







Matlab学习随手记
Matlab基础操作
初始化
1、清空命令行窗口
clc;
2、清空工作区
clear;
3、关闭所有图形窗口
close all;
以上3种操作经常同时出现在同一行用于所有代码执行前的初始化:
clc;clear;close all;
其中1、 、2、常用于每节代码执行前的初始化:
clc;clear;
数值运算
a=2;
b=3;
c2=a+b;
c3=a*b;
c4=a/b;
c5=a^(2);
c6=b^(1/3);
c7=exp(2);
c8=log2(8);
c9=log(8);
c10=log10(10);
c11=sqrt(8)
c12=power(2,3)
c13=pow2(4) % 2的4次方
c14=nextpow2(5) % 大于等于5的最小整数c14,使2的c14次方大于等于5
c14=expm(2) % e^2 - 1
%% 变量类型转换
disp(c10) % 将c10转化为字符串
%% 取数
mod(b,a); % b/a 的余数
fix(-2.9) % 向0取整,值为-2
floor(2.2) % 对2.2向上取整
ceil(2.2) % 对2.2向下取整
floor(3.7) % 向-∞取整,值为3
round(-2.9) % 四舍五入,值为-3
roundn(-2.98765, 1) % 对-2.98765保留1位小数的四舍五入,值为-3.0000
%% 三角函数
sin(); cos(); sinpi(); cospi() ;tan()
%% 反三角函数
asin(); acos(); asind(); acosd(); atan(); atand(); atan2()
%% 统计学变量
max(); min(); sum(); mean();
prod([1, 2, 3, 4]) % 数组或矩阵中所有元素的乘积,值为24
prod([1, 2; 3, 4]) % 12 8
median() % 中位数
var(); % 方差
std(); % 标准差
cov(); % 协方差
%% 自定义函数
function[输出形参表: output1, ...,outptn] = 函数名(输入形参表: input1, ... , inputn)
函数体代码部分
end
my_max.m % 把函数储存在my_max.m文件中,可省略(后果是只能在当前.m文件中使用,不可在其他脚本中复用)
function [maxval]= my_max(L)
maxval=L(1);
for ii=2:length(L)
if maxval<L(ii)
maxval=L(ii);
end
end
end
矩阵运算
1、矩阵初始化
ju1=[1,2,3] % 行矩阵
ju2=[1 2 3] % 矩阵
ju3=[1;2;3] % 列矩阵
%%
ju4=[1,3,1,1/3;1/3,1,1/2,1/5;1,2,1,1/3;3,5,5,1];
ju5=randperm(10,5); % 在1-10范围内随机取5个整数
ju6=rand(10,5); % 在0-1范围内随机矩阵
ju7=zeros(3,6); % 3×6零矩阵
ju8=ones(3,6); % 3×6一矩阵
ju9=eye(3,6); % 3×6 (伪)单位矩阵
%%
ju10=1:10;
ju11=1:2:10;
ju12=linspace(1,10,5);% 1到10 之间均匀撒5个点
2、矩阵操作
matrix=[1,3,1,1/3;1/3,1,1/2,1/5;1,2,1,1/3;3,5,5,1];
[m,n]=size(matrix); % 得到矩阵的 行数和列数
m1=size(matrix,1); % 得到矩阵的行数
n1=size(matrix,2); % 得到矩阵的列数
n2=length(matrix);
mum1=matrix(1,3); % 取出矩阵的第一行,第三列
num2=matrix(1,:); % 取出矩阵的第一行
num3=matrix(:,1); % 取出矩阵的第一列
% 当然也支持矩阵多行多列选取
label=[1,3];
num4=matrix(label,:);
其中matrix(1,:)表示选取矩阵的第一行和所有列,:在这里表示1:end。
而matrix(label,:)表示选取label这个矩阵的行和列,:在这里表示1和2。
3、矩阵运算
ju1=4*ones(10,5); % 10行5列的全为4矩阵
ju2=8*ones(5,2); % 5行2列的全为8矩阵
ju3=ones(4,4); % 4行4列的全为4矩阵
ju4=6*ones(10,5); % 10行5列的全为6矩阵
ju5=2*ones(4,4); % 4行4列的全为2矩阵
%%
ju3+ju5 % 矩阵ju3与ju5相加
ju3-ju5 % 矩阵ju3与ju5相减
%%
num1=ju1*2; % 将矩阵num1赋值为 矩阵ju1 乘 2
num2=ju1.^(1/2); % 将矩阵num2赋值为 每个元素做平方根运算的矩阵ju1
%%
num3=ju3*ju5; % 将矩阵num3赋值为 矩阵ju3 乘 ju5
%%
num4=ju3.*ju5; % 将矩阵num4赋值为 矩阵ju3每一个对应元素 乘 矩阵ju5每一个对应元素
%%
num5=ju3/ju5; %等效于ju3的逆矩阵与ju5相乘
num6=ju3./ju5; % 矩阵ju3每一个对应元素 除以 矩阵ju5每一个对应元素
[ju3,ju5] % 水平方向合并,行数要相同
%%
[ju3;ju5] % 竖直平方向合并 ,列数要相同
4、矩阵函数
先给出一个矩阵:
ju1=[ 0.6472 0.2289 0.1946 0.7796 0.4582
0.7360 0.3010 0.1496 0.1583 0.8554
0.8710 0.4099 0.8552 0.7292 0.1318
0.8671 0.1923 0.9307 0.1935 0.6139];
关于这个矩阵的一些统计学变量:
max(ju1) % 矩阵列最大值
max(ju1') % 矩阵行最大值
%%
max(max(ju1)) % 所有矩阵的最大值
%%
[A,B]=max(ju1) % 最大值和所在位置
平均值mean、最小值min、标准差std与以上举的最大值max的用法都是一样的
外部数据的导入
1、xlsread
功能:只读数据,不读表头。
data_table=xlsread('附件1 近5年402家供应商的相关数据.xlsx','企业的订货量(m³)');
% 如果没有逗号后面的内容,则默认读第一个Sheet
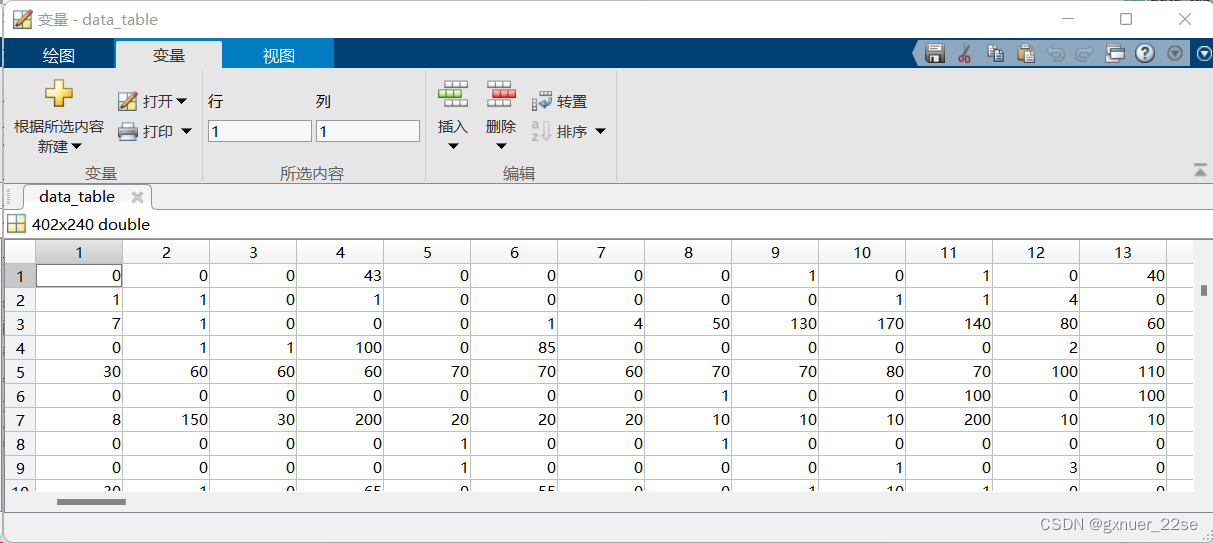
2、readmatrix
功能:既读数据,又读表头,表头为NaN。
data_table2=readmatrix('附件1 近5年402家供应商的相关数据.xlsx','Sheet','企业的订货量(m³)');

