






关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式

论文地址:https://arxiv.org/pdf/2111.09883.pdf
源代码:https://github.com/microsoft/Swin-Transformer
计算机视觉研究院专栏
作者:Edison_G
MSRA时隔大半年放出了Swin Transformer 2.0版本,在1.0版本的基础上做了改动,使得模型规模更大并且能适配不同分辨率的图片和不同尺寸的窗口!这也证实了,Transformer将是视觉领域的研究趋势!
01

前言

Swin Transformer V2的目标是什么?存在什么问题?
论文中不止一次提到Swin Transformer V2和 V1一样,最终的目的都是为了能够联合建模NLP和CV模型。V2直接目标是得到一个大规模的预训练模型(图片分类),可以应用到其他的视觉任务(分割、识别)并取得高精度。
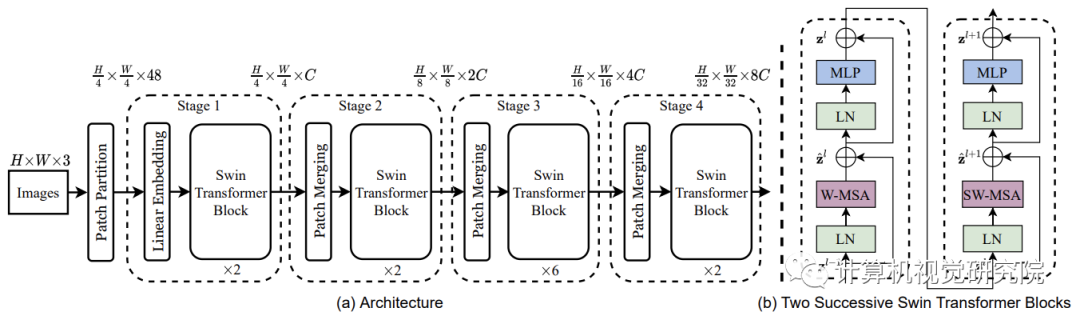
【Swin Transformer V1】
NLP目前的模型参数已经达到了千亿级别并且出现了像BERT这种成功的预训练模型可以适配不同的NLP任务;CV目前最主要的一个问题就是模型规模不够大,ViT-G参数量也只有不到20亿,并且所有大规模的视觉模型都只应用于图片分类任务。为了统一视觉和自然语言处理,CV模型存在两个问题:
不够大(模型规模不够大)
不适配(预训练与下游任务图片分辨率和窗口大小不适配)
02

背景

本文是Swin-T团队在Swin-T模型的基础上对scale up视觉模型的一个工作,在4个数据集上又重新刷到了新的SOTA文章的出发点是,在视觉领域里并没有像NLP那样,对于增大模型scale有比较好的探索,文中讲到可能的原因是:
在增大视觉模型的时可能会带来很大的训练不稳定性
在很多需要高分辨率的下游任务上,还没有很好的探索出来对低分辨率下训练好的模型迁移到更大scale模型上的方法
GPU memory cost太大
文章针对以上观察到的问题,在基于Swin-T的backbone上提出了三个改进点。
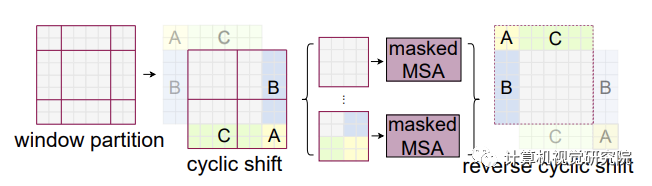
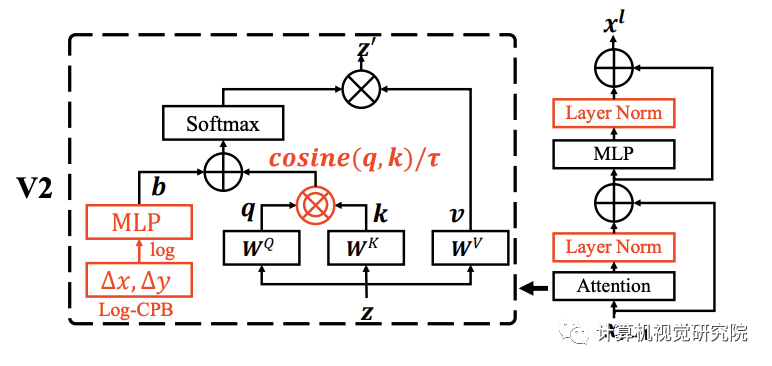
post normalization:在self-attention layer和MLP block后进行layer normalization
scaled cosine attention approach:使用cosine相似度来计算token pair之间的关系
log-spaced continuous position bias:重新定义相对位置编码
03

