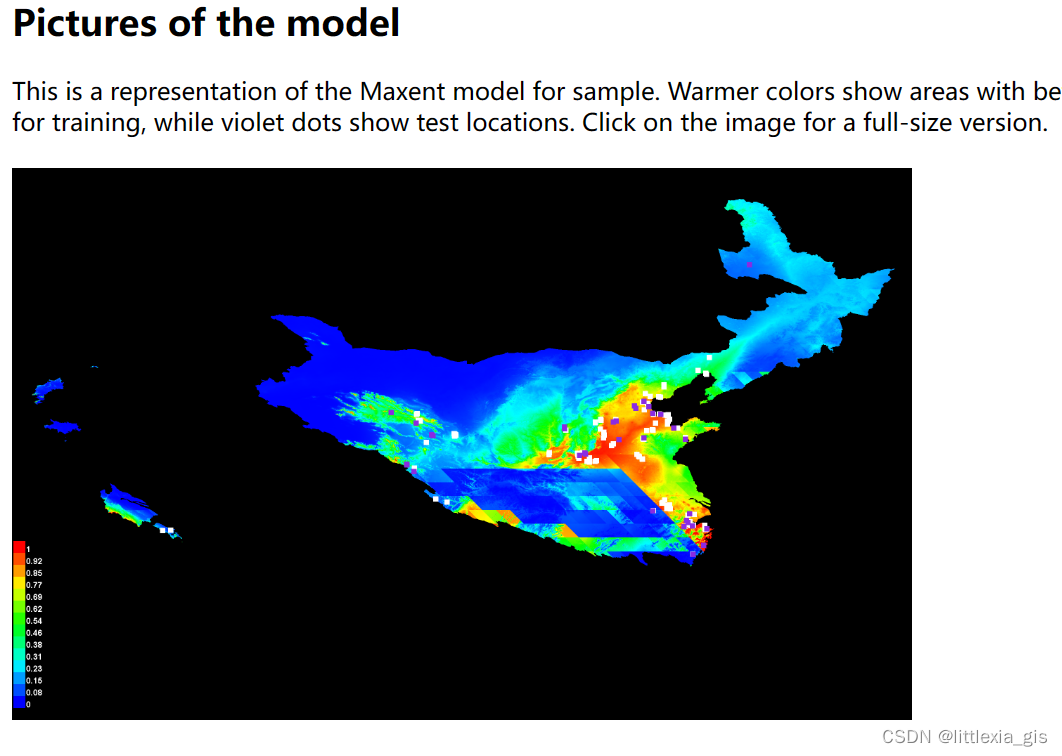
既然是修改行列号,那不如在最开始就将行列号统一,也就避免了这类问题的发生。
3、计算文件后弹出:for input string:"-nan"
文件终于能够读取了,然而计算到一半又弹出第三种问题,根据弹出的报错提示,找到错误所在那一行,用Notepad++打开,可以发现,这一行确实存在nan值,导致文件读取无法正常进行。
我用的一个粗暴的办法是,直接将这一行修改为-9999,复制下面的那一行到报错的nan值行,导入到ArcGIS中,肉眼看不出有什么差异。将修改后的文件重新放入MaxEnt中运行,发现文件终于可以正常计算。(不知道这种方法是否科学,还请同行批评指正)
(下图是有nan值的展示)
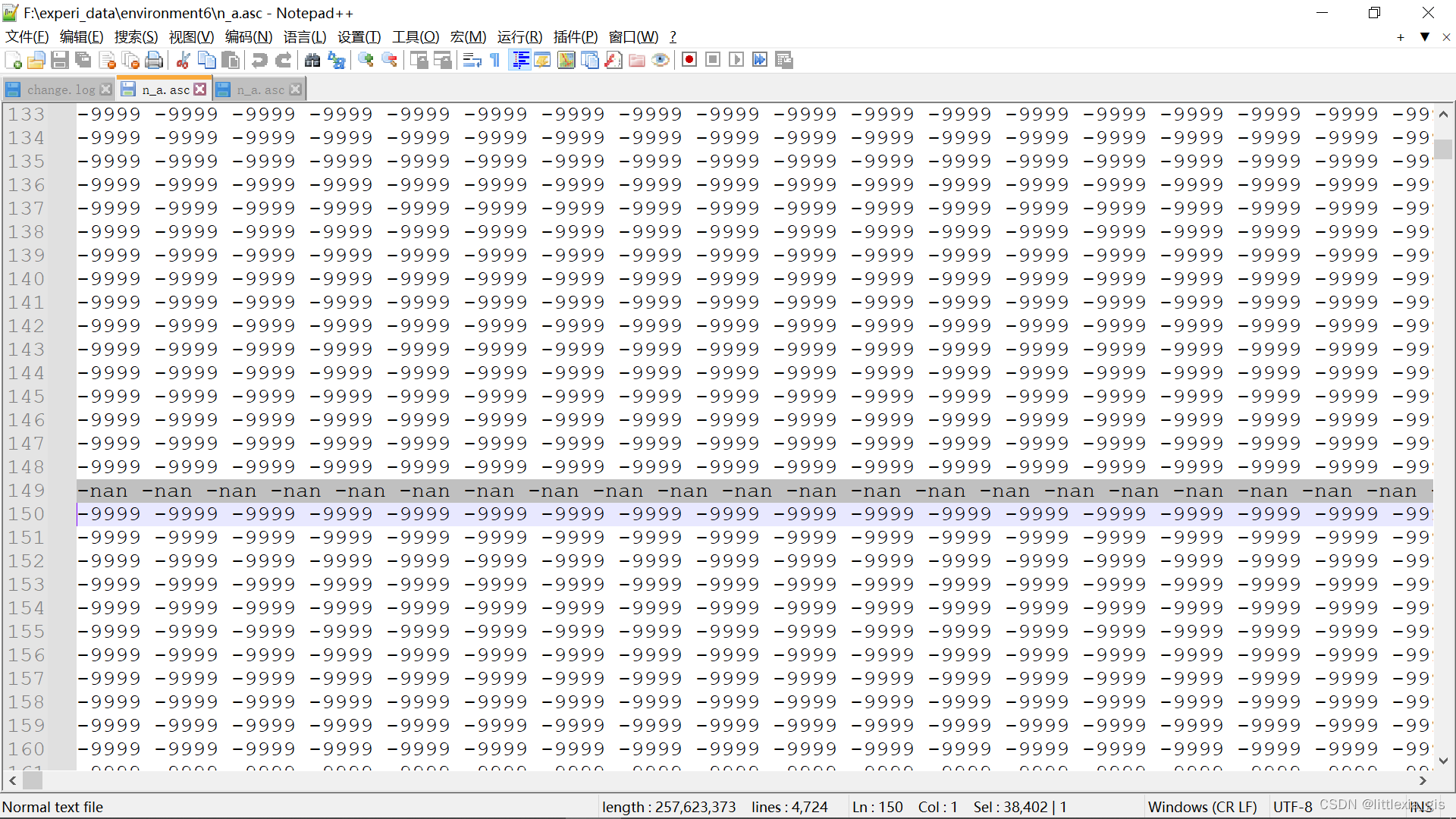
如果是字符串时其他错误的类型,应该也可以用类似的方式修改。
目前遇到了这些问题,后续还将继续探索MaxEnt模型的使用方法。

















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