加上以下代码,可使readmatrix与xlsread效果相同(即只读数据,删除表头):
data_table2(:,[1,2])=[]; % 对所有行和对应1,2两列的NaN赋值为空
3、readtable
功能:既读数据,又读表头,表头保留。
data_table3=readtable('附件1 近5年402家供应商的相关数据.xlsx','Sheet','企业的订货量(m³)');
data_table4=readtable('附件1 近5年402家供应商的相关数据.xlsx','Sheet','供应商的供货量(m³)');
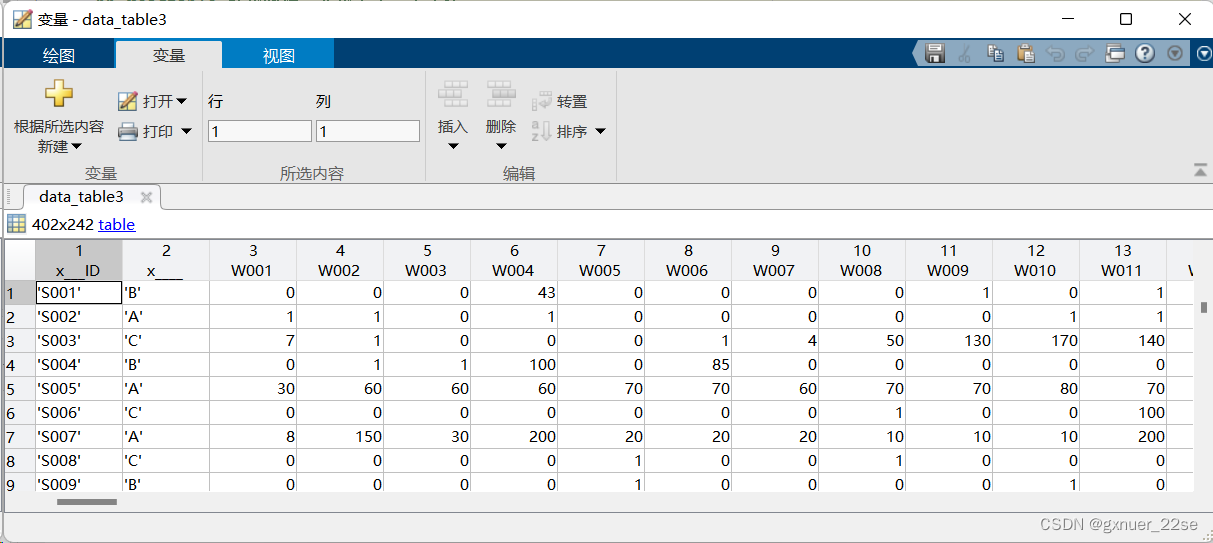
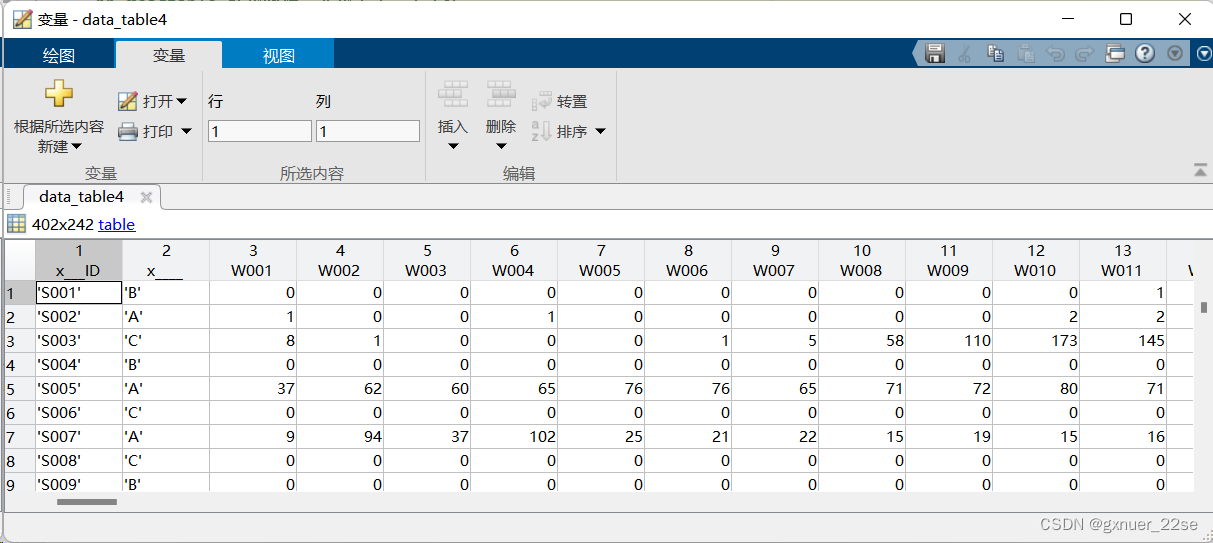
4、readcell
功能:既读数据,又读表头,表头保留,每个数据为一个元胞。
data_table5=readcell('附件1 近5年402家供应商的相关数据.xlsx','Sheet','企业的订货量(m³)');
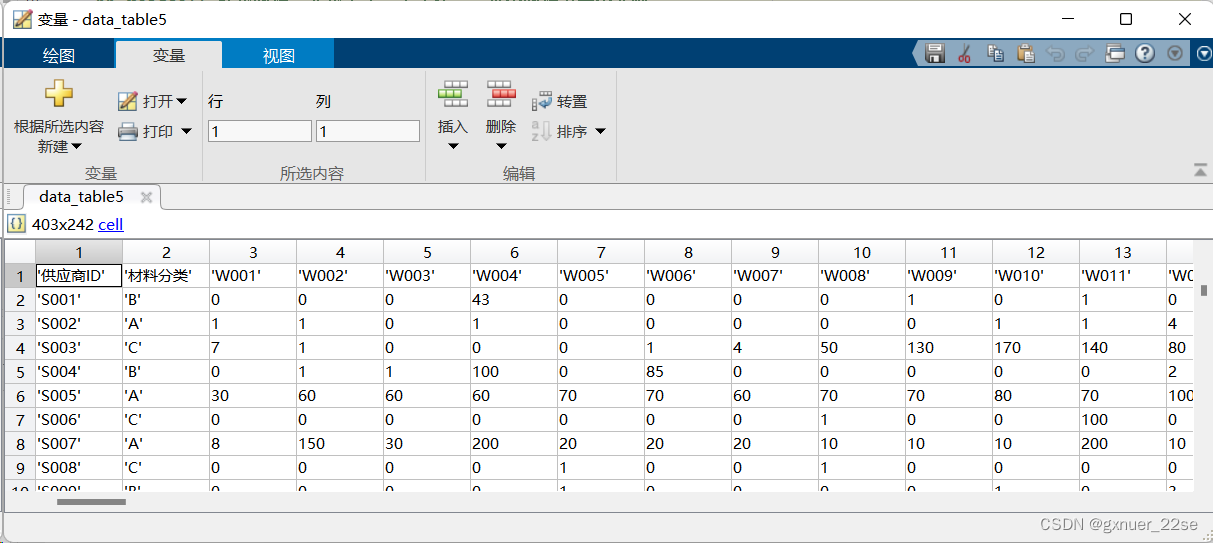
以(2, 3)元胞为例:

5、load
功能:导入历史.mat文件中的数据。
load('带缺少数据.mat');
不常用。
6、总结
不管导入成什么数据,都要把数据内容转化为矩阵形式。
需要用到函数table2array():
data=data_table3(:,3:end); % 导入所有的行和第3~最后一列(:等价于1:end)
data1=table2array(data); % 企业订货量
data2=table2array(data_table4(:,3:end)); % 供应商供货量
在以上介绍的5种函数中,最常用的是3、readtable。
下面以2021年全国大学生数学建模大赛C题的数据为例,介绍一些对外部数据操作的典例。
外部数据的操作
外部数据导入说明
先导入2021年全国大学生数学建模大赛C题的附件1 近5年402家供应商的相关数据.xlsx的第二个表单供货商的供货量(m³)
data_table4=readtable('附件1 近5年402家供应商的相关数据.xlsx', 'Sheet', '供货商的供货量(m³)');
data2=table2array(data_table4(:,3:end));
1、求每个供应商 最大值,最小值,平均值
data_max=max(data2'); % max对每一行对应的列进行操作
data_max=min(data2'); % min对每一行对应的列进行操作
data_mean=mean(data2'); % mean对每一行对应的列进行操作
在此写成data2'而不是data2是因为'的功能是转置矩阵,由于本题数据中行是供应商,列是订货量,max()、min()、mean()都是对每一列进行操作,要先把矩阵原来的行变为列,因此**要把矩阵先转置才能用max()、min()、mean() **求每一个供应商的供应量的最大值、最小值、平均值。
2、求所有供货量不为0的供货商的数据及统计学变量
求供应商1的供货量不为0的数据和次数:
data_shang1=data2(1,:);
index1=find(data_shang1~=0)
num_index1=length(index1);
由此推广到求所有供货量不为0的供货商的数据和次数:
data_shangall=zeros(1,size(data2,1))
for i=size(data2,1)
data_shang=data2(i,:);
index=find(data_shang~=0);
num_index=length(index);
data_shangall(i)=num_index;
end
当然,我们还可以求每个供应商供货量的平均数:
data_shangall=zeros(1, size(data2,1));
for i=size(data2, 1)
data_shang=data2(i,:);
index=find(data_shang~=0);
data_mean=mean(data_shang(index));
data_shangall(i)=data_mean;
end
注意!这里的find()函数只会返回满足括号里条件数据的索引值而不是数据本身!
3、找到矩阵的缺失值并删除所在行或列
在数学建模比赛中,赛方给的数据集中经常会有含NaN的数据,这时我们要把含NaN的行删除,这是数据预处理中数据变换的要求。
先导入一个.mat文件,里边有我们处理过的含有NaN的数据:
load('带缺少数据.mat'); % 其中含有data_nan.mat
然后使用布尔函数isnan()将每一行(列)为NaN的数据标注出来,返回索引值:
index=isnan(data_nan);
如果存储NaN数据索引值的矩阵中每行元素的和大于1,则说明此行有NaN值,将其赋值为空即可删除:
index1=find(sum(index')~=0);
data_nan1=data_nan;
data_nan1(index1,:)=[];
以上是原理,以下为上述过程的最简版本:
load('带缺少数据.mat'); % 其中含有data_nan.mat
data_nan(any(isnan(data_nan), 2), :) = [];
any() 函数会返回一个列向量,表示每行是否包含 NaN。如果某行中有任何一个元素为 NaN,则该行对应位置为1,否则为0。
4、找出类属于A,B,C的数据,存储并统计
当遇到数据集中表头分属不同类别事物的时候,我们往往需要把属于不同类别的数据单独取出处理,那么就要进行分类统计。
步骤如下:
-
表文件转化为cell
-
分别统计A,B,C个数
-
将A,B,C存在不同的元胞里分别找出并将文字标签修改为数字标签
-
将A,B,C分类统计
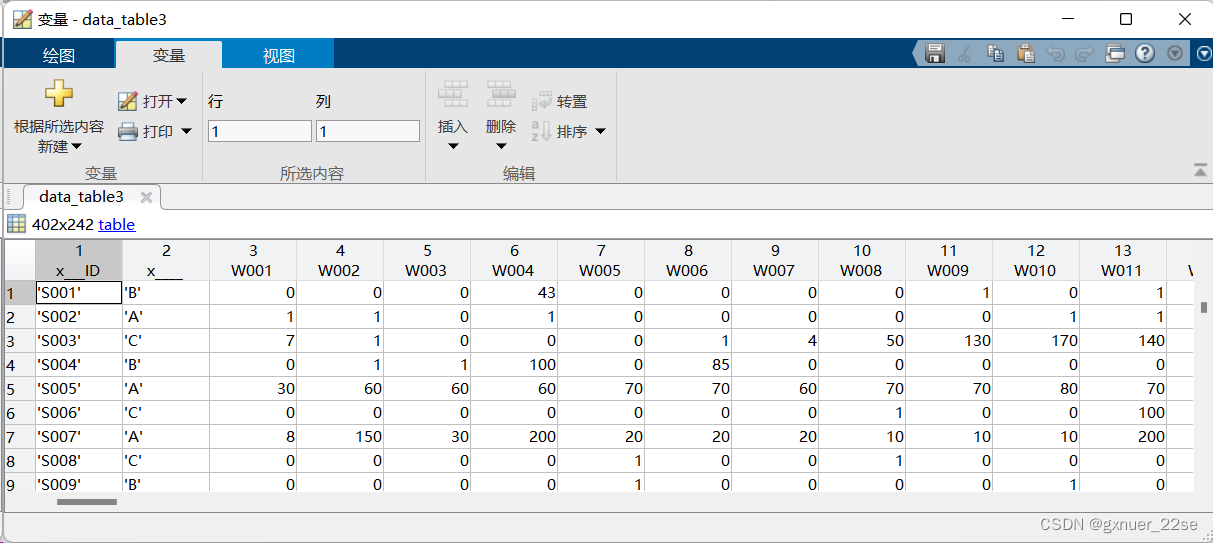
首先是表文件转化为cell:
data_abc=data_table3(:,2); % 将第2列取出来,data_table(2,:)%将第2行取出来(2,3)
data_abc_num=table2array(data_abc); % 表文件转化为cell
table2array()本来用于将将表格(table)转换为数组(array),但此时data_table3(:,2)显然全是A,B,C这样的字符串,因此在这种情况下会将表格转换成元胞数组。
接下来是分别统计A,B,C个数:
data_tongji=tabulate(data_abc_num) % 统计ABC个数
for i=1:size(data_tongji,1)
dianli_str{1,i}=data_tongji{i,1};
end