新框架

模型不够大的问题:
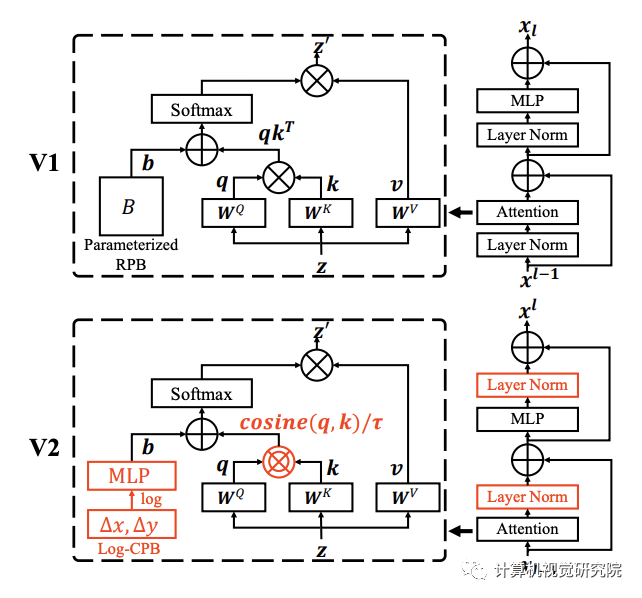
post-norm and cosine similarity:
论文中提出了SwinV2-G: C=512, layer numbers={2,2,42,2},通过增加处理数据的维度(192-->512)和Transformer层数(18-->42)增大模型规模,但是会产生一个问题:模型训练不稳定甚至不能完成训练。
通过对模型每一层输出的分析,发现随着模型变深,没层的输出是不断变大的,随着层数增加,输出值不断累加,深层输出和浅层输出幅值差很多,导致训练过程不稳定(如下图),解决这个问题就是要稳定每一层的输出,其幅值要稳定才会使得训练过程稳定。
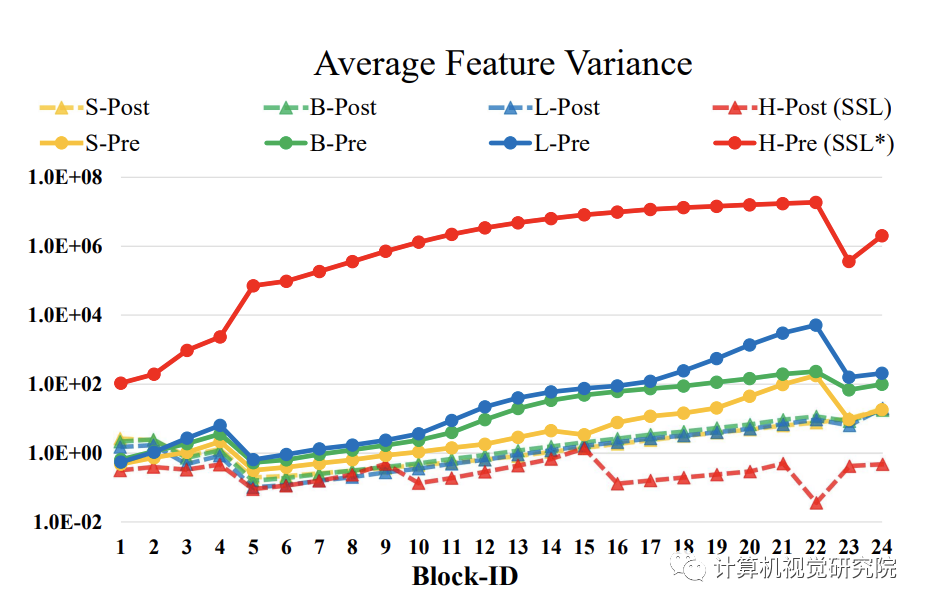
为了稳定深层和浅层的输出,Swin V2 提出了两个方法:
post-norm
post-norm 就是把之前通用ViT中的Transformer block中的Layer Norm层从Attention层前面挪到后面,这么做的好处就是计算Attention之后会对输出进行归一化操作,稳定输出值
cosine similarity
ViT中Transformer block计算Attention是采用dot(Q,K)的操作,在Swin V2中将其替换为了cosine(Q,K)/τ,τ是可学习参数,block之间不共享。cosine自带normalization操作,会进一步稳定Attention输出值
通过post-norm和cosine similarity操作将block的输出稳定在可接受范围内(上图), 帮助模型进行稳定的训练。
模型不适配的问题:
模型不适配主要是图片分辨率和窗口大小的问题,在预训练过程中为了节约训练成本,采用的训练图片分辨率通常比较低(192/224),但是很多下游任务要求的图片分辨率远大于训练分辨率的(1024/1536),这就导致一个问题,将预训练模型迁移到下游任务时为了适配输入图片分辨率势必要改变窗口大小,改变窗口大小就会改变patch数量,改变patch数量就会导致相对位置编码偏置发生变化。
e.g: 8×8 window size 变为 16×16 window size,其相对编码坐标就从[-7,7] --> [-15,15],多出来的位置如何计算相对位置编码?
