







这篇文章解决的问题
作者提出,之前的工作大多专注于文本挖掘和学习文本的语义特征,他们忽略了学习谣言的传播。之前有方法使用RvNN,与标准RvNN不同的是,输入是一个从源文章而不是解析树根的传播树,每个节点代表一个帖子。他们使用GRU单元通过递归传播来更新节点表示,GRU单元并不是学习表示的完美方法,而且由于它是通过顺序传播进行训练的,因此在效率上存在一些挑战。
而且有调查指出,谣言和非谣言的传播结构也有很大不同,故谣言传播结构对于谣言检测来说也是很大的一个因素。如下图,谣言和非谣言的结构:
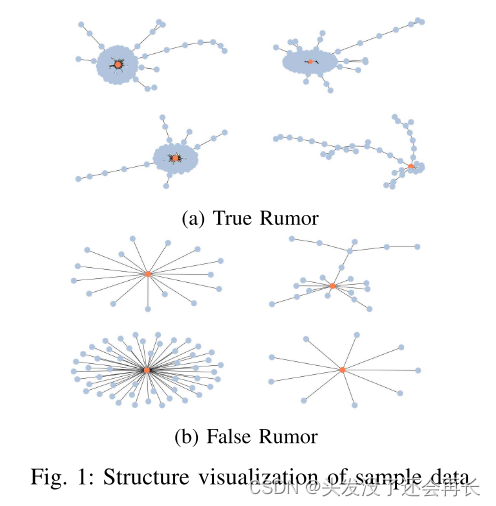
作者如何解决这个问题的
为了有效学习节点表示,作者引入GCN捕获传播信息,更新节点和邻居的关系。
为了将谣言传播结构信息利用起来,作者在使用GCN学习传播信息的同时,学习结构特征,交替使用VGAE或者GAE来进行解码,重构谣言图结构以此获取结构信息。
作者提出的模型包括三个部分:Encoder, Decoder, and Detector
如下图所示:
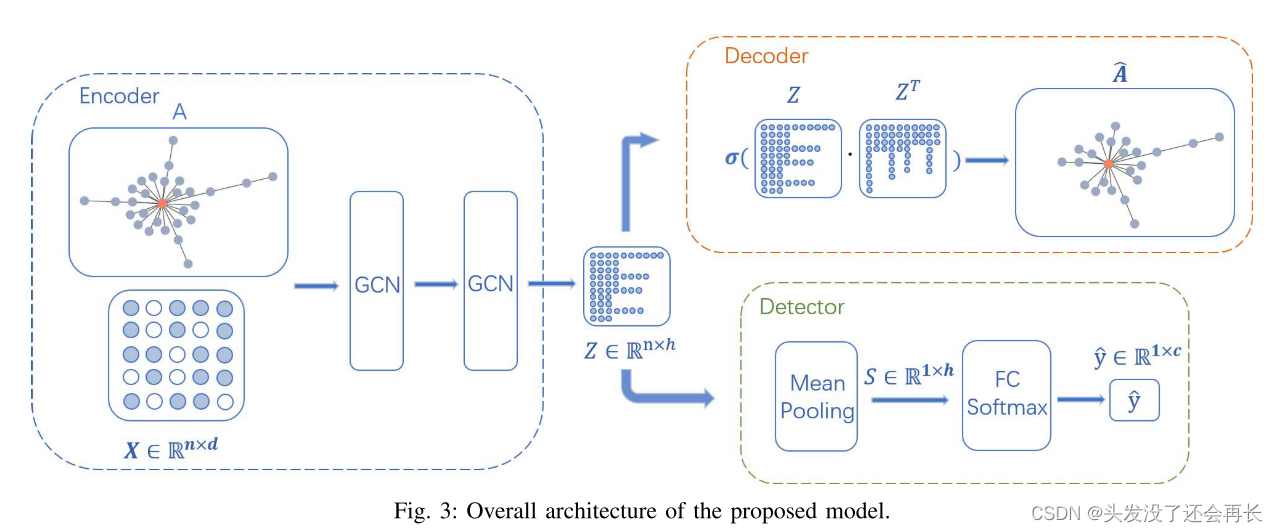
Encoder
首先,初始输入x是使用TF-IDF的单词向量,表示帖子的句子语义,A为邻接矩阵,表示帖子之间的关系。
然后GCN通过聚合邻居的特征更新节点特征。
为了后续的解码工作,结构的潜在表示也被编码在这里。整个结构信息可以同时学习。
Decoder
用Encoder得到的输出作为Decoder的输入,然后通过一个sigmoid函数得到图的重构,将得到的结构和输入的结构进行相似度对比得到损失lrec,同时,如果编码使用的是VGAE,还要计算一个KL 发散损失lkl。
Detector
这个部分用来将谣言分类,输入是Encoder的输出,通过一个Mean Pooling 和 一个softmax得到每一个输入的预测标签,将预测标签和真实标签对比求交叉熵损失得到此部分的损失ldec
最后将所有损失相加
loss = ldec + lrec + I\*lkl
其中,如果使用VGAE ,I=1, 使用GAE, I=0
这个问题的解决有什么亮点,局限
这是第一个工作整合了文本,传播信息和结构信息来检测谣言,也是第一个引入GAE和VGAE来检测谣言的模型,作者在编码的时候将帖子之间的关系图结构和文本信息同时利用起来,并在解码的时候使用VGAE得到谣言帖子间的结构特征,很好的整合和学习了三个部分的信息用于检测谣言。作者的模型在检测非谣言的时候表示不是很好。















 1392
1392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