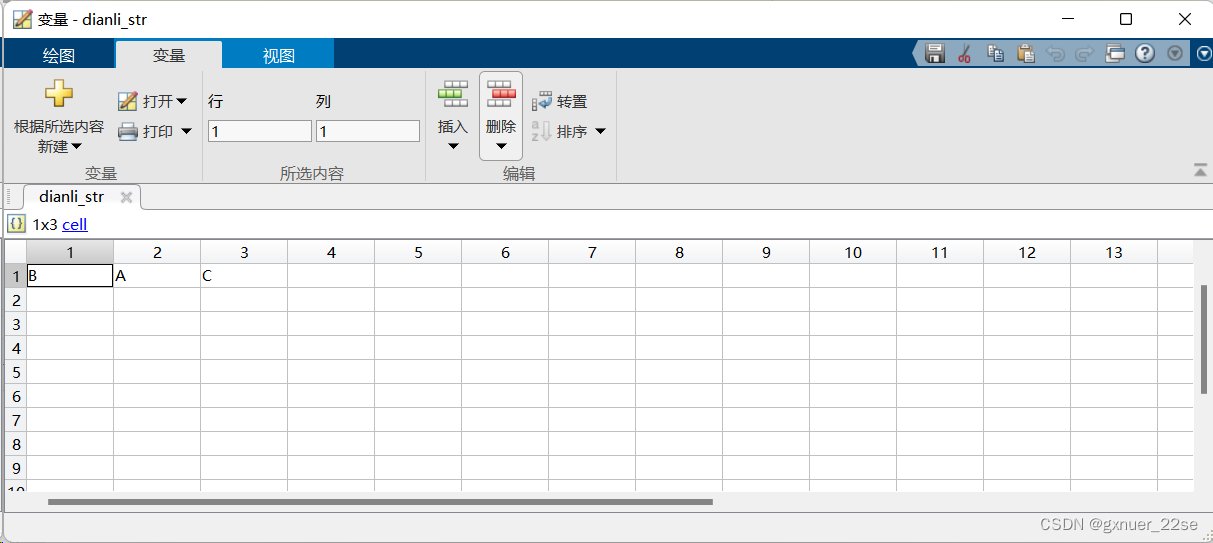
tabulate()函数用于统计输入向量中各个元素出现的次数,并以表格的形式返回结果。该函数会返回一个矩阵,其中包含三列:第一列是唯一的元素值,第二列是该元素在输入向量中出现的次数,第三列是每个元素在输入向量中的相对频率。