之前通用的方法是采用二项三次差值,但是效果次优,不够灵活。
为了解决这个问题,Swin V2提出了Continuous relative position bias和Log-spaced coordinates:
Continuous relative position bias:
二项三次差值不够灵活,那就直接上神经网络 ,下图中蓝MLP的位置,Swin V2直接用一个两层的MLP(论文中的Meta network)来自适应生成相对位置偏置,Meta network的输入是△(x)和△(y)在Log-spaced中会讨论这两个的区别。
Log-spaced coordinates:
上面提到的△(x)和△(y)是相对位置编码坐标,在本章开头提到过,patch数量变化之后需要将相对位置编码外推,在例子中的外推率是1.14×,我们希望的是降低这个比率,外推的越小越好,毕竟Meta network没见过外推特别多的输入,为了保证相对位置编码的准确性,需要将外推控制在一个可接受范围内。
这个问题其实就是一个坐标变换,之前的[-7,7] --> [-15.15]是线性变换,那换一个坐标计算方法不就可以解决了吗?于是乎,Log-spaced coordinates出现了,将线性变换转换为了对数变换:
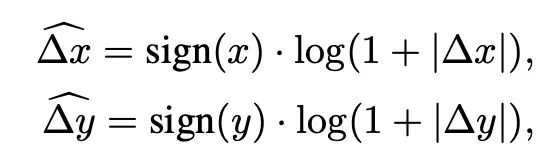
直接截图了,图中公式△(x)hat上面用△(x^)表示的,大家清楚就好了,这里有一个要吐槽的点,公式中的log其实是ln,通过这个公式,带入上面例子的[-7,7] --> [-15.15],就转换为了[-2.079,2.079] --> [-2.773.2.773],外推率降低至0.33×
通过以上的方法解决了模型不够大,不适配的问题,接下来通过实验证明了上述方法的有效性并将预训练模型应用到了其他的下游任务中。
Other Implementation
Implementation to save GPU memory
Zero-Redundancy Optimizer (ZeRO)
Activation check-pointing
Sequential self-attention computation
Joining with a self-supervised approach
04