然后是将A,B,C存在不同的元胞里分别找出并将文字标签修改为数字标签:
data_shuju=zeros(length(data_abc_num),1);
for NN=1:length(dianli_str)
idx = find(ismember(data_abc_num, dianli_str{1,NN} ));
data_shuju(idx)=NN;
end
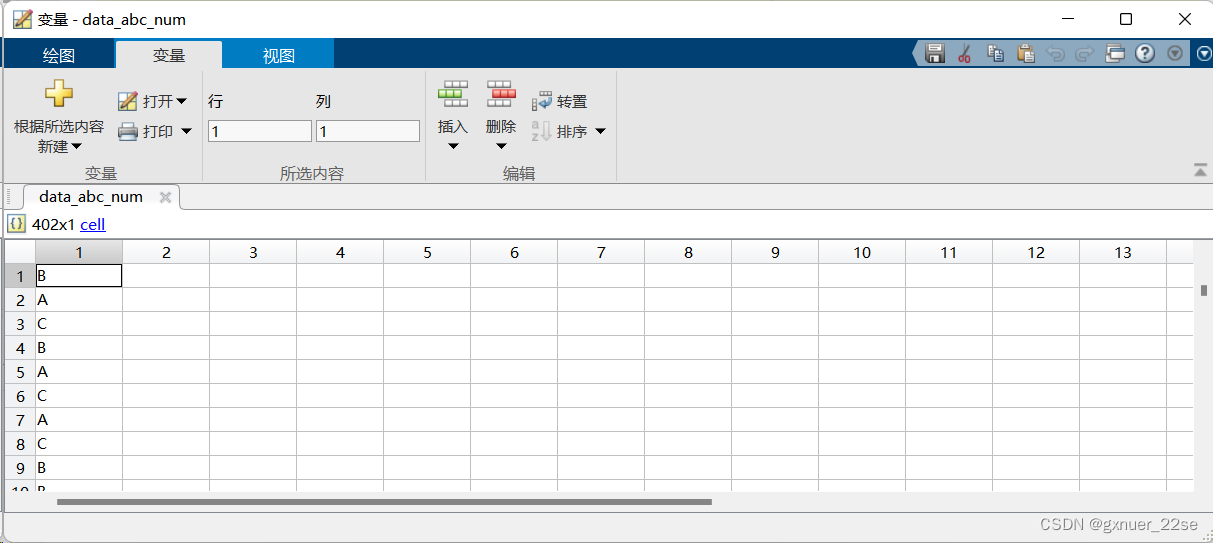
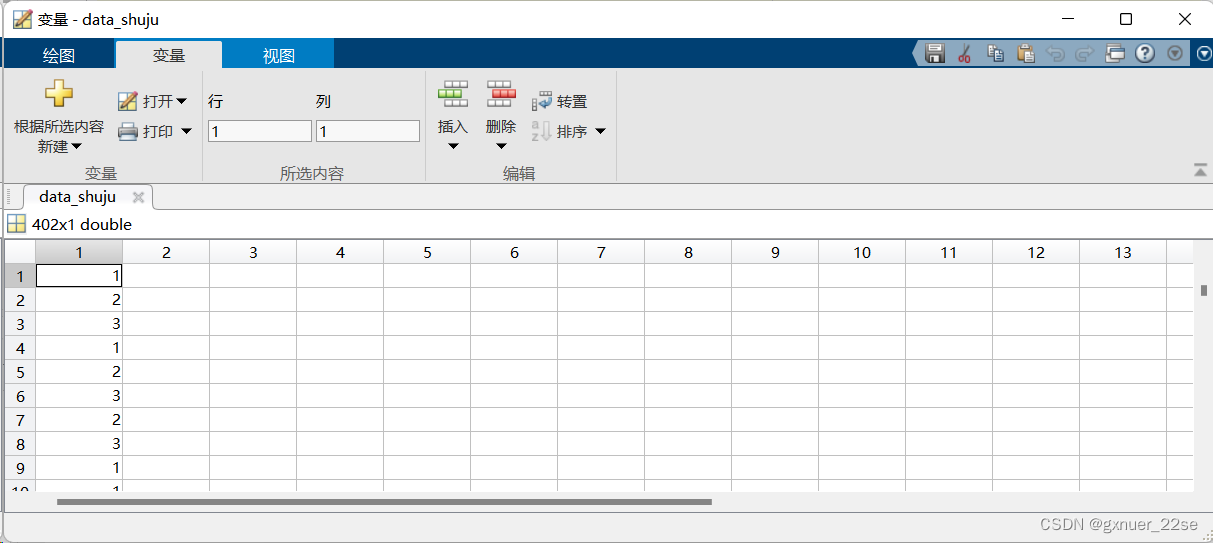
(备注:B是1,A是2,C是3)
最后我们就可以将A,B,C分类统计了:
for i=1:size(data_tongji,1) % 将不同标签行的位置分别找出来存在不同的元胞里,因为维度不一样
A(i)={find(data_shuju==i)};
end
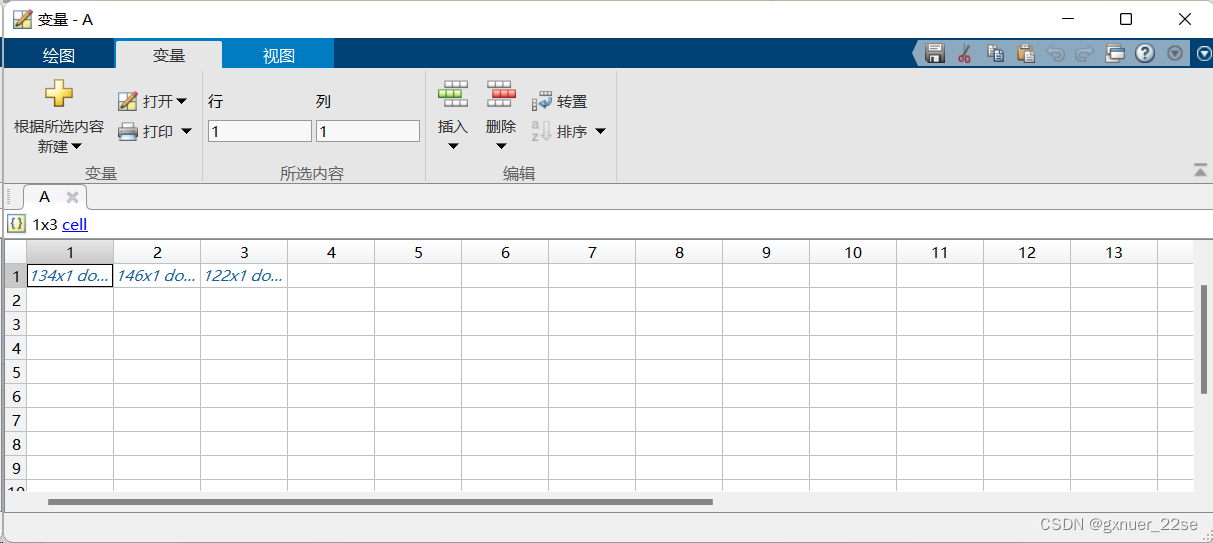
A(1, 1)为B,A(1, 2)为A,A(1, 3)为C,点开即可查看不同类别的统计结果,或用
ans=data_table3(A{1,1},:);
取出:
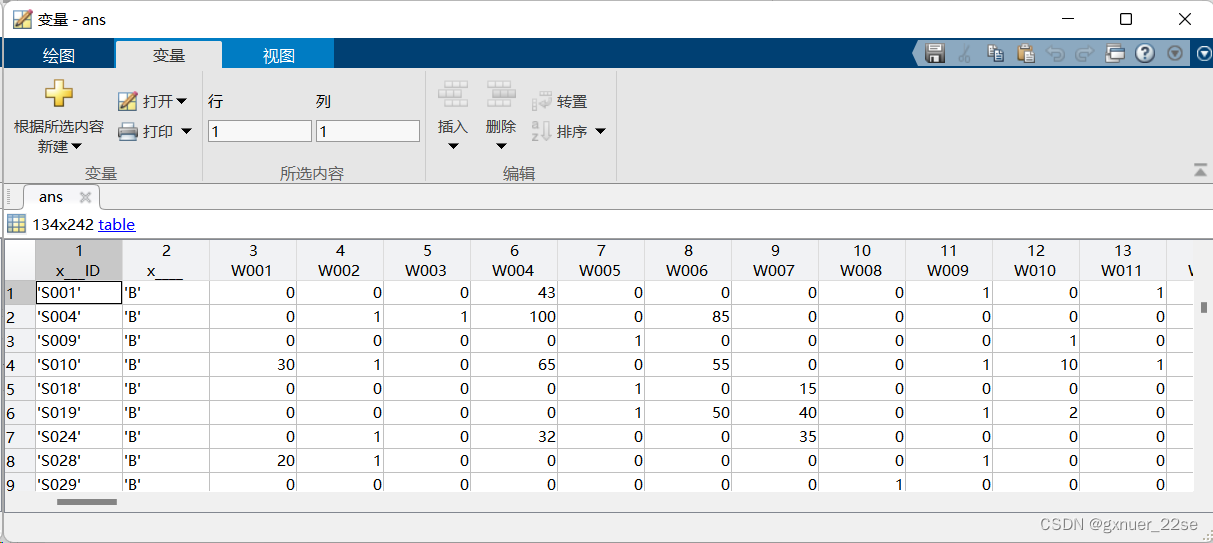
5、归一化处理
归一化:归一化是将数据转化为一定范围内的数值,通常是将数据映射到[0,1]或[-1,1]之间。归一化的目的是消除不同特征之间的量纲差异,使得不同特征具有可比性。常见的归一化方法有Z-score归一化(标准化)、最小-最大归一化(Min-Max Scaling)。
先导入数据:
data_table3=readtable('附件1 近5年402家供应商的相关数据.xlsx','Sheet','企业的订货量(m³)');
data=data_table3(:,3:end); % 导入所有的行和第3~最后一列(:等价于1:end)
data1=table2array(data); % 企业订货量
Z-score标准化:zscore()函数
定义:通过将数据减去均值并除以标准差,将数据转化为均值为0,方差为1的标准正态分布。一般适用于数据分布近似正态分布的情况,可以通过减少数据间的偏差,来使得数据更加稳定,而且有助于消除不同特征之间的量纲影响,使得不同特征之间可以进行更为公平的比较和分析。
标准化公式:
z
=
(
x
−
μ
)
/
σ
z=(x-μ)/σ
z=(x−μ)/σ
其中,x表示原始数据,μ表示数据的均值,σ表示数据的标准差,标准化后得到的z值符合标准正态分布,意味着均值为0,方差为1。
zscore()函数用于计算数据的z分数,即将数据标准化为均值为0,标准差为1的形式。具体来说,对于给定的数据向量或矩阵,会进行以下计算:
-
计算数据的均值(mean)和标准差(standard deviation)。
-
对数据进行中心化处理,即每个数据点减去均值。
-
将中心化后的数据除以标准差,从而得到标准化后的数据。
std_data=zscore(data1) ; % 对矩阵每列进行标准化
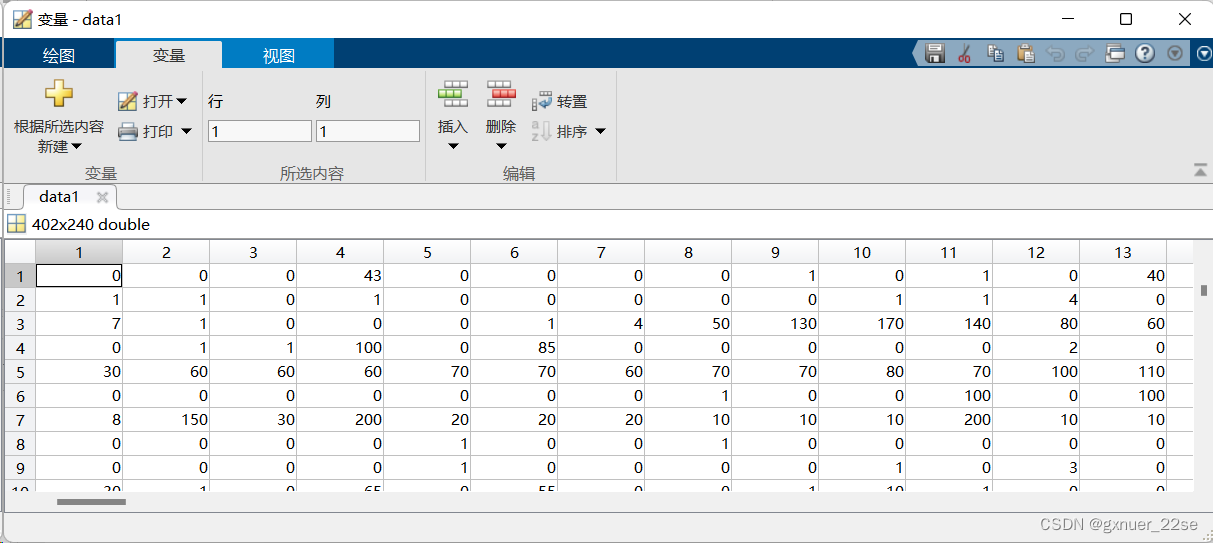

最小-最大归一化:mapminmax() 函数
定义:
最小-最大归一化公式:
X
′
=
(
X
−
X
m
i
n
)
/
(
X
m
a
x
−
X
m
i
n
)
X' = (X - Xmin) / (Xmax - Xmin)
X′=(X−Xmin)/(Xmax−Xmin)
其中,X'是归一化后的数据,X是原始数据,Xmin和Xmax分别是原始数据的最小值和最大值。
mapminmax() 函数会对给定的数据进行如下处理:
-
找到数据的最小值和最大值。
-
对数据进行线性变换,将数据缩放到指定的范围内(通常是
[0, 1]或者[-1, 1])。
这样处理后的数据集中,所有的数据点都会落在指定的范围内,从而消除了不同特征之间的量纲影响,便于进行数据分析和机器学习任务。
std_data1= mapminmax(data1', 0, 1)'; % 对矩阵每行进行标准化,要先转置矩阵
结合4、,如果像批量处理A,B,C三类数据的归一化结果,首先以对B类数据进行标准化为例:
B_data=data1(A{1,1},:);
std_B_data=zscore(B_data);
A{2,1}=std_B_data;
由此可推广为对A,B,C三类数据的批量归一化操作:
for i=1:length(A)
B_data=data1(A{1,i},:);
std_B_data=zscore(B_data);
A{2,i}=std_B_data;
end
6、3σ原则处理异常值
数据清洗的重要一步。
正态分布的3σ原则:数值分布在(μ-σ,μ+σ)中的概率为0.6827;数值分布在(μ-2σ,μ+2σ)中的概率为0.9545;数值分布在(μ-3σ,μ+3σ)中的概率为0.9973,可以认为,Y的取值几乎全部集中在(μ-3σ,μ+3σ)区间内,超出这个范围的可能性仅占不到0.3%。
cleaned_data = data1; % 创建一个副本来存储处理后的数据
for i = 1:size(data1, 1)
data_te = data1(i, :);
data_mean = mean(data_te); % 算平均数μ
data_std = std(data_te); % 算标准差σ
index = data_te < (data_mean - 3 * data_std) | data_te > (data_mean + 3 * data_std); % 3σ原则
cleaned_data(i, index) = NaN; % 使用逻辑索引保留非异常值
end
% 删除包含 NaN 的行
cleaned_data(any(isnan(cleaned_data), 2), :) = [];