实验及可视化

目前视觉预训练大多采用的都是图片分类任务带监督的方法(JFT-3B dataset),因为SwinV2-G做到了30亿参数,监督需要的数据量太大,所以论文中采用了监督和无监督相结合的方法来预训练模型:
首先在ImageNet-22K (14M)的基础上进行了数据扩增,扩增五倍,得到了ImageNet-22k-ext (70M)带有噪声标签的数据集(MSRA私有数据集)
为了节约训练成本,以192分辨率图片作为输入,先按照自监督(论文中引用了其他论文的自监督方法,感兴趣的同学自行查阅)的方法在ImageNet-22k-est训练了20个epochs,然后以图片分类任务的形式继续在该数据集上训练30个epochs得到最后的预训练模型,根据不同的下游任务(分割,识别)进行微调
实验的重点主要有两点:
大规模视觉模型(SwinV2-G)能否稳定训练
大规模模型能够带来更好的效果
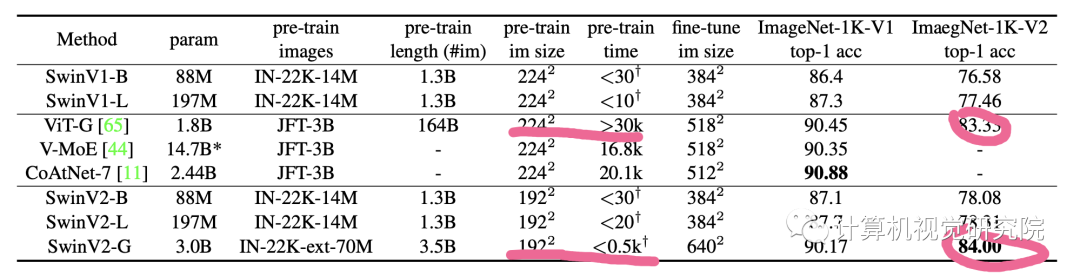
SwinV2-G在ImageNet-1K-V2数据集上得到了最佳结果,相比较于ViT-G预训练图片分辨率更低(预训练消耗更小),时间更短,精度更高。
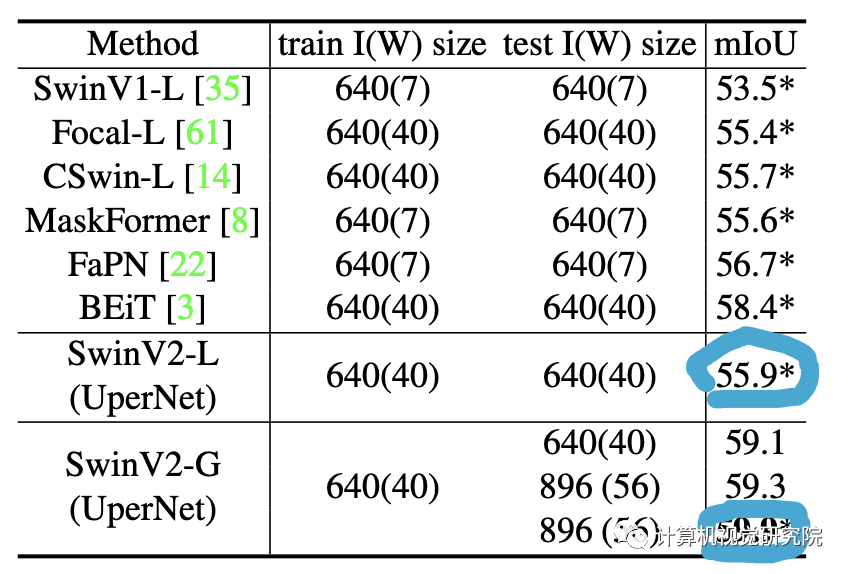
COCO 目标检测
在分类任务与训练之后,将其应用于COCO目标检测、ADE20K语义分割、Kinetics-400视频动作分类都取得了最好结果,在密度视觉识别(目标检测)、像素视觉识别(语义分割)、视频识别(视频动作分类)都实用,证明SwinV2-G可以作为预训练通用模型适配不同的机器视觉任务。
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