图像绘制
二维图像绘制
-
绘制单条曲线
x = 0:pi/100:2*pi; y = sin(x); plot(x,y)
-
绘制多条曲线
x = linspace(-2*pi,2*pi); y1 = sin(x); y2 = cos(x); plot(x,y1,x,y2)
-
绘制多条曲线(利用矩阵,将矩阵的每一列绘制为单独的线条)
Y = magic(4); plot(Y)
-
指定线型
x = 0:pi/100:2*pi; y1 = sin(x); y2 = sin(x-0.25); y3 = sin(x-0.5); plot(x,y1,x,y2,'--',x,y3,':')
线性查找表
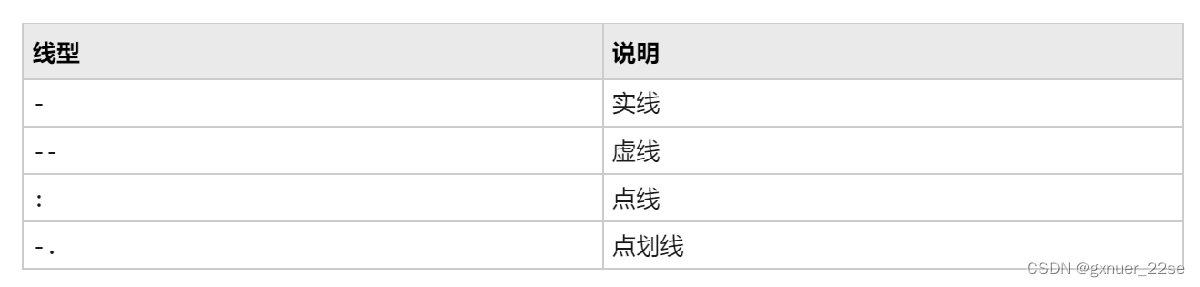
-
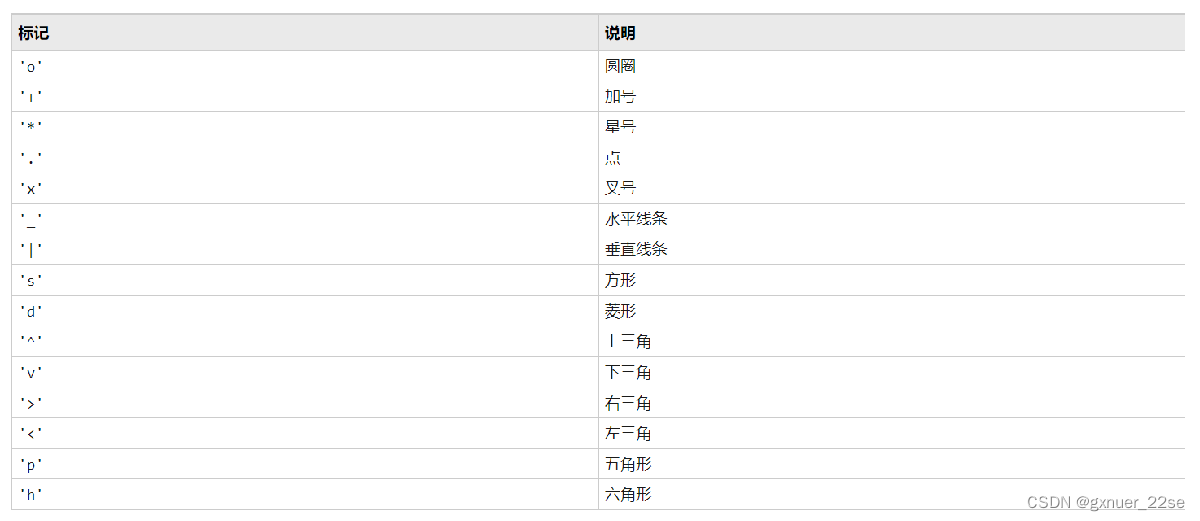
指定标记
x = 0:pi/10:2*pi; y1 = sin(x); y2 = sin(x-0.25); y3 = sin(x-0.5); plot(x,y1,'g',x,y2,'b--o',x,y3,'c*')

-
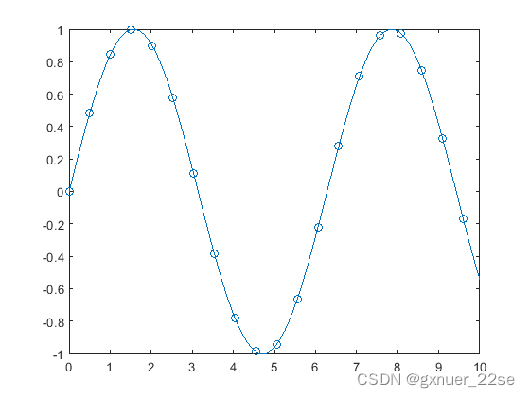
指定标记(在特定的点处)
x = linspace(0,10); y = sin(x); plot(x,y,'-o','MarkerIndices',1:5:length(y))
标记查找表
-
指定线宽、标记大小和标记颜色
x = -pi:pi/10:pi; y = tan(sin(x)) - sin(tan(x)); plot(x,y,'--gs',... 'LineWidth',2,... 'MarkerSize',10,... 'MarkerEdgeColor','b',... 'MarkerFaceColor',[0.5,0.5,0.5])
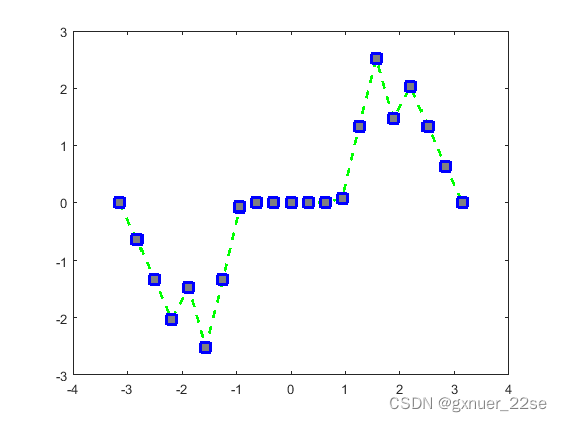
颜色查找表

-
添加标题和轴标签
x = linspace(0,10,150); y = cos(5*x); plot(x,y,'Color',[0,0.7,0.9]) title('2-D Line Plot') xlabel('x') ylabel('cos(5x)')
-
绘制持续时间并指定刻度格式
t = 0:seconds(30):minutes(3); y = rand(1,7); plot(t,y,'DurationTickFormat','mm:ss')

1、散点图绘制
-
创建散点图
x = linspace(0,3*pi,200); y = cos(x) + rand(1,200); scatter(x,y)
-
改变点的大小
x = linspace(0,3*pi,200); y = cos(x) + rand(1,200); sz = linspace(1,100,200); scatter(x,y,sz)
-
改变点的颜色
x = linspace(0,3*pi,200); y = cos(x) + rand(1,200); c = linspace(1,10,length(x)); scatter(x,y,[],c)
-
改变点的填充
x = linspace(0,3*pi,200); y = cos(x) + rand(1,200); sz = 25; c = linspace(1,10,length(x)); scatter(x,y,sz,c,'filled')

-
改变标记符号
theta = linspace(0,2*pi,150); x = sin(theta) + 0.75*rand(1,150); y = cos(theta) + 0.75*rand(1,150); sz = 140; scatter(x,y,sz,'d')
2、直方图绘制
- 创建直方图
x = 1900:10:2000;
y = [75 91 105 123.5 131 150 179 203 226 249 281.5];
bar(x,y)
更改横坐标
X = categorical({'Small','Medium','Large','Extra Large'});
X = reordercats(X,{'Small','Medium','Large','Extra Large'});
Y = [10 21 33 52];
bar(X,Y)
-
堆叠直方图
x = [1980 1990 2000]; y = [15 20 -5; 10 -17 21; -10 5 15]; bar(x,y,'stacked')
3、统计图绘制
-
创建统计图
x = randn(10000,1); histogram(x)
- 更改直方个数
x = randn(1000,1);
nbins = 25;
histogram(x,nbins)
-
指定每个直方柱对应的范围
x = randn(1000,1); edges = [-10 -2:0.25:2 10]; histogram(x,edges);

4、饼状图绘制
-
创建饼状图
X = 1:3; labels = {'Taxes','Expenses','Profit'}; pie(X,labels)

5、阶梯图绘制
-
创建阶梯图
X = linspace(0,4*pi,40); Y = sin(X); stairs(Y)
6、极坐标图绘制
-
创建极坐标图
theta = 0:0.01:2*pi; rho = sin(2*theta).*cos(2*theta); polarplot(theta,rho)
7、区域图绘制
-
创建极区域图
Y = [1 5 3; 3 2 7; 1 5 3; 2 6 1]; area(Y)
三维图像绘制
-
创建三维曲线图
t = 0:pi/500:40*pi; xt = (3 + cos(sqrt(32)*t)).*cos(t); yt = sin(sqrt(32) * t); zt = (3 + cos(sqrt(32)*t)).*sin(t); plot3(xt,yt,zt) axis equal xlabel('x(t)') ylabel('y(t)') zlabel('z(t)')
1、3D散点图绘制
-
创建三维散点图
z = linspace(0,4*pi,250); x = 2*cos(z) + rand(1,250); y = 2*sin(z) + rand(1,250); scatter3(x,y,z,'filled')
2、3D直方图绘制
-
创建垂直三维直方图
load count.dat Z = count(1:10,:); width = 0.5; bar3(Z,width) title('Bar Width of 0.5')
-
创建水平三维直方图
load count.dat; Y = count(1:10,:); width = 0.5; figure bar3h(Y,width) title('Width of 0.5')
3、3D统计图绘制
-
创建三维统计图
load carbig X = [MPG,Weight]; hist3(X) xlabel('MPG') ylabel('Weight')

4、3D饼状图绘制
- 创建三维饼状图
x = [1,3,0.5,2.5,2];
pie3(x)

5、3D曲面图绘制
-
创建三维曲面图
[X,Y] = meshgrid(-5:.5:5); Z = Y.*sin(X) - X.*cos(Y); s = surf(X,Y,Z,'FaceAlpha',0.5)

6、3D网格曲面图绘制
-
创建三维网格曲面图
[X,Y] = meshgrid(-8:.5:8); % 可以修改边界 R = sqrt(X.^2 + Y.^2) + eps; Z = sin(R)./R; mesh(X,Y,Z)
7、等高线图绘制
-
创建三维曲面图
x = -2:0.2:2; y = -2:0.2:3; [X,Y] = meshgrid(x,y); Z = X.*exp(-X.^2-Y.^2); contour(X,Y,Z,'ShowText','on')

总结
绘图常用指令
| 指令 | 功能 |
|---|---|
| hold on / hold off | 保持/不保持图像 |
| colorbar | 颜色栏 |
| xlim([x1,x2]) / ylim | 更改坐标轴范围 |
| xlabel / ylabel | 增加坐标轴标签 |
| title | 增加图像标题 |
| axis on/aixs off | 打开/关闭坐标轴 |
| text(x,y,’str’) | 在(x,y)处添加文字 |
| quiver(x1,y1,x2,y2) | 生成(x1,y1)到(x2,y2)的箭头 |















 4084
4084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









